【Python爬虫入门】导出图片和记录信息为表格
下载网站上的图片
用HTTP下载网站图片分三个部分:抓取网页的源代码; 获取图片的超链接; 根据图片的超链接网址下载图片到本地文件夹中。
urllib使用request.urlopen( )打开和读取URL信息,返回的对象response如同一个文本对象,可以调用read( )读取。下面代码将会打印出所采集到的网页html信息:
from urllib import request
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
html = html.decode("utf-8") # decode()命令将网页信息解码,否则乱码
print(html)
关于网页的编码方式查看:使用浏览器查看网页源码,调用开发者工具选择元素或直接按下F12快捷键,只需要找到head标签开始位置的chareset(在某个meta里),就知道网页是采用何种编码了。

网页文件下载到本地,有两种通用方法:一是使用request.urlretrieve( )函数,二是使用Python的文件操作write( )函数写入文件。下面是爬取网站上图片并下载到本地的示例代码:
'''
第一个简单的爬取图片程序,使用Python3.x和urllib库
'''
import urllib.request
import re
import os
def getHtmlCode(url): # 该方法传入url,返回url的html源码
headers = {
'User - Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWEBkIT/537.36(KHTML,like Cecko)Chorme/56.0.2924.87 Mobile Safari/537.36'
}
# Request 函数将url添加头部,模拟浏览器访问
url1 = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(url1).read() # 将url1页面的源代码保存成字符串
page = page.decode('GB2312', 'ignore') # 字符串转码
return page
def getImg(page): # 该方法传入html的源码,经过截取其中的img标签,将图片保存到本机
# 考虑采用https还是http协议
imgList = re.findall(r'(https:[^\s]*?(jpg|png|gif))', page)
x = 100
if not os.path.exists("E:/img1"):
os.mkdir("E:/img1")
for imgUrl in imgList:
try:
print('正在下载: %s' % imgUrl[0])
urllib.request.urlretrieve(
imgUrl[0], 'E:/img1/%d.%s' % (x, imgUrl[1]))
x += 1
except:
continue
if __name__ == '__main__':
url = 'https://www.book123.info/list?key=python' # 搜索无名图书python的网址页面
page = getHtmlCode(url)
# page = urllib.request.urlopen(url).read() # 将url1页面的源代码保存成字符串
# page = page.decode('GB2312', 'ignore') # 字符串转码
# page = getHtmlCode(url)
getImg(page)
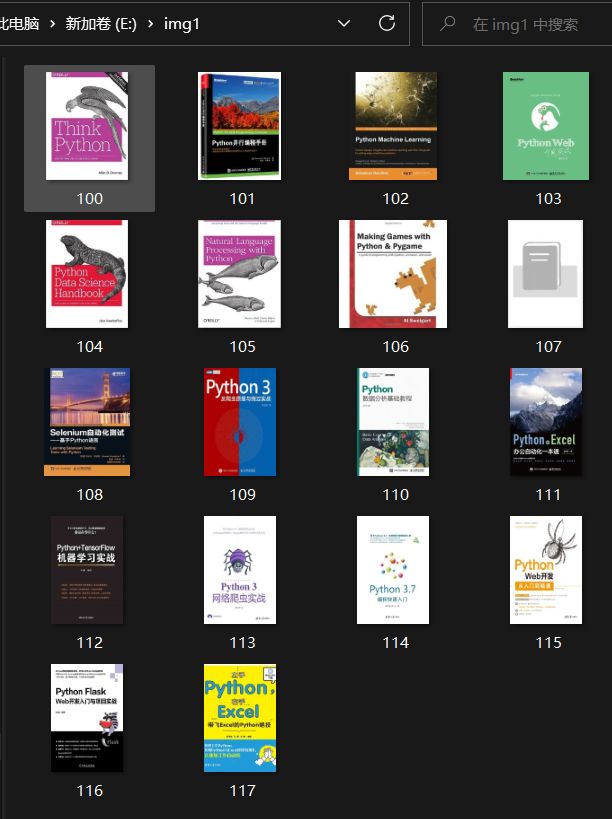
实际上,主流网站均已有一定的反爬虫技术,故此处选取无名图书网这样一个非营利性的网站进行爬取实践。主流网站网站的爬取可能还要进一步调整,如使用cookie技术来完成账号的登录验证等。
提取网站内容记录为表格
由于正则表达式会需要一定时间入门,故了借用第三方库BeautifulSoup,可以根据标签的名称来对网页内容进行截取,此时操作起来会更直观。
BeautifulSoup是一个Python处理HTML/XML的函数库,是Python内置的网页分析工具,用来快速地转换被抓取的网页,提供一些简单的方法及类Python的语法来查找、定位、修改一棵转换后的DOM树。有相应的中文文档可以参考,学习比较友好。
既可以用包含html内容的字符串创建beautifulSoup对象,也可以用本地HTML文件创建,还可以使用网址URL创建,如下使用网址URL创建的过程:
from urllib import request
from bs4 import BeautifulSoup
response = request.urlopen("http://www.baidu.com")
html = response.read()
html = html.decode("utf-8")
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify()) # 格式化输出内容
Beautiful Soup 将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为如下4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag就是HTML中的一个个标签
print(soup.title)
print(soup.head)
NavigableString可以提取标签内部的文字→很简单,用string即可
print(soup.title.string)
BeautifulSoup表示一个文档的全部内容,大部分时候可以把它当作Tag对象,是一个特殊的Tag,下面的代码可以分别获取它的类型、名称和属性。
print(type(soup))
print(soup.name)
print(soup.attrs)
Comment注释对象是一个特殊类型的NavigableString对象,其内容不包括注释符号,如果不好好处理它,可能会对文本处理器造成意想不到的麻烦。
关于.string的说明:如果一个标签中没有标签了,那么,“.string”就会返回标签中的内容。如果标签中只有唯一的一个标签,那么,“.string”也会返回最里面标签的内容。如果tag包含了多个子标签节点,tag就无法确定,.string方法应该调用哪个子标签节点的内容,则“.string”的输出结果是“None”。
采集时为避免被封IP,经常会使用代理。下面展示了一个爬取当当网上书籍信息并写入csv表格的过程:
from bs4 import BeautifulSoup
import requests
import csv
def get_all_books(): # 获取每本书的连接URL
'''
获取该页面所有符合要求的图书的连接
'''
url = 'http://search.dangdang.com/?key=Python&act=input'
book_list = []
r = requests.get(url, timeout=30)
soup = BeautifulSoup(r.text, 'lxml')
book_ul = soup.find_all('ul', {'class': 'bigimg'})
book_ps = book_ul[0].find_all('p', {'class': 'name', 'name': 'title'})
for book_p in book_ps:
book_a = book_p.find('a')
book_url = 'http:'+book_a.get('href') # 对应详细信息的页面链接URL,需要'http:'
book_title = book_a.get('title') # 书名
book_list.append(book_url)
return book_list
def get_information(book_url):
'''
获取每本书籍的信息
'''
print(book_url)
headers = {
'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20200201 Firefox/31.0'}
r = requests.get(book_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
book_info = []
# 获取书籍名称
div_name = soup.find('div', {'class': 'name_info', 'ddt-area': '001'})
h1 = div_name.find('h1')
book_name = h1.get('title')
book_info.append(book_name)
# 获取书籍作者
div_author = soup.find('div', {'class': 'messbox_info'})
span_author = div_author.find('span', {'class': 't1', 'dd_name': '作者'})
book_author = span_author.text.strip()[3:]
book_info.append(book_author)
# 获取书籍出版社
div_press = soup.find('div', {'class': 'messbox_info'})
span_press = div_press.find('span', {'class': 't1', 'dd_name': '出版社'})
book_press = span_press.text.strip()[4:]
book_info.append(book_press)
# 获取书籍价钱
div_price = soup.find('div', {'class': 'price_d'})
book_price = div_price.find('p', {'id': 'dd-price'}).text.strip()
book_info.append(book_price)
return book_info
def main():
header = ['书籍名称', '作者', '出版社', '当前价钱']
# 文件操作
with open('Python_book_info.csv', 'w', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header)
books = get_all_books()
for i, book in enumerate(books):
if i % 10 == 0:
print('获取了{}条信息,一共{}条信息'.format(i, len(books)))
l = get_information(book)
writer.writerow(l)
if __name__ == '__main__':
main()
最后被反爬了,但采集到了信息还是可喜可贺的,说明实践是成功了的。


暑假做了一点爬虫的入门,参照着《Python 爬虫超详细实战攻略》夏敏捷的这本书完成了一些小项目,还是很开心的,故选取部分分享在这里。