整理学习之多任务学习
如果有n个任务(传统的深度学习方法旨在使用一种特定模型仅解决一项任务),而这n个任务或它们的一个子集彼此相关但不完全相同,则称为多任务学习(MTL) 通过使用所有n个任务中包含的知识,将有助于改善特定模型的学习。
单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
多任务学习:把多个相关(related)的任务放在一起学习,同时学习多个任务。

单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的。
多任务学习时,多个任务之间的模型空间(Trained Model)是共享的。
1 基本模型框架
通常将多任务学习方法分为:hard parameter sharing和soft parameter sharing。

1.1 hard parameter sharing
无论最后有多少个任务,底层参数统一共享,顶层参数各个模型各自独立。由于对于大部分参数进行了共享,模型的过拟合概率会降低,共享的参数越多,过拟合几率越小,共享的参数越少,越趋近于单个任务学习分别学习。形象理解为:几个人在一张桌子上吃几盘菜,自己碗里有自己的饭,共享的就是桌子、几盘菜,不共享的就是自己碗里的,桌子上菜越多,自己碗里的越少,吃腻的概率更小;自己碗里一自己的饭,桌子上没几个菜,一会儿饭就吃腻了。
在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现。降低了过拟合的风险。

1.2 soft parameter sharing
每个任务都有自己的模型,自己的参数。

底层共享一部分参数,自己还有独特的一部分参数不共享;顶层有自己的参数。
底层共享的、不共享的参数如何融合到一起送到顶层,也就是研究人员们关注的重点啦。
这里可以放上经典的MMOE模型结构,大家也就一目了然了。
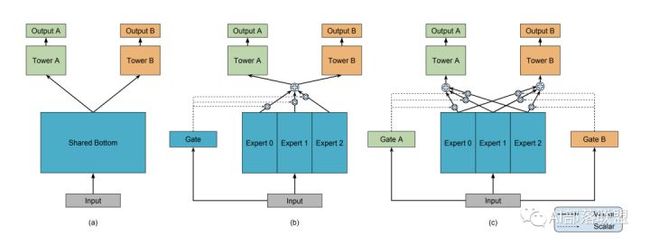
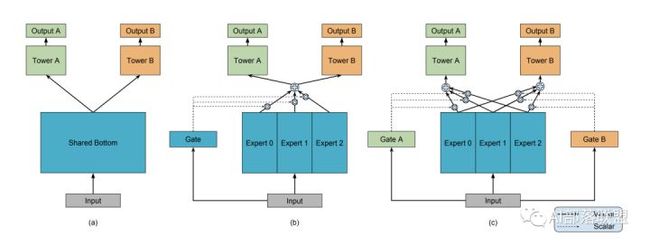
(a)hard sharing(底层参数统一共享,顶层参数各个模型各自独立)
(b)和(c)先对Expert 0-2进行加权求和之后再送入Tower A和B,通过Gate来决定到底加权是多少。(每个expert,Tower A和B,Gate都可以理解为一个隐层神经网络)
(超纲部分:聪明的小伙伴看到这个加权求和,是不是立刻就想到Attention啦?要不咱们把这个Gate改为一种Attention?对不同Expert的Attention来决定求和权重,那你得想办法设计Attention的query啦,是个有趣的点。)
把多个/单个输入送到一个大模型里(参数如何共享根据场景进行设计),预测输出送个多个不同的目标,最后放一起(比如直接相加)进行统一优化。
2 多任务学习改进的方向
我们先假设多个任务适合放在一起,对于这些适合放在一起的任务,我们有哪些方向呢?
2.1模型结构设计:哪些参数共享,哪些参数不共享?
把模型共享参数部分想象成榴莲千层,想象一下我们是竖着切了吃,还是横着一层侧概念拨开了吃。
竖着切了吃
对共享层进行区分,也就是想办法给每个任务一个独特的共享层融合方式。MOE和MMOE模型就是竖着切了吃的例子。另外MMOE在MOE的基础上,多了一个GATE,意味着:多个任务既有共性(关联),也必须有自己的独特性(Task specific)。共性和独特性如何权衡:每个任务搞一个专门的权重学习网络(GATE),让模型自己去学,学好了之后对expert进行融合送给各自任务的tower,最后给到输出。
一层层拿来吃
对不同任务,不同共享层级的融合方式进行设计。如果共享网络有多层,那么通常我们说的高层神经网络更具备语义信息,那我们是一开始就把所有共享网络考虑进来,还是从更高层再开始融合呢?如图6最右边的PLE所示,Input上的第1层左边2个给了粉色G,右边2个给了绿色G,3个都给了蓝色G,然后第2层左边2块给左边的粉色G和Tower,右边两块输出到绿色G和Tower。

2.2 MTL的目标loss设计和优化改进
既然多个任务放在一起,往往不同任务的数据分布、重要性也都不一样,大多数情况下,直接把所有任务的loss直接求和然后反响梯度传播进行优化,是不是不合适呢?
我们需要仔细平衡所有任务的联合训练过程,以避免一个或多个任务在网络权值中具有主导影响的情况。极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势。
假设任务特定权重的优化目标wi和任务特定损失函数Li,通常多任务学习的loss function可以写为:

那么对于共享参数Wsh在梯度下降优化时,使用随机梯度下降来尽量减少上图方程的总目标函数值,对共享层Wshare中的网络权值通过以下规则进行更新:
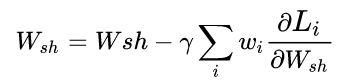
从上图的方程可以看出:
1、loss大则梯度更新量也大;
2、不同任务的loss差异大导致模型更新不平衡的本质原因在于梯度大小;
3、通过调整不同任务的loss权重wi可以改善这个问题;
4、直接对不同任务的梯度进行处理也可以改善这个问题;
Wsh 的优化受到所有loss的影响,那么优化思路自然而然可以为:1、在权重wi上做文章;2、在梯度上做文章。
- loss的权重进行设计,最简单的权重设计方式是人为给每一个任务一个权重;
- 根据任务的Uncertainty对权重进行计算,读者可参考经典的:Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics。
1 数据依赖性(异方差不确定性)依赖于输入数据,模型预测结果的残差的方差即随着数据的输入发生变化;
2、任务依赖性(同方差不确定性)是不依赖于输入数据的任意不确定性,它与模型输出无关,是一个在所有输入数据保持不变的情况下,在不同任务之间变化的量,因此,它可以被描述为与任务相关的不确定性,但是作者并没有详细解释在多任务深度学习中的同方差不确定性的严格定义,而是认为同方差不确定性是由于任务相关的权重引起的。
- 由于不同loss取值范围不一致,可以尝试通过调整loss的权重wi让每个loss对共享Wsh参数贡献平等呢?GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks,以及另外一篇相似思路的文章End-to-end multi-task(希望不同任务loss的量级接近,纳入梯度计算权重,优点是可以考虑loss的量级,缺点是每一步都要额外算梯度)
- learning with attention 提出一种Dynamic Weight Averaging的方法来平衡不同的学习任务。(记录每步的loss,loss缩小快的任务权重会变小,缺点是没有考虑量级)
- Multi-Task Learning as Multi-Objective Optimization对于MTL的多目标优化理论分析也十分有趣,对于MTL优化理论推导感兴趣的同学值得一看。
2.3 直接设计更合理的辅助任务
前面的方法一个要设计网络结构,一个要设计网络优化方式,听起来其实实践上对于很多新手不是很友好,那这里再介绍一个友好的方式!对于MTL优化的一个方向为什么不是找一个更合适的辅助任务呢?只要任务找的好,辅助loss直接加上去,人为设计一下权重调个超参数,模型结构几乎不变都有可能效果更好的!
辅助任务设计的常规思路:
-
找相关的辅助任务!不想关的任务放一起反而会损害效果的!如何判断任务是否想关呢?当然对特定领域需要有一定的了解,比如视频推荐里的:是否点击+观看时长+是否点赞+是否转发+是否收藏等等。
-
对于相关任务不太好找的场景可以尝试一下对抗任务,比如学习下如何区分不同的domain的内容。
-
预测数据分布,如果对抗任务,相关任务都不好找,用模型预测一下输入数据的分布呢?比如NLP里某个词出现的频率?推荐系统里某个用户对某一类iterm的点击频率。
-
正向+反向。以机器机器翻译为例,比如英语翻译法语+法语翻英语,文本纠错任务中也有类似的思想和手段。
-
Pre-train,某种程度上这属于transfer learning,但是放这里应该其实是可以的。比如有一种pretrain的方式是:先train任务A再联合train任务B。预训练本质上是在更好的初始化模型参数,所以想办法加一个帮助初始化模型参数的辅助任务也是可以的。
你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是pre−training。
-
预测一下要做的任务该不该做,句子中的词位置对不对,该不该放这里,点击序列中该不该出现这个iterm?这也是一个有趣的方向。比如文本纠错任务,可不可以先预测一下这个文本是不是错误的呢?
主要参考:
https://zhuanlan.zhihu.com/p/348873723?utm_source=wechat_session&utm_medium=social&utm_oi=1125847523901984769&utm_campaign=shareopn
https://imzhanghao.com/2020/10/25/multi-task-learning/
https://jishuin.proginn.com/p/763bfbd57673
https://zhangkaifang.blog.csdn.net/article/details/89320108?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_antiscanv2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_antiscanv2&utm_relevant_index=1
https://blog.csdn.net/qq_27590277/article/details/115535372