《深入浅出图神经网络》读书笔记(8. 图分类)
文章目录
- 8. 图分类
-
- 8.1 基于全局池化的图分类
- 8.2 基于层次化池化的图分类
-
- 8.2.1 基于图坍缩的池化机制
-
- 1.图坍缩
- 2.DIFFPOOL
- 3.EigenPooling
- 8.2.2 基于TopK的池化机制
- 8.2.3 基于边收缩的池化机制
8. 图分类
对于非规则结构的图数据,之前的固定大小滑窗形式的池化操作不再适用,在图分类中实现层次化池化的机制,是GNN需要解决的基础问题。
8.1 基于全局池化的图分类
读出机制对经过K轮迭代的所有节点进行一次性聚合操作,从而输出图的全局表示:
y = R ( h i ( k ) ∣ ∀ v i ∈ V ) y=R({\pmb h_i^{(k)} |\forall v_i\in V }) y=R(hhhi(k)∣∀vi∈V)
读出机制可以使用MAX、SUM等函数;
还有一种做法是引入一个与所有节点相连的虚拟节点,将全图的表示等价于这个虚拟节点的表示。
注意:损失结构信息;适合小图数据。
8.2 基于层次化池化的图分类
三种方案:
- 基于图坍缩的池化机制:将图划分为不同的子图,然后将子图视为超级节点,从而形成一个坍缩的图。
- 基于TopK的池化机制:对图中的每个节点学习出一个分数,基于这个分数的排序丢弃一些低分数的节点,这类方法借鉴了CNN最大池化的思想:将更重要的信息筛选出来。不同的是图数据种难以实现局部滑窗操作,因此使用分数筛选;
- 基于边收缩的池化机制:边收缩是指并行地将图中的边移除,并将被移除边的两个节点合并,保持它们的连接关系,其思路是通过归并操作来逐步学习图的全局信息的方法。
8.2.1 基于图坍缩的池化机制
1.图坍缩
图G,某种划分得到K个子图 { G ( k ) } k = 1 K \{{G^{(k)}} \}_{k=1}^K {G(k)}k=1K, Γ ( k ) \Gamma^{(k)} Γ(k)表示子图 G ( k ) G^{(k)} G(k)中的节点列表。
簇分配矩阵 S ∈ R N × K S\in R^{N\times K} S∈RN×K,其定义如下: S i j = 1 S_{ij}=1 Sij=1当且仅当 v i ∈ Γ ( j ) v_i\in \Gamma^{(j)} vi∈Γ(j).
S T A S S^TAS STAS的意义:第i个簇与第j个簇的连接强度。
A coar = S T A S A_{\text{coar}}=S^TAS Acoar=STAS
表述了图坍缩之后的超级节点之间的连接强度,其中包含了超级节点自身内部的连接强度,如果只需要考虑超级节点之间的连接强度 A coar [ i , i ] = 0 A_{\text{coar}}[i,i]=0 Acoar[i,i]=0。
采样算子 C ∈ R N × N k C\in R^{N\times N_k} C∈RN×Nk,其定义为: C i j ( k ) = 1 C_{ij}^{(k)}=1 Cij(k)=1,当且仅当 Γ j ( k ) = v i \Gamma_j^{(k)}=v_i Γj(k)=vi.
C是节点在原图和子图中顺序关系的一个指示矩阵。
下采样:
x ( k ) = ( C ( k ) ) T x \pmb x^{(k)}=(C^{(k)})^T\pmb x xxx(k)=(C(k))Txxx
上采样:
x ˉ = C ( k ) x \bar{\pmb x}=C^{(k)}\pmb x xxxˉ=C(k)xxx
邻接矩阵A的划分使用采样算子:
A ( k ) = ( C ( k ) ) T A C ( k ) A^{(k)}=(C^{(k)})^TAC^{(k)} A(k)=(C(k))TAC(k)
这样就可以计算簇内之间的连接关系。
确定簇内节点的融合方法,可以将结果表示为超级节点上的信号。迭代重复上述过程,就能获得越来越全局的图信号。一个实例如下: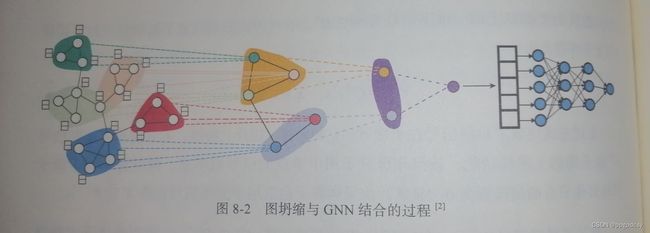
2.DIFFPOOL
首个将图坍缩与GNN结合起来的图层面任务学习的算法。DIFFPOOL提出了一个可学习的簇分配矩阵。具体来说,首先通过一个GNN对每个节点进行特征学习,然后通过另一个GNN为每个节点学习出所属各个簇的概率分布:
Z ( l ) = G N N l , e m b e d ( A ( l ) , H ( l ) ) S ( l ) = softmax ( G N N l , p o o l ( A ( l ) , H ( l ) ) ) H ( l + 1 ) = S ( l ) T Z ( l ) A ( l + 1 ) = S ( l ) T A S ( l ) Z^{(l)}=GNN_{l,embed}(A^{(l)},H^{(l)})\\ S^{(l)}=\text{softmax}({GNN_{l,pool}}(A^{(l)},H^{(l)}))\\ H^{(l+1)}={S^{(l)}}^TZ^{(l)}\\ A^{(l+1)}={S^{(l)}}^TA{S^{(l)}} Z(l)=GNNl,embed(A(l),H(l))S(l)=softmax(GNNl,pool(A(l),H(l)))H(l+1)=S(l)TZ(l)A(l+1)=S(l)TAS(l)
后两个公式被称为DIFFPOOL层,前一个是融合,明显是加和节点特征,后一个是簇间邻接矩阵的计算。
前两个式子是通过GNN学习得到的,学习目的不同,参数不同。
DIFFPOOL有一个非常重要的特性:排列不变性。GCN也是具有排列不变性的,因此上述使用GNN若是GCN,那么节点是否重新排列并不影响节点聚合成簇的结果。
3.EigenPooling
图坍缩使用谱聚类算法来进行划分,基本思路是先将数据变换到特征空间以凸显更好的区分度,然后执行聚类操作(比如选择Kmeans算法进行聚类,此时簇分配就是一种硬分配,保证了稀疏性)。
池化操作选用频谱信息来表示子图信息的统一整合:
假设子图 G ( k ) G^{(k)} G(k)的拉普拉斯矩阵为 L ( k ) L^{(k)} L(k),对应特征向量 u 1 ( k ) , u 2 ( k ) , . . . , u N k ( k ) \pmb u_1^{(k)},\pmb u_2^{(k)},...,\pmb u_{N_k}^{(k)} uuu1(k),uuu2(k),...,uuuNk(k),可以使用上采样算子 C ( k ) C^{(k)} C(k)将该特征向量(子图上的傅里叶基)上采样到整个图:
u ˉ l ( k ) = C ( k ) u l ( k ) \bar {\pmb u}_l^{(k)}=C^{(k)}{\pmb u}_l^{(k)} uuuˉl(k)=C(k)uuul(k)
池化算子 Θ l ∈ R N × K \Theta_l\in R^{N\times K} Θl∈RN×K,我们将所有子图的第 l l l个特征向量按行方向组织起来形成矩阵 Θ l \Theta_l Θl,即:
Θ l = [ u l ( 1 ) , . . . , u l ( k ) ] \Theta_l=[{\pmb u}_l^{(1)},...,{\pmb u}_l^{(k)}] Θl=[uuul(1),...,uuul(k)]
由于子图的节点数量不同,因此特征向量的数量也不同。用 N m a x = max k = 1 , . . . , K N k N_{max}=\max_{k=1,...,K}N_k Nmax=maxk=1,...,KNk表示子图中的最大节点数。然后,若子图 G ( k ) G^{(k)} G(k)的节点数小于 N m a x N_{max} Nmax,可以将 u l ( k ) ( N k < l < N m a x ) \pmb u_l^{(k)}(N_k
池化过程如下:
X l = Θ l T X X_l=\Theta_l^TX Xl=ΘlTX
X l X_l Xl在每个子图第 l l l个特征向量作用下得到的, X l X_l Xl的第k行表示的是第k个超级节点在 Θ l \Theta_l Θl的作用下的表示向量。按照该机制,我们需要设计 N m a x N_{max} Nmax个池化算子进行同样的操作,再进行列方向拼接,结果如下:
X p o o l e d = [ X 0 , . . . , X N m a x ] X_{pooled}=[X_0,...,X_{N_{max}}] Xpooled=[X0,...,XNmax]
具体实例可见下图:

由于低频信息的有效性,取 H < < N max H<
X coar = X p o o k e d = [ X 0 , . . . , X H ] X_{\text{coar}}=X_{pooked}=[X_0,...,X_H] Xcoar=Xpooked=[X0,...,XH]
设全图上的信号为 x \pmb x xxx,有
( u ˉ l ( k ) ) T x = ( u l ( k ) ) T ( C ( k ) ) T x = ( u l ( k ) ) T x ( k ) (\bar {\pmb u}_l^{(k)})^T\pmb x=({\pmb u}_l^{(k)})^T(C^{(k)})^T\pmb x=({\pmb u}_l^{(k)})^T\pmb x^{(k)} (uuuˉl(k))Txxx=(uuul(k))T(C(k))Txxx=(uuul(k))Txxx(k)
其输出表示子图上的信号在子图上对应的第 l l l个特征向量上的傅里叶系数。
8.2.2 基于TopK的池化机制
这是一个不断丢弃节点的过程。具体来说,首先设置一个表示池化率的超参数 k k k, k ∈ ( 0 , 1 ) k\in (0,1) k∈(0,1),接着学习出一个表示节点重要度的值z并并对其进行降序排序,将全图 N N N个节点下采样到 k N kN kN个节点。
i = top − rank ( z , k N ) X ′ = X i , : A ′ = A i , i \pmb i=\text{top}-\text{rank}(\pmb z,kN)\\ X^{'}=X_{i,:}\\ A^{'}=A_{i,i} iii=top−rank(zzz,kN)X′=Xi,:A′=Ai,i
X i , : X_{i,:} Xi,:表示按照向量i的值对特征矩阵进行行切片, A i , i A_{i,i} Ai,i表示按照向量 i \pmb i iii的值对邻接矩阵同时进行行切片和列切片。DIFFPOOL分配同样的问题需要 k N 2 kN^2 kN2的空间复杂度来分配簇信息,而基于Topk的池化机制,每次只需要从原图中丢弃 ( 1 − k ) N (1-k)N (1−k)N的节点即可。
节点重要度的计算:
a.为图分类模型设置一个全局的基向量 p \pmb p ppp,将节点特征向量在该基向量上的投影当作重要度:
z = X p ∣ ∣ p ∣ ∣ \pmb z=\frac{X_{\pmb p}}{||\pmb p||} zzz=∣∣ppp∣∣Xppp
两个作用:
- 可以以投影大小来确定Topk的排序;
- 投影大小还起到了一个梯度门限的作用,投影较小的节点仅有较小的梯度更新幅度,相对地,投影较大的节点会获得更加充分的梯度信息。
z = X p ∣ ∣ p ∣ ∣ , i = top − rank ( z , k N ) X ′ = ( X ⊙ tanh ( z ) ) i , : A ′ = A i , i \pmb z=\frac{X_{\pmb p}}{||\pmb p||},\pmb i=\text{top}-\text{rank}(\pmb z,kN)\\ X^{'}={(X\odot\text{tanh}(\pmb z))}_{i,:}\\ A^{'}=A_{i,i} zzz=∣∣ppp∣∣Xppp,iii=top−rank(zzz,kN)X′=(X⊙tanh(zzz))i,:A′=Ai,i
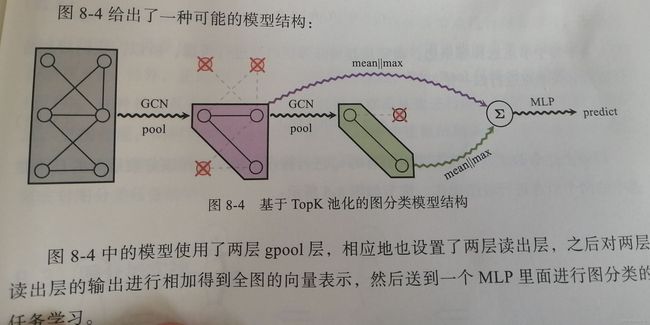
点乘是利用节点的重要度对节点特征做了一次收缩变换,进一步强化了对重要度高的节点的梯度学习。——gpool层。
但是上述做法缺乏对所有节点的有效信息的融合,因此在gpool层后跟一个读出层,实现该尺度下的图全局信息的一次性聚合。具体实现是将全局平均池化和全局最大池化拼接起来:
s = 1 N ∑ i = 1 N x i ′ ∣ ∣ max i = 1 N x i ′ \pmb s=\frac{1}{N}\sum_{i=1}^{N}\pmb x_i^{'}||\max_{i=1}^N \pmb x_i^{'} sss=N1i=1∑Nxxxi′∣∣i=1maxNxxxi′
全图表示,将各层s相加:
s = ∑ l = 1 L s ( l ) \pmb s=\sum_{l=1}^L\pmb s^{(l)} sss=l=1∑Lsss(l)
b.使用一个GNN对节点重要度进行学习,这样能更好地利用图的结构信息对节点的重要度进行学习。
8.2.3 基于边收缩的池化机制
基本思想:迭代式地对每条边上的节点进行两两归并形成一个新的节点,同时保留合并前两个节点的连接关系到新节点上。
存在问题:每个节点有多条边,但是每个节点只能从属于一条边进行边收缩,如何选择?
EdgePool设计了一个边上的分数,根据该分数进行非重复式地挑选与合并。
过程如下:
计算每条边的原始分数:
r i j = w T [ h i ∣ ∣ h j ] + b r_{ij}=\pmb w^T[\pmb h_i||\pmb h_j]+b rij=wwwT[hhhi∣∣hhhj]+b
对原始分数沿邻居节点进行归一化:
s i j = softmax j ( r i j ) s_{ij}=\text{softmax}_j(r_{ij}) sij=softmaxj(rij)
得到上述分数之后,接下来对所有的 s i j s_{ij} sij进行排序,依次选择该分数最高并且未被选中的两个节点进行收缩操作。细节如下:
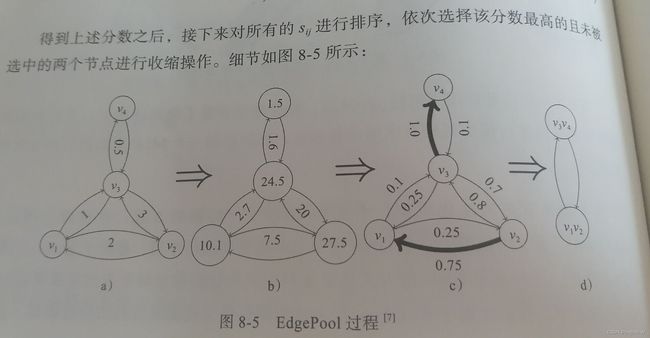
a为原始分数,b为 e r e^r er,c为归一化之后的结果,先合并最高的 v 3 , v 4 v_3,v_4 v3,v4,再合并较高的 v 1 , v 2 v_1,v_2 v1,v2.
合并之后的节点特征可以使用求和的方式:
h i j = s ( h i + h j ) , s = max ( s i j , s j i ) \pmb h_{ij}=s(\pmb h_i+\pmb h_j),s=\max(s_{ij},s_{ji}) hhhij=s(hhhi+hhhj),s=max(sij,sji)
s同样是收缩作用。
oe4-1669389714951)]
a为原始分数,b为 e r e^r er,c为归一化之后的结果,先合并最高的 v 3 , v 4 v_3,v_4 v3,v4,再合并较高的 v 1 , v 2 v_1,v_2 v1,v2.
合并之后的节点特征可以使用求和的方式:
h i j = s ( h i + h j ) , s = max ( s i j , s j i ) \pmb h_{ij}=s(\pmb h_i+\pmb h_j),s=\max(s_{ij},s_{ji}) hhhij=s(hhhi+hhhj),s=max(sij,sji)
s同样是收缩作用。
这种方法节点的融合都是从边进行的,契合了图的结构信息;保留了融合之后图中连接的稀疏性,空间复杂度低;作为一种端到端的池化机制,可以广泛地整合到各个GNN模型中,以完成图分类任务的学习。