`bert.py`
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 32 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
`bert_CNN.py`
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128//4 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.hidden_size)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc_cnn = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = encoder_out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc_cnn(out)
return out
`bert_DPCNN.py`
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128//4 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.num_filters = 250 # 卷积核数量(channels数)
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
# self.fc = nn.Linear(config.hidden_size, config.num_classes)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.hidden_size), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
x = encoder_out.unsqueeze(1) # [batch_size, 1, seq_len, embed]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze() # [batch_size, num_filters(250)]
x = self.fc(x)
return x
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
x = x + px # short cut
return x
`bert_RCNN.py`
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128//4 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
self.rnn_hidden = 256
self.num_layers = 2
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.rnn_hidden * 2 + config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out, _ = self.lstm(encoder_out)
out = torch.cat((encoder_out, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze()
out = self.fc(out)
return out
`bert_RNN.py`
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128//4 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
self.dropout = 0.1
self.rnn_hidden = 768
self.num_layers = 2
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.dropout = nn.Dropout(config.dropout)
self.fc_rnn = nn.Linear(config.rnn_hidden * 2, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out, _ = self.lstm(encoder_out)
out = self.dropout(out)
out = self.fc_rnn(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
`ERNIE.py`
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'ERNIE'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128//4 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './ERNIE_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
print(self.tokenizer)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
`utils.py`
# coding: UTF-8
import torch
from tqdm import tqdm
import time
from datetime import timedelta
PAD, CLS = '[PAD]', '[CLS]' # padding符号, bert中综合信息符号
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
# print(lin)
if not lin:
continue
label, content = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, test
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
`train_eval.py`
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from pytorch_pretrained.optimization import BertAdam
# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if len(w.size()) < 2:
continue
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
pass
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
# optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
optimizer = BertAdam(optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
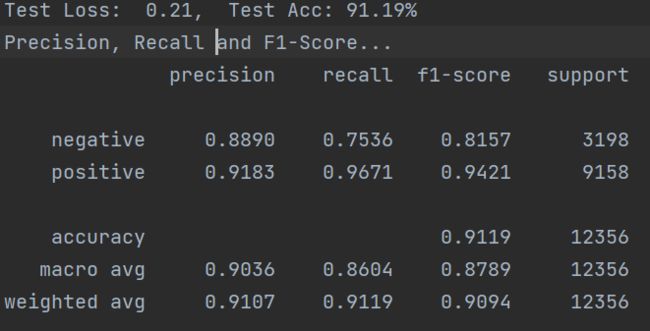
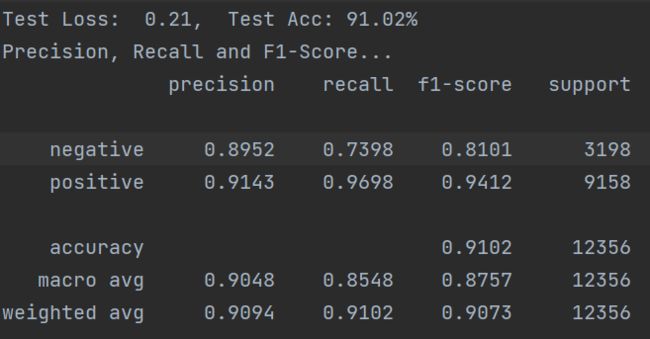
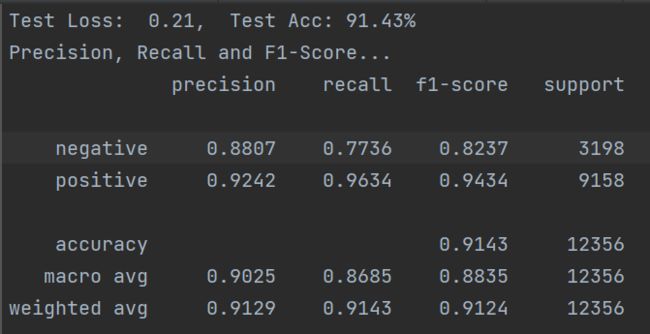
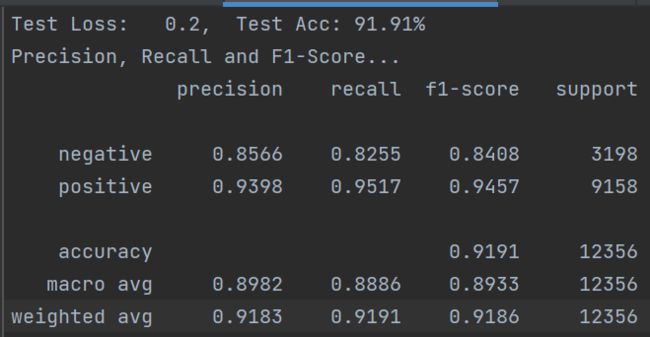
原paper为新闻公开数据集,本实验数据为个人独立收集,整理,使用自己的数据集,加载BERT/ERNIE预训练模型,实际微调效果都非常好!