【论文阅读】Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction
《Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction》
论文来源:EMNLP2020
论文链接:https://arxiv.org/abs/1911.09419
论文代码:GitHub - MIRALab-USTC/KGE-HAKE: The code of paper Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. Zhanqiu Zhang, Jianyu Cai, Yongdong Zhang, Jie Wang. AAAI 2020.
主要任务:知识图谱表示学习,即将知识库中的实体关系表示为低维向量,可以用于链接预测(也称知识图谱补全)任务。
介绍
现有的知识图谱嵌入模型主要集中在对称/反对称、翻转、组合(symmetry/antisymmetry, inversion, and composition)等关系模式的建模上。然而,许多现有的方法无法对语义层次(semantic hierarchies)进行建模,语义层次在实际应用中很常见。针对这一挑战,本文提出了一种新的知识图谱嵌入模型,即层次感知知识图谱嵌入(Hierarchy-Aware Knowledge Graph Embedding,HAKE),它将实体映射到极坐标系中。HAKE的灵感来自于这样一个事实:极坐标系中的同心圆可以自然地反映层次结构。具体地说,径向坐标旨在建模层次结构中不同level的实体,半径较小的实体应位于较高的level;角度坐标旨在区分层次结构中同一level的实体,这些实体的半径大致相同,但角度不同。实验表明,HAKE能有效地对知识图中的语义层次结构进行建模,在链路预测任务中,其在基准数据集上的性能明显优于现有的SOTA方法。
现有知识图嵌入模型的成功很大程度上依赖于它们对关系的关联模式进行建模的能力,例如对称性/反对称性、翻转和组合。例如,将关系表示为翻译的TransE可以对翻转和合成模式进行建模。DistMult模拟了头实体、关系和尾部实体之间的三方交互作用,可以对对称关系进行建模。RotatE将实体表示为复杂空间中的点,将关系表示为旋转,可以对包括对称/反对称、反转和组合的关系模式进行建模。然而,现有的许多模型无法对知识图中的语义层次进行建模。语义层次是什么呢?语义层次是知识图谱中普遍存在的一种性质。举个例子,WordNet中包含三元组[arbor/cassia/palm,hypernym,tree],其中“树”在层次结构中比“乔木/决明子/棕榈树”更高。Freebase包含三元组[England,/location/location/contains,Ponte-fract/Lancaster],其中“Pontefract/Lancaster”在层次结构中的级别低于“England”。尽管有一些工作考虑到了层次结构,但他们通常需要额外的数据或过程来获取层次结构信息。因此,寻找一种能够自动有效地对语义层次进行建模的方法仍然是一个挑战。
本文提出了一种新的知识图谱嵌入模型,即层次感知知识图谱嵌入(HAKE)。为了对语义层次进行建模,HAKE需要区分实体为两类:(a)层次结构中的不同level;(b)层次结构的同一level。受具有层次属性的实体可以看作树这一事实的启发,我们可以使用节点(实体)的深度来建模层次结构的不同level。因此,我们使用模信息来对类别(a)中的实体进行建模,因为模的大小可以反映深度。在上述设置下,类别(b)中的实体将具有大致相同的模量,这很难区分。受同一个圆上的点可以具有不同的相位这一事实的启发,我们使用相位信息来对类别(b)中的实体进行建模。结合模量和相位信息,HAKE将实体映射到极坐标系中,其中径向坐标对应于模量信息,角坐标对应于相位信息。实验表明,我们提出的HAKE模型不仅能清晰地区分实体的语义层次,而且在基准数据集上的性能明显优于几种最新的方法。
相关工作
- 翻译模型:
 的思想
的思想 - 双线性模型:基于乘积的评分函数,以匹配隐含在其向量空间表示中的实体和关系的潜在语义。如RESCAL、DistMult、ComplEx、HolE等
- 基于神经网络的模型:引入卷积神经网络ConvE和ConvKB,最近图神经网络也被引入知识表示模型。
本文提出的模型属于翻译距离模型,与RotatE有相似性,都使用模量和相位信息。主要不同是:
- 目的不同。RotatE旨在对关系模式进行建模,包括对称/反对称、翻转和组合。HAKE的目标是对语义层次进行建模,同时也可以对上述所有关系模式进行建模。
- 使用模信息的方法是不同的。RotatE将关系建模为复空间中的旋转,这鼓励两个连接的实体具有相同的模量,无论这种关系是什么。RotatE中的不同模量来源于训练的不准确。相反,HAKE显式地建模了模量信息,这在区分不同层次的实体方面明显优于RotatE。
几种知识图谱表示学习方法的对比:

建模层次结构的方法
另一个相关的问题是如何在知识图谱中建立层次结构模型。最近的一些研究以不同的方式考虑这个问题。Li et al.(2016)将实体和类别联合嵌入语义空间,并为概念分类和无数据分层分类任务设计模型。Zhang等人(2018)使用聚类算法对层次关系结构进行建模。Xie,Liu,Sun(2016)提出了将类型信息嵌入到知识图嵌入中的TKRL。也就是说,TKRL需要实体的附加层次结构类型信息。
与以前的工作不同,我们的工作
(a) 考虑了链路预测任务,这是一个比较常见的知识图嵌入任务;
(b) 可以自动学习知识图中的语义层次,而不需要使用聚类算法;
(c) 除了知识图中的三元组外,不需要任何其他信息。
本文提出的HAKE算法
两类实体
为了对知识图谱的语义层次进行建模,知识图嵌入模型必须能够区分以下两类实体。
(a) 层次结构中不同level的实体。例如“哺乳动物”和“狗”,“跑”和“移动”。
(b) 处于层次结构中同一level的实体。例如,“玫瑰”和“牡丹”,“卡车”和“货车”。
Hierarchy-Aware Knowledge Graph Embedding
为了对上述两个类别进行建模,本文提出了一个层次感知的知识图嵌入模型-HAKE。HAKE由两部分组成:模部分和相部分,分别针对两个不同类别的实体进行建模。图1给出了模型的说明。
为了区分不同部分的嵌入,我们用 (e可以是h或t)和
(e可以是h或t)和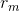 表示模部分的实体嵌入和关系嵌入,用
表示模部分的实体嵌入和关系嵌入,用 (e可以是h或t)和
(e可以是h或t)和![]() 表示相部分中的实体嵌入和关系嵌入。
表示相部分中的实体嵌入和关系嵌入。
模部分
模部分旨在为层次结构的不同level上的实体建模。受具有层次属性的实体可以看作树这一事实的启发,我们可以使用节点(实体)的深度来建模层次结构的不同level。因此,我们使用模信息来建模类别(a)中的实体,因为模可以反映树的深度。具体的,本文把 和
和![]() 的每个元素,也就是
的每个元素,也就是![]() 和
和![]() ,视为一个模量,把的每个元素
,视为一个模量,把的每个元素![]() 作为两个模量之间的缩放变换,模部分的公式就可以这样定义:
作为两个模量之间的缩放变换,模部分的公式就可以这样定义:
![]()
对应的距离函数是:
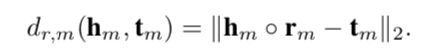
允许实体嵌入包含负值,限制关系嵌入的元素只能为正。这是因为实体嵌入的符号可以帮助我们预测两个实体之间是否存在关系。例如,如果h和t1之间存在关系r,而h和t2之间没有关系,则(h,r,t1)是正样本,(h,r,t2)是负样本。本文的目标是最小化![]() 并最大化
并最大化![]() ,以便区分正负两类样本。对于正样本,
,以便区分正负两类样本。对于正样本,![]() 和
和![]() 往往是符号相同的,就像
往往是符号相同的,就像![]() 一样是大于0的。对于负样本,如果我们随机初始化符号的话,
一样是大于0的。对于负样本,如果我们随机初始化符号的话,![]() 和
和![]() 的符号可以是不同的。这样的话,
的符号可以是不同的。这样的话,![]() 更可能会比
更可能会比![]() 大一些,正好是我们想要的效果。
大一些,正好是我们想要的效果。
此外,我们可以期望层次结构中较高level的实体具有较小的模数,因为这些实体更接近树的根。如果我们只使用模部分嵌入知识图,那么类别(b)中的实体将具有相同的模。此外,假设r是一个反映相同语义层次的关系,那么![]() 将趋向于1,因为对于所有的h,h◦r◦r=h。所以,类别(b)中的实体嵌入趋于相同,这就难以区分这些实体。因此,需要一个新的模块来对类别(b)中的实体进行建模。
将趋向于1,因为对于所有的h,h◦r◦r=h。所以,类别(b)中的实体嵌入趋于相同,这就难以区分这些实体。因此,需要一个新的模块来对类别(b)中的实体进行建模。
相位部分
相位部分的目的是在语义层次的同一level上对实体进行建模。受同一个圆上的点(即具有相同的模)可以具有不同的相位这一事实的启发,我们使用相位信息来区分类别(b)中的实体。具体的,我们把 和
和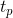 的每个元素,也就是
的每个元素,也就是![]() 和
和![]() 作为一个相位,把
作为一个相位,把![]() 作为一个相位变换。相位部分的公式就可以这样定义:
作为一个相位变换。相位部分的公式就可以这样定义:

对应的距离函数是:
![]()
sin()是对输入向量的每个元素做正弦函数的操作。注意,我们使用正弦函数来测量相位之间的距离,而不是使用![]() ,因为相位具有周期性特征。该距离函数与pRotatE的公式相同。
,因为相位具有周期性特征。该距离函数与pRotatE的公式相同。
结合模部分和相位部分,HAKE将实体映射到极坐标系中,其中径向坐标和角坐标分别对应于模部分和相位部分。也就是说,HAKE把一个实体h映射为![]() ,和分别由模部分和相位部分生成,然后拼接在一起。显然,
,和分别由模部分和相位部分生成,然后拼接在一起。显然,![]() 是极坐标系中一个2D的点坐标。具体把HAKE公式定义如下:
是极坐标系中一个2D的点坐标。具体把HAKE公式定义如下:

HAKE的距离函数是:
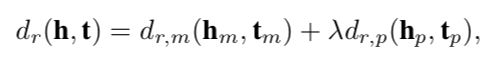
 是模型学习的参数。相应的得分函数为:
是模型学习的参数。相应的得分函数为:

但两个实体有相同的模,模部分的距离为0.相位部分的可能非常大。通过结合模部分和阶段部分,HAKE可以对类别(a)和类别(b)中的实体进行建模。因此,HAKE可以对知识图的语义层次进行建模。
在评估模型时,我们发现在![]() 中加入混合偏差(mixture bias)有助于提高HAKE的性能。修正的
中加入混合偏差(mixture bias)有助于提高HAKE的性能。修正的![]() 由下式得出:
由下式得出:
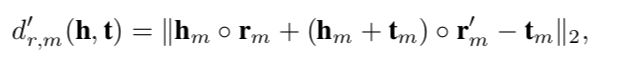
其中![]() 是和维度相同的向量。实际上上式距离函数和下式等价:
是和维度相同的向量。实际上上式距离函数和下式等价:

其中/表示元素级别的除法操作。如果我们让![]() ,这样修正过的距离函数就跟原始的距离函数一致了。
,这样修正过的距离函数就跟原始的距离函数一致了。
损失函数
为了训练模型,我们使用负采样损失函数和自我对抗训练(Sun等人,2019年):

 是一个固定的margin,
是一个固定的margin, 是sigmoid函数,
是sigmoid函数,![]() 是第i个负样本。另外,采样的负三元组的概率分布:
是第i个负样本。另外,采样的负三元组的概率分布:

实验与分析
有人可能会说相位部分是不必要的,因为我们可以通过允许![]() 为负来区分类别(b)中的实体。因此本文提出了一种模型ModE只使用模数部分,但允许
为负来区分类别(b)中的实体。因此本文提出了一种模型ModE只使用模数部分,但允许![]() <0。
<0。
主要结果
本文模型HAKE、ModE和baseline models对比的情况:

HAKE在所有数据集上都超过了SOTA的效果。
在WN18RR和YAGO3-10数据集中,有比较明显的层次结构,所以本文的方法提升比较多。FB15K-237的关系类型更为复杂,有很多关系没有层次结构,因此相对于另外两个数据集,它的提升小一些。这也显示了,只要知识图谱中有语义的层次结构,本文的方法就会带来一定的提升。
关系嵌入的分析
在这一部分中,首先证明了HAKE可以通过分析关系嵌入的模来有效地建模层次结构。然后,通过分析关系嵌入的相位,说明HAKE的相位部分可以帮助区分层次结构中同一level的实体。在图2中绘制了六种关系的模分布直方图。这些关系来自WN18RR、FB15k-237和YAGO3-10。具体地说,图2a、2c、2e和2f中的关系来自WN18RR。图2d中的关系来自FB15k-237。图2b中的关系取自YAGO3-10。我们将图2中的关系分为三组。
(A) 图2c和2d中的关系将语义层次结构的同一level的实体连接起来;
(B) 图2和图2中的关系表示尾实体在层次结构中比头实体处于更高的级别;
(C) 图2和图2中的关系表示尾实体在层次结构中比头实体处于更高的级别;

如模型描述部分所述,我们假设层次结构中更高level的实体具有较小的模值。实验验证了我们的期望。对于ModE和HAKE,组(A)中关系嵌入的大多数的元素都取1左右的值,这导致头部实体和尾部实体具有大致相同的模。在组(B)中,大多数关系条目的值都小于1,这导致头实体的模小于尾实体。组(C)与组(B)的情况相反。这些结果表明,我们的模型能够捕捉到知识图谱中的语义层次。此外,与ModE相比,HAKE的关系嵌入模具有更低的方差,这表明HAKE可以更清晰地对层次结构进行建模。
如上所述,组(A)中的关系反映了相同的语义层次,并且预期具有大约1的模值。显然,仅用模部分很难区分由这些关系连接的实体。在图3中,我们绘制了组(A)中关系的相位。结果表明,由于许多相具有π值,同一层次上的实体可以用它们的相来区分。
实体嵌入的分析
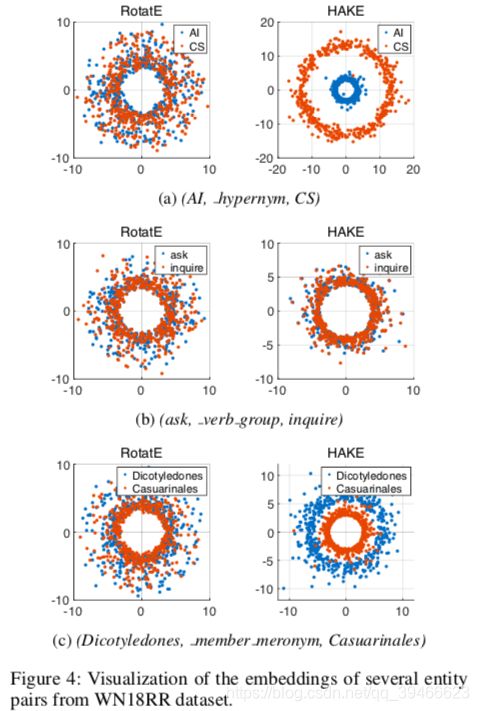
在这一部分中,为了进一步说明HAKE可以捕获实体之间的语义层次结构,可视化了几个实体对的嵌入。本文绘制了两个模型的实体嵌入:先前的SOTA模型RotatE和本文提出的HAKE。RotatE将每个实体视为一组复数。由于复数可以看作是二维平面上的一个点,因此我们可以在二维平面上绘制实体嵌入。至于HAKE,我们已经提到它将实体映射到极坐标系中。因此,我们也可以根据它们的极坐标在二维平面上绘制由HAKE生成的实体嵌入。为了公平比较,我们将k=500。也就是说,每个图包含500个点,实体嵌入的实际尺寸为1000。注意,我们使用对数标度来更好地显示实体嵌入之间的差异。由于所有的模量值都小于1,在应用对数运算后,图中较大的半径实际上表示较小的模量。
图4显示了WN18RR数据集中三个三元组的可视化结果。与尾实体相比,图4a、4b和4c中的头实体在语义层次上分别处于较低水平、相似水平和较高水平。可见,HAKE的可视化结果中存在明显的同心圆,说明HAKE能够有效地对语义层次进行建模。然而,在RotatE中,在所有三个子图中的实体嵌入是混合的,这使得在层次结构中不同级别的实体很难区分。
消融实验
在这一部分中,对HAKE的模量部分和相位部分以及混合偏差进行了消融实验。表4显示了三个基准数据集的结果:
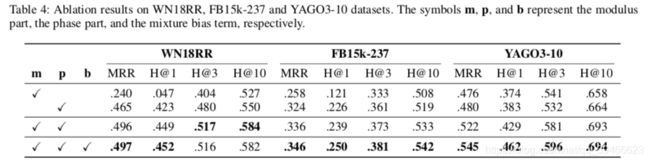
我们可以看到,混合偏差几乎可以改善HAKE在所有指标上的性能。还观察到,HAKE的模部分在所有数据集上都不是性能很好,因为它无法在层次结构的同一level上区分实体。当只使用相位部分时,HAKE退化为pRotatE模型(Sun等人,2019)。它的性能优于模数部分,因为它可以很好地在层次结构中同一level上对实体进行建模。然而,本文的HAKE模型在所有数据集上的表现明显优于模部分和相位部分,这说明了将这两部分结合起来对知识图谱中的语义层次进行建模的重要性。