课程向:深度学习与人类语言处理 ——李宏毅,2020 (P28-1)
Self-Supervised Learning for Speech
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
考虑到部分英文术语的不易理解性,因此笔记尽可能在标题后加中文辅助理解,虽然这样看起来会乱一些,但更好读者理解,以及文章内部较少使用英文术语或者即使用英文也会加中文注释,望见谅
深度学习与人类语言处理 P28-1 系列文章目录
- Self-Supervised Learning for Speech
- 前言
- I Self-Supervised Learning for Speech 自监督学习在语音中的应用
-
- 1.1 Self-supervised with Supervised 自监督与监督学习
- 1.2 Introduction 概述
- 1.3 CPC 第一大类自监督学习模型
-
- 1.3.1 wav2vec 语音辨识
- 1.3.2 Bidir CPC 双向CPC
- 1.3.3 Modified CPC 改良版CTC
- 1.4 APC 第二大类自监督学习模型
-
- 1.4.1 Multi-Target APC 多目标APC
- 1.4.2 DeCoAR 结合EMLO的APC
- 1.4.3 Autoencoder & Phase 架构seq2seq
- 1.4.4 Audio2Vec
前言
在上两篇P26 和 上一篇P27,我们进入了 Parsing 句法分析任务,
在P26中讲解了
Constituency Parsing 成分句法分析:把句子组织成短语的形式;我们学习到了 Constituency Parsing 成分句法分析将讲解任务的基本概念、训练目标以及常用的两种解法,和深度学习在这些解法中的使用。
在P27中讲解了
Dependency Parsing 依存句法分析:找出句子中词的依赖关系;我们学习到了 Dependency Parsing 依存句法分析:找出句子中词的依赖关系。我们将学到依存句法分析的基本概念:关系、依存句法树和抽象化的训练任务,以及与成分句法分析类似的方法等。
本篇P28-1,我们将学习过去自监督学习在语音中的应用,主要分为两大类:CPC和APC,两类是根据不同的损失函数划分的。在下一半篇P28-2中将讲解BERT在语音中如何自监督使用。
I Self-Supervised Learning for Speech 自监督学习在语音中的应用
1.1 Self-supervised with Supervised 自监督与监督学习

对于ASR语音辨识系统,传统的有监督学习,我们都是通过一段语音和它的文字标签进行有监督学习,这时就需要人工收集大量的成对数据资料。而如果我们能用自监督学习的方法来辅助训练的话,不仅不再需要那么多成对数据,并且还能提高模型效果。
和文字中的预训练模型一样,如BERT,我们在语音辨识系统上也可以使用预训练模型,这个预训练模型完全可以通过大量无标注数据训练而来,而在具体语音任务上进行微调。
接下来,我们将讲解所有的自监督学习在语音上的应用和模型。
1.2 Introduction 概述

自监督学习在语音上的模型主要有两大类,这两大类是根据不同的损失函数决定的:
CPC,Contrastive Predictive Losses 预测的损失值
APC,Reconstruction Losses 重构的损失值
1.3 CPC 第一大类自监督学习模型

具体训练过程如上图,首先用一个由CNN组成的Encoder对每个frame声音段进行编码成一个向量,紫色矩形。然后在t时刻将 x t x_t xt之前的和 x t x_t xt的向量一一输入到GRU中,得到GRU最后一层的结果 C t C_t Ct,橙色矩形。将 C t C_t Ct 与 x t x_t xt后面的向量$如x_{t+1} $等进行两两判断,判断两者是否是同一段语音里的,二分类任务,我们会在训练开始前对语音的部分片段进行噪音处理,如替换等,而判断的目标就是找出这些噪音,也就是如果是不同的语音或者同一个语者但讲不同的话,就希望两者在向量空间中越远越好。
而这个 C t C_t Ct就可以当作预训练模型使用。
1.3.1 wav2vec 语音辨识

早期的CPC并没有用在ASR语音辨识上,因为CPC的训练目标仅仅是对 C t C_t Ct和 x t + 1 x_{t+1} xt+1等进行两两的分类而已。因此,FaceBook提出了一种模型wav2vec,它就是上述的CPC模型,不过它的训练目标改为通过 C t C_t Ct去预测 x t + 1 x_{t+1} xt+1等的文字。
1.3.2 Bidir CPC 双向CPC

在考虑到CPC模型都是单向的,DeepMind提出CPC后,又提出了双向的CPC,如上图,且双向的Encoder参数是共享的,很像文字版的ELMO。
1.3.3 Modified CPC 改良版CTC

最后一种CPC便是改良版CTC,它是在原有CTC基础上进行三种改良:
- 将batch normalization 改成 channel-wise normalization
- 将预测层是线性层 改成 Transformer 层
- 将GRU网络结构 改成 LSTM
1.4 APC 第二大类自监督学习模型

APC的想法就更简单了,与文字版的语言模型一样,只不过文字是一个接一个预测token。而APC是一段frame语音段预测下一段语音段,也就根据过的语音段来预测还原下一时刻的语音段,因此损失函数是重构损失函数,语音版的语言模型。
1.4.1 Multi-Target APC 多目标APC
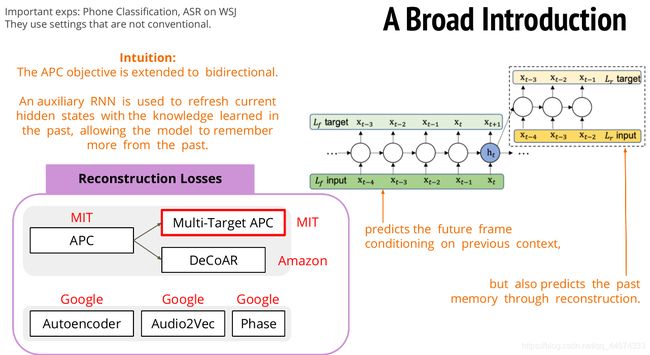
多目标APC,是在原有APC基础上进行增加预测目标,原有APC都是根据 x t x_t xt及其之前的向量去预测 x t + 1 x_{t+1} xt+1。而多目标APC会根据 x t x_t xt及其之前的向量去预测过去的向量,如 x t − 4 x_{t-4} xt−4,并一直反向预测直到 x t − 1 x_{t-1} xt−1。
1.4.2 DeCoAR 结合EMLO的APC
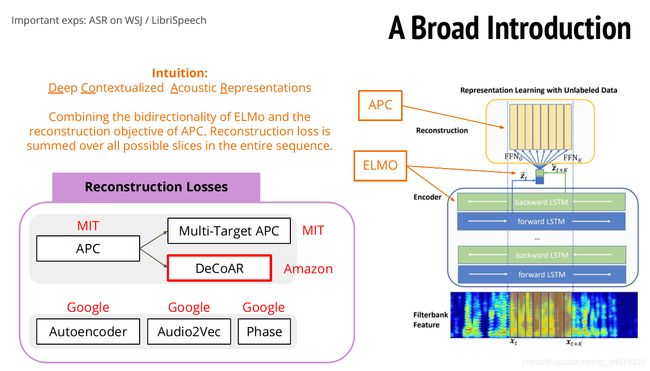
DeCoAR 其实就是把APC和EMLO两个模型组合在一起,具体做法是同样输入语音向量序列,经过双向LSTM可以得到两个,前向和后向的隐藏层向量,将这两个向量像ELMO一样组合在一起。再通过组合好的向量一次还原一个窗口大小的frame语音向量,在训练时就是从t=0依次还原一个窗口的语音向量,最终还原整个输入的语音向量序列。
1.4.3 Autoencoder & Phase 架构seq2seq
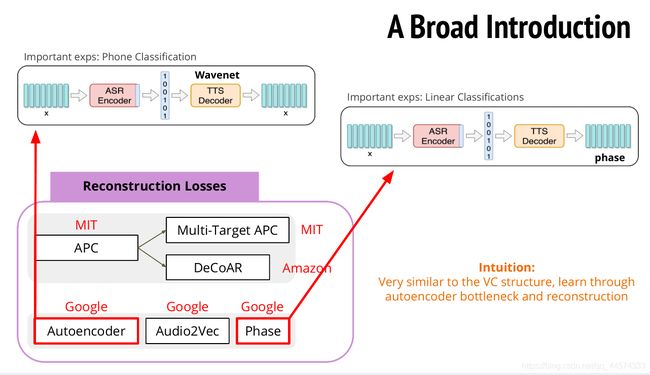
与上述APC损失函数相同,还有不同的三种方法,先讲前两种:Autoencoder 和 Phase 方法,两者的方法类似。
Autoencoder就是将语音向量序列x,经过Encoder得到隐藏层向量,再通过一个Decoder Wavenet还原这个隐藏层向量到原语音向量,训练目标就是最小化输入和输出的差别。而Phase方法还原的不再是整个语音向量,而是phase。
这个由Encoder得到的隐藏层向量就可以作为后续任务的预训练模型使用。
1.4.4 Audio2Vec

对于我们熟悉的Word2Vec有两种:CBOW和Skip-ngram,Audio2Vec就是语音版本的Word2Vec,CBOW看过去和未来的frame语音段去预测中间的frame语音段;Skip-ngram就是由中间的frame语音段去预测周围的frame。
值得注意的是,Audio2Vec还加了一个新的任务,就是随机取出两段frame语音段,去预测这两段语音段的时间差,这个任务被称为Temporal gap。
至此,CPC和APC两大类自监督学习模型在语音上的应用已结束。
而其实,还有另外的一大类,BERT类,BERT不仅在可应用在文字上表现出色,在语音方面也有一定的优秀效果。