pytorch-多分类 、 全连接层
多分类
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms#导入数据集
batch_size = 200 #一次输入200次图片
learning_rate = 0.01 #学习率0.01
epochs = 10 #迭代10次
#导入数据,训练数据,测试数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data',train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data',train=False,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size, shuffle=True)
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
#w1:[200,784],b1:[200,] 记录梯度信息
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
#w2:[200,784],b1:[200,] 记录梯度信息
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
#w3:[200,784],b1:[200,] 记录梯度信息
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
#初始化w1 w2 w3
#前向传播
#前向传播 y=wx+b
def forward(x):
x = x@w1.t() + b1#x:[batchsize,784] w1:[200,784] 转置[784,200]
#输出x:[batchsize,200]
x = F.relu(x)
x = x@w2.t() + b2
# 输出x:[batchsize,200]
x = F.relu(x)
x = x@w3.t() + b3
# 输出x:[batchsize,10]
x = F.relu(x)
return x
optimizer = optim.SGD([w1,b1,w2,b2,w3,b3], lr=learning_rate)#SGD 随机梯度下降方法优化参数
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data,target) in enumerate(train_loader):
data = data.view(-1,28*28)#数据维度适应
logits= forward(data)#前向传播
loss=criteon(logits,target)#损失函数
optimizer.zero_grad()#自动推理
loss.backward()
#print(w1.grad.norm(), w2.grad.norm())
optimizer.step()#梯度更新
if batch_idx % 100 ==0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data,target in test_loader:#测试结果,统计识别率
data = data.view(-1, 28*28)
logits = forward(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f}, Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
导致loss变化缓慢的原因:
"""
1.梯度离散
2.学习率过大
3.权重不合适
"""
结果
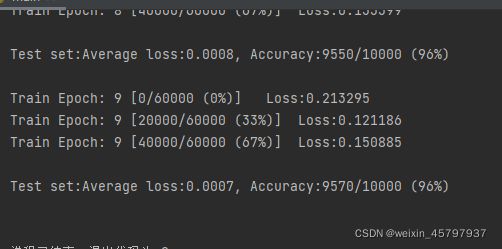
全连接层
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms#导入数据集
batch_size = 200 #一次输入200次图片
learning_rate = 0.01 #学习率0.01
epochs = 10 #迭代10次
#导入数据,训练数据,测试数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data',train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data',train=False,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):#多层感知机
def __init__(self):
super(MLP, self).__init__()
#新建神经网络,1->,[784,200] 2->[200,200] 3->[200,10]
self.model = nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x =self.model(x)#调用model.权重计算
return x
net = MLP()#构造感知机
optimizer = optim.SGD(net.parameters(), lr = learning_rate)#设定优化函数学习率
criteon = nn.CrossEntropyLoss()#设置交叉熵损失函数
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):#batch_idx*batch_size=train_loader
data = data.view(-1, 28*28)#适应维度
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()#反向传播
optimizer.step()#逐步优化
if batch_idx % 100 ==0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data , target in test_loader:
data = data.view(-1, 28*28)
logits = net(data)
test_loss +=criteon(logits, target).item()#损失函数叠加值
#torch.max()[0], 只返回最大值的每个数
#torch.max()[1], 只返回最大值的每个索引
pred = logits.data.max(1)[1]#按照第1个维度(行)最大值,即每一个样本(每一行)概率的最大值.[1]是指返回最大值的索引,即返回0或1
correct += pred.eq(target.data).sum()#统计识别的数量
test_loss /= len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f}, Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
结果:
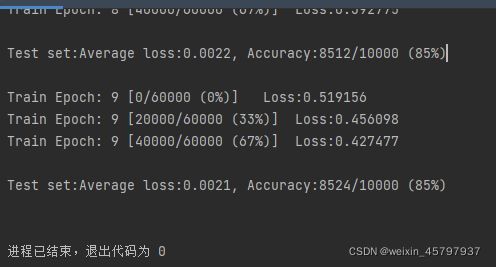
心得
训练流程:
1.导入必要的库
2.设置好需要的参数
3.导入数据同时分好训练数据、测试数据
4.创建需要的模型,比如全连接
5.创造网络,设置优化器参数和损失函数
6.循环训练,对于加载的数据进行标签化,对数据data设置一个合适的维度,将数据传入全连接层中,计算传入数据与目标之间的损失函数,优化器梯度清零,损失函数反向传播,优化器梯度更新,再可视化训练过程。
7.评估时,设置测试loss跟正确性,将数据跟目标循环输入,设置合适的data,数据传入模型,算损失函数的叠加值,设置一个预测值,从模型数据的每一行里选取最大的值的索引,将索引的数值循环写入正确性中得到一个sum数量,因此测试loss就用 数量/总数
8.最后可视化