Pytorch全连接网络
本篇开始学习搭建真正的神经网络,前一部分讨论深度学习中预处理数据的基本流程;后一部分构建了两种全连接网络,用三种不同方案拟合时序数据;并在例程中详细分析误差函数,优化器,网络调参,以及数据反向求导的过程。
数据预处理
本篇使用航空乘客数据AirPassengers.csv,其中包括从1949-1960年每月旅客的数量,程序则用于预测未来几年中每月的旅客数量,数据可从以下Git项目中下载。
https://github.com/aarshayj/analytics_vidhya/blob/master/Articles/Time_Series_Analysis/AirPassengers.csv
1.读取数据
首先,引入必要的头文件,并从文件中读入数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn as nn
from torch.autograd import Variable
df = pd.read_csv('data/AirPassengers.csv')
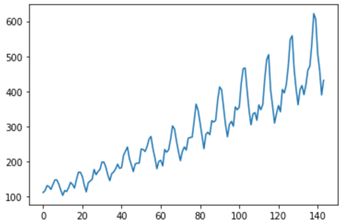
plt.plot(df['#Passengers'])
plt.show()
程序输出如下图所示:
2.归一化
无论机器学习还是深度学习,使用哪一种框架,归一化都是必要环节。归一化的目标是将每一维特征压缩到一定范围之内,以免不同特征因取值范围不同而影响其权重。非常大或非常小的值搭配上不恰当的学习率,往往使得收敛过慢,或者因每次调整的波动太大最终无法收敛。归一化去除了这些不稳定因素。
归一化的具体做法是将某一列特征转换成均值为 0、标准差为1的数据,在图像处理过程中,也常把0-255之间的颜色值转换为0-1之间的小数。
本例中使用了均值和标准差编写了归一化和反归一化函数:
def feature_normalize(data):
mu = np.mean(data,axis=0) # 均值
std = np.std(data,axis=0) # 标准差
return (data - mu)/std
def feature_unnormalize(data, arr):
mu = np.mean(data,axis=0)
std = np.std(data,axis=0)
return arr * std + mu
3.提取新特征
提取新特征是指从现有特征中提取更多可以代入模型的信息,从而生成新特征,本例中的数据包括两列,第一列“Month”是字符串类型的时间,第二列“#Passengers”是乘客量,也就是需要预测的数据y。下面通过拆分和类型转换,从第一列中提取具体的年“year”和月“mon”,将索引列变为特征“x”,并使用上面定义的函数实现归一化功能。
df['year'] = df['Month'].apply(lambda x: float(x[:4]))
df['mon'] = df['Month'].apply(lambda x: float(x[5:]))
df['x'] = feature_normalize(df.index)
df['y'] = feature_normalize(df['#Passengers'])
df['year'] = feature_normalize(df['year'])
df['mon'] = feature_normalize(df['mon'])
df['real'] = feature_unnormalize(df['#Passengers'], df['y'])
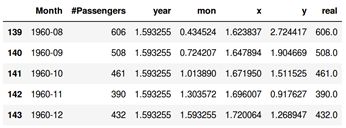
处理后的数据如下图所示:
4.处理缺失值和异常值
处理缺失值和异常值也是特征工程的重要环节,有时花费的时间比建模还多。处理缺失值的常用方法是删除重要特征缺失的item,或者用均值,前后值填充;处理异常值是监测数据中不正常的值,并做出相应处理,由于本例中数据比较“干净”,无需做缺失值和异常值处理。
5.向量化
向量化是将读出的数据转换成模型需要的数据格式,根据不同的模型做法不同,本例中的向量化将在后面的模型部分实现。
6.切分训练集和测试集
训练前还需要把数据切分成训练集和测试集,以避免过拟合,本例中将70%的数据用于训练,最终模型将对所有数据预测并做图。
TRAIN_PERCENT = 0.7
train_size = int(len(df) * TRAIN_PERCENT)
train = df[:train_size]
拟合直线
拟合程序分成三部分:定义模型、优化器和误差函数;训练模型;预测并做图。
1.定义模型、优化器、误差函数
模型继承自mm.Module,并实现了两个核心函数,init用于初始化模型结构,forward用于定义前向传播的过程。本例中实现了最为简单的模型,其中只包含一个全连接层,使用nn.Linear定义,torch.nn中定义了常用的网络层实现。
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出的维度都是1
def forward(self, x):
x = self.linear(x)
return x
model = LinearRegression()
criterion = nn.MSELoss() # 损失函数:均方误差
optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # 优化算法:随机梯度下降
损失函数使用了均方误差 MSELoss,它计算的是预测值与真值之差平方的期望值,MSELoss也是回归中最常用的损失函数,torch.nn中实现了一些常用的损失函数,可以直接使用,
优化的目标是更好地更新参数,使模型快速收敛。优化算法就是调整模型参数更新的策略,优化器是优化算法的具体实现。本例中优化器optimizer使用了最基础的随机梯度下降optim.SGD优化方法,torch.optim中定义了常用的优化器。在参数中设置了学习率为0.001,并将模型的参数句柄传入优化器,优化器后期将调整这些参数。
注意:学习率是一个重要参数,最好从小到大设置,如果设置太大,可能造成每次对参数修改过大,造成抖动,使得最终无法收敛。
2.训练模型
训练之前,先把数据转换成模型需要的数据格式,将pandas的数据格式转换为float32格式的Tensor张量,然后用unsqueeze扩展维度到2维(unsqueeze已在上一篇详细介绍)。
x = torch.unsqueeze(torch.tensor(np.array(train['x']), dtype=torch.float32), dim=1)
y = torch.unsqueeze(torch.tensor(np.array(train['y']), dtype=torch.float32), dim=1)
for e in range(10000):
inputs = Variable(x)
target = Variable(y)
out = model(inputs) # 前向传播
loss = criterion(out, target) # 计算误差
optimizer.zero_grad() # 梯度清零
loss.backward() # 后向传播
optimizer.step() # 调整参数
if (e+1) % 1000 == 0: # 每1000次迭代打印一次误差值
print('Epoch:{}, Loss:{:.5f}'.format(e+1, loss.item()))
后面的循环部分进行了10000次迭代,也就是说将所有数据放进模型训练了10000次,从而使模型收敛。每一次循环之中,将x,y分别转换成变量Variable格式。
然后进行前先传播,model(inputs)调用的是nn.Module 的call()函数(call是Python类中的一个特殊方法,如果类中定义了此方法,可以通过实例名加括号的方式调用该方法)父类的call()调用了前向函数forward()将数据传入层中处理。
接下来是误差函数和优化器配合调整模型参数,此处到底修改了哪些值,又是如何修改的,是最难理解的部分。先通过定义的误差函数计算误差,从loss值可以看到每一次迭代之后误差的情况。
下一步是优化器清零,调用优化器的zero_grad方法,清除了model.parameters中的梯度grad。
之后是反向传播,误差函数的backward,调用了torch.autograd.backward()函数,backward()是上面定义的forward()的反向过程,对每层每一个参数求导,并填充在model.parameters的grad中。
最后调用优化器的step方法(step的具体实现可参考torch源码中optim/sgd.py中的step函数),它使用model.parameters中的梯度grad和设置的学习率、动量等参数计算出model.parameters的新data值,形如:weight = weight - learning_rate * gradient。
可以说,最后几步都是针对model.parameters模型参数的修改。整个过程可以通过跟踪model.parameters的data和grad的内容变化来分析。方法如下:
for p in model.parameters():
print(p.data, p.grad)
也可以在程序中加入以下代码,用于跟踪后向传播的过程:
f = loss.grad_fn
while True:
print(f)
if len(f.next_functions) == 0:
break
f = f.next_functions[0][0]
3.预测和做图
本例中用70%数据作为训练集,用所有数据作为测试集,因此,用全部数据重新计算了x,y值;使用eval函数将模型转换为测试模式(有一些层在训练模型和预测模型时有差别);将数据代入模型预测,并转换成numpy格式作图显示。
x = torch.unsqueeze(torch.tensor(np.array(df['x']), dtype=torch.float32), dim=1)
y = torch.unsqueeze(torch.tensor(np.array(df['y']), dtype=torch.float32), dim=1)
model.eval() #将模型变为测试模式
predict = model(Variable(x)) # 预测
predict = predict.data.numpy() # 转换成numpy格式
plt.plot(x.numpy(), y.numpy(), 'y')
plt.plot(x.numpy(), predict)
plt.show()
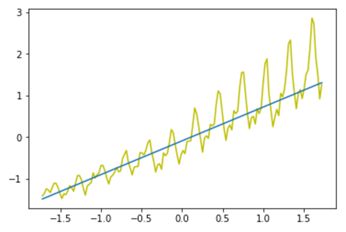
程序运行结果如下图所示,可以看到模型用一条直线拟合曲线,在前70%的训练数据中表现更好。
多特征拟合
直线拟合的原理是y=kx+b,求斜率k和截距b。其中的x是数据产生的时间,从数据表的索引号转换求得,y是乘客量。还可以使用另一些方法进一步拟合曲线。如:
- 方法一曲线拟合:从图像数据可以看出,乘客数据走势更拟合一条微微上翘的曲线,设y是x的多项式函数,可使用多项式拟合:y=ax3+bx2+cx+d。
- 方法二多特征拟合:代入更多条件,比如利用年份、月份作为参数代入模型。
多参数拟合人x不止一个,可能是{x1,x2,x3...},设计模型时只需要把输入参数变成多个即可。
1.定义模型、优化器、误差函数
与直线拟合的差异是将输入维度变为3维,模型、优化器、误差函数不变。
class Net2(torch.nn.Module):
def __init__(self):
super(Net2, self).__init__()
self.linear = nn.Linear(3, 1) # 输入3维,输出1维
def forward(self, x):
x = self.linear(x)
return x
model = Net2()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
2.训练模型
训练模型步分的主要差异在于处理输入数据,get_data函数分别提供了两种方法,前一种方法用于多项式拟合,后一种方法将年,月信息也作为代入模型的特征,此处,可以更好地理解全连接层的两维输入,其中一维是实例个数,另一维是实例中的各个特征。
def get_data(train):
if False: # 可切换两种方法
inputs = [[i, i*i, i*i*i] for i in train['x']] # 一个x变成3维输入数据
else:
inputs = [[item['x'], item['year'], item['mon']] for idx,item in train.iterrows()]
X = torch.tensor(np.array(inputs), dtype=torch.float32)
y = torch.unsqueeze(torch.tensor(np.array(train['y']), dtype=torch.float32), dim=1)
return X, y
X, y = get_data(train)
for e in range(20000):
inputs = Variable(X)
target = Variable(y)
out = model(inputs) # 前向传播
loss = criterion(out, target) # 计算误差
optimizer.zero_grad() # 清零
loss.backward() # 后向传播
optimizer.step() # 调整参数
if (e+1) % 1000 == 0:
print('Epoch:{}, Loss:{:.5f}'.format(e+1, loss.item()))
3.预测和做图
预测和做图只有取数据部分与直线拟合不同。
model.eval() #将模型变为测试模式
X, y = get_data(df)
predict = model(Variable(X)) # 预测
predict = predict.data.numpy() # 转换成numpy格式
plt.plot(y.numpy(), 'y')
plt.plot(predict)
plt.show()
两种方法拟合的曲线如下图所示:
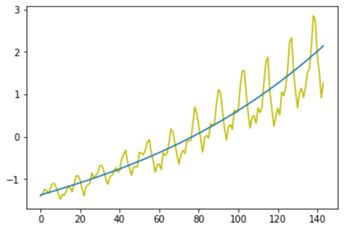
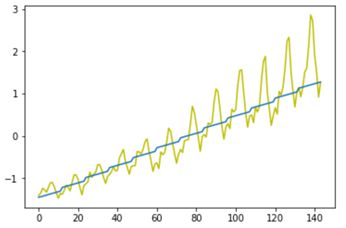
上述程序都基于线性拟合,由于月份和乘客量并无单调上升关系(年峰值在七八月),因此,线性拟合方法效果也不是很好。读者如有兴趣,可以通过预处理进一步优化该程序的效果。
总结
本篇介绍的方法,使用Pytorch深度学习框架解决了线性回归问题,第一个例程中实现的是一元线性回归,第二个例程使用的方法类似于SVM中的核函数以及多元线性回归。
使用机器学习或者传统的统计学方法也能实现线性回归,且一些机器学习方法能更好地拟合本例中的曲线。本篇主要通过例程介绍全连接层的功能和用法,只使用了一层,还谈不上深度学习。在下篇中将使用RNN网络拟合本例中的数据,以达到更好的拟合效果,并借此介绍循环网络的原理、具体实现、以及RNN相关API的调用方法。