【知识图谱】知识图谱嵌入模型简介
来自:MIRA Lab
知识图谱 (Knowledge Graphs) 是大规模语义网络知识库,采取符号化的知识表示方式,利用三元组来描述具体的知识,并以有向图的形式对其进行表示和存储,具有语义丰富、结构友好、易于理解等优点。由于在表达人类先验知识上具有优良的特性,知识图谱近年来在自然语言处理、问答系统、推荐系统等诸多领域取得了广泛且成功的应用。
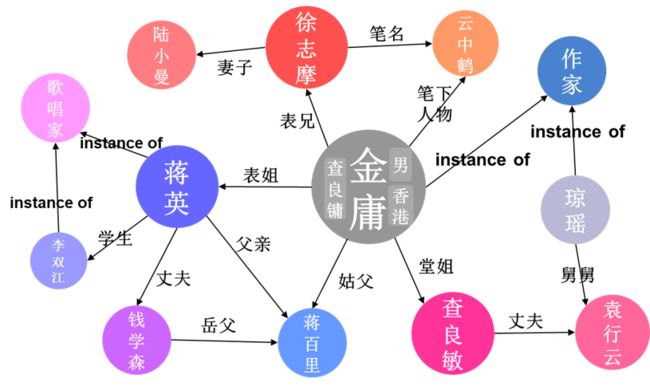 图1:知识图谱示意图
图1:知识图谱示意图
然而,知识图谱通常存在链接缺失问题,这限制了知识图谱在相关下游任务中的应用。为解决该问题,知识图谱补全任务应运而生。知识图谱补全旨在根据知识图谱中已有事实推断出新的事实,从而使得知识图谱更完整。
知识图谱嵌入 (Knowledge Graph Embedding) 是解决知识图谱补全问题的重要方法之一,它通过将知识图谱中的实体 (Entity) 和关系 (Relation) 嵌入到连续向量空间,从而在方便计算的同时保留知识图谱中的结构信息。知识图谱嵌入模型大致可以分为三类:
基于距离的模型 (Distance-based Models)
双线性模型 (Bilinear Models)
神经网络模型 (Neural Network Models)
本文将首先简要介绍知识图谱补全任务,然后回顾总结各类知识图谱嵌入模型,最后就模型的统一评测进行补充说明。
知识图谱补全任务
符号定义
知识图谱通常以三元组 (Triple) 来表示知识,三元组的一般格式为 (头实体,关系,尾实体),如“金庸的表兄是徐志摩”表示成三元组为 (金庸,表兄,徐志摩),其中金庸为头实体,徐志摩为尾实体,表兄是这两个实体之间的关系。我们使用小写的字母 来分别表示头实体、关系和尾实体, 表示知识图谱中的一个三元组。相应地,小写加粗字母 分别表示头实体、关系和尾实体对应的嵌入向量。向量 的第 个元素记作 。 表示嵌入向量的维度。 表示两个向量间的 Hadamard (element-wise) product。另外,我们使用 来分别表示 和 范数。
补全任务与性能指标
知识图谱补全 (Knowledge Graph Completion),是根据知识图谱中已有的三元组去对未知三元组进行预测。我们使用 表示已知头实体和关系来预测尾实体, 表示已知关系和尾实体来预测头实体,其中 和 被称为查询 (Query)。实际上,知识图谱补全任务,本质上给定查询下的排序问题。比如,对于图2所示的查询 (陆小曼,丈夫,?),返回的是预测答案的排序列表,正确答案排名越高,预测的效果就越好。
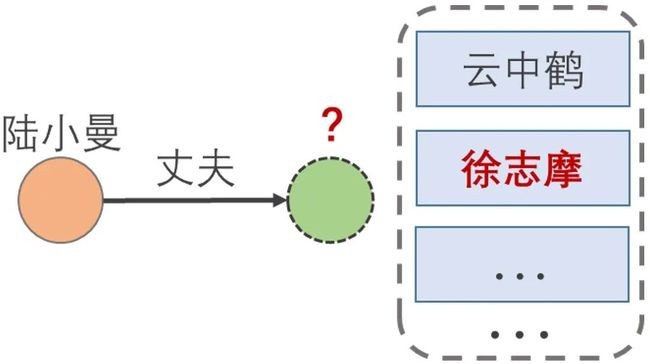 图2:查询示意图
图2:查询示意图
对于知识图谱补全任务,常用的性能评测指标有:MR (Mean Rank),MRR (Mean Reciprocal Rank), 和 Hits@N。
MR 是针对一系列查询 返回排名的平均值:
MRR 是针对一系列查询 返回排名取倒数之后的平均值:
Hits@N 是排名在前 名所占的比例:
其中,如果 , ,否则 。
在一些实际应用中,MRR 能够比 MR 更好地反映排名的综合情况。例如,在一次测试中共有4次查询,模型A返回的排名结果序列为 [1,1,1,40001],模型B返回的排名结果序列为 [10000,10000,10000,10000],从 MR 的角度,模型A效果略差于模型B,但从 MRR 的角度,模型A的效果远好于模型B。在实际应用中,可能的场景是模型给出若干个最可能的结果供人选择,我们可以发现排名10000的结果和排名40001的结果由于排名非常靠后,很难出现在供人选择的若干结果中,这两个结果虽然排名值相差30001,但是他们对实际应用的贡献都接近0。从这个角度讲,使用 MRR 来评价这两个模型更为合适。
知识图谱补全数据集
知识图谱补全任务上,目前常用的数据集有 WN18RR, FB15k-237 和 YAGO3-10 等,它们分别是 WN18,FB15k 和 YAGO3 的子集。WN18 和 FB15k 数据集早期被用于知识图谱补全任务,但是后来有研究者发现这两个数据集存在一定的测试集泄漏问题,在这两个数据集上,简单的基于规则的方法就能够达到先进模型的效果,所以 WN18 和 FB15k 渐渐不被研究者使用。表1显示了知识图谱补全数据集的具体统计信息,其中数据集大小指的是三元组的数量。
 表1:知识图谱补全数据集
表1:知识图谱补全数据集
知识图谱嵌入模型
知识图谱嵌入模型的设计通常需要三步:1)定义实体和关系的表示形式;2)定义衡量三元组合理性的打分函数;3)训练学习实体和关系的嵌入表示 [13]。打分函数值越高,代表三元组的合理性越高,即正确的可能性越大。在训练学习实体和关系的嵌入表示时,优化目标是使得知识图谱中已有三元组得分尽可能比未出现的三元组得分要高。根据打分函数的定义形式,可以将知识图谱嵌入模型大致分为基于距离的模型、双线性模型和神经网络模型。部分知识图谱嵌入模型的打分函数对比见表2。
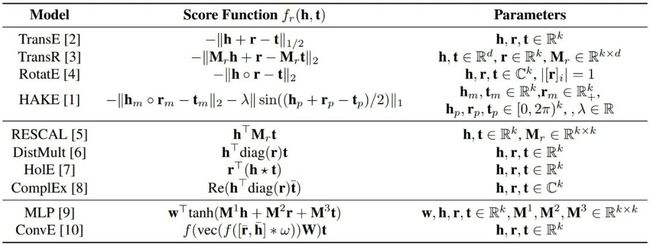 表2: 知识图谱嵌入模型打分函数对比。 其中 表示 Hadamard product, 表示激活函 数, 表示循环相关运算 (Circular Correlation Operation), 表示 2D 卷积操作, 表示卷积层的滤波器 (Filter), 表示 ComplEx 模型中的复向量取共轭和 ConvE 模型中的实向量的 2D reshaping。
表2: 知识图谱嵌入模型打分函数对比。 其中 表示 Hadamard product, 表示激活函 数, 表示循环相关运算 (Circular Correlation Operation), 表示 2D 卷积操作, 表示卷积层的滤波器 (Filter), 表示 ComplEx 模型中的复向量取共轭和 ConvE 模型中的实向量的 2D reshaping。
基于距离的模型
基于距离的模型将关系建模成从头实体到尾实体的距离变换,并通过变换后的距离差来定义打分函数。
TransE [2] 假设实体和关系满足 ,其中 , 表示向量维度,定义打分函数为:
其中,我们使用 来代表在该打分函数中使用 范数或者 范数皆可。
然而,TransE 模型难以处理多对一、一对多、多对多问题。以一对多问题为例,如存在两个三元组 ,在 TransE 模型下,我们有 ,由此可得 。这可能是不合理的,例如,我们有两个三元组为 (金庸,作品,倚天屠龙记) 和 (金庸,作品,天龙八部),从TransE模型的角度,要求倚天屠龙记 和 天龙八部这两个实体的嵌入向量非常相近,然而倚天屠龙记和天龙八部显然是不同的作品。
通过让实体在不同关系下拥有不同的嵌入向量,可以一定程度解决这个问题。TransR [3] 提出针对每个关系 设计一个投影矩阵 ,实体在不同关系下的表示为:
通过这种方式,实体在不同关系下可以有不同的表示,最后的打分函数定义为:
其中, 。
另一方面,为了能够更好地建模知识图谱中的关系模式,RotatE [4] 把关系定义成复空间中头实体到尾实体的旋转变换 (Rotation),并假设实体和关系满足 ,其中 , 表示向量维度,RotatE 的打分函数为:
最近,HAKE [1] 模型使用极坐标系建模知识图谱中普遍存在的语义分层现象,利用模长部分建模分属不同层级的实体,利用角度部分建模属于同一层级的实体,在主流数据集上的性能超越了现有基于距离的模型。感兴趣的读者可以参考我们之前的分享了解详细情况:HAKE。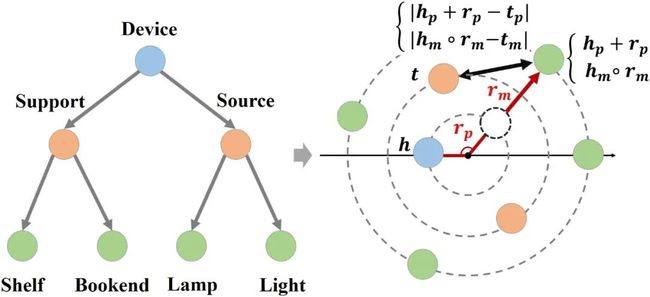
双线性模型
双线性模型采用乘积形式的打分函数来衡量实体和关系的语义相关性。
RESCAL [5] 定义打分函数为:
可以看作是 的双线性函数,其中矩阵 。为了降低计算量,DistMult [6] 将矩阵 设计成对角矩阵,HolE [7] 则使用循环相关运算 (Circular Correlation Operation) 来代替中间的关系矩阵乘积。这些方法计算方式的示意图见图5。
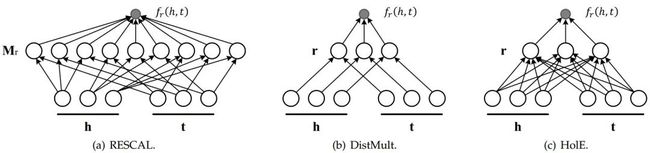
ComplEx [8] 模型将 DistMult 模型扩展到复数空间,从而更好地建模反对称和可逆关系,它的打分函数为:
其中, , 代表对向量 取共轭, 代表取实部。
神经网络模型
神经网络模型将 同时输入神经网络,来判断三元组的打分。早期的工作如 MLP [9] 使用全连接神经网络来对给定的三元组进行打分。近年来,ConvE [10] 等工作使用卷积神经网络 (Convolutional Neural Network) 来定义打分函数。由于知识图谱是一种图结构的数据,近期也有一些工作将图神经网络 (Graph Neural Network) 应用于知识图谱嵌入。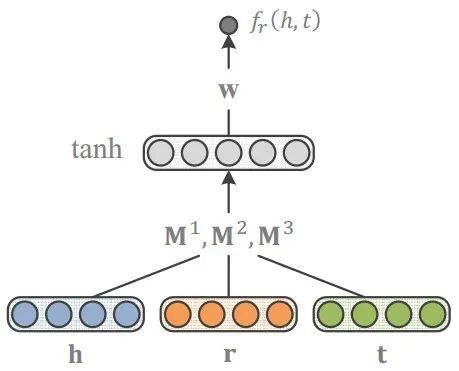
模型统一评测
近年来,大量的知识图谱嵌入模型被提出,各种方法层出不穷,模型效果的实际对比有待研究。近期,有两篇工作对现有的知识图谱嵌入模型进行了一些总结和重新评测,揭示了各个模型性能在统一评测下的效果,也为我们提供了对这些模型更为清晰的认识。
Zhiqing Sun 等人 [11] 指出,使用不恰当的评测方式,可能会造成实验结果虚高。在进行效果评测时,可能会有一些三元组得分和正确答案的得分相同,这时候针对这些相同得分的结果集合 可以有不同的排序策略:
TOP:将正确答案排在 的最前面
BOTTOM:将正确答案排在 的最后面
RANDOM:给正确答案在 中随机分配一个位置
值得注意的是,TOP 的排序策略在某些情况下是不恰当的,会导致结果虚高。一个直观的例子是,让一个模型对所有的候选三元组打分都输出0,这时正确答案和所有候选三元组得分相同,在 TOP 排序策略下,该模型所有正确答案都排名第一,评测性能达到顶峰。但实际上,由于候选三元组得分相同,该模型在预测时无法判别哪个为正确答案。由此可见,TOP 的排序策略会导致结果虚高。文章指出,RANDOM 的排序策略是最为合理的 [11],这和我们实际的认知也是相符合的,即给定多个相同得分的候选者,我们通常采用随机的方式来挑选。采用统一的 RANDOM 策略进行评测之后,可以发现有些模型尤其是部分神经网络模型的性能显著下降,这表明有些模型由于不恰当的评测方式,导致了结果的虚高,这是我们需要注意甄别的。
另外,Daniel Ruffinelli 等人 [12] 对各种知识图谱嵌入模型中使用到的训练方式进行了系统的实验和研究,发现一些早期的模型如 RESCAL 在调整训练方式和进行更大的超参搜索之后,也能够达到或者超过现有先进模型的效果。这也显示了模型性能的提升未必是方法具有很大的优势,训练技巧也可能在其中起到不小的作用,我们需要通过统一评测去认知各个方法中真正有价值的思路和想法。
总结
本文首先简要介绍了知识图谱补全任务,包括评测方式、评测指标和评测数据集。知识图谱嵌入是处理知识图谱补全任务的重要方法之一。本文按照基于距离的模型、双线性模型和神经网络模型的分类方式,对知识图谱嵌入模型进行简要介绍。最后,本文结合两篇最新工作,指出模型统一评测的重要性。限于篇幅原因,本文只进行了简要的总结,更多细节请参考相应的原论文,以下给出文中参考文献的详细列表。
参考文献:
[1] Zhanqiu Zhang, Jianyu Cai, Yongdong Zhang, and Jie Wang. 2020. Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. In AAAI.[2] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Durán, Jason Weston, and Oksana Yakhnenko. 2013. Translating Embeddings for Modeling Multi-relational Data. In NIPS.
[3] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In AAAI.
[4] Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In ICLR.
[5] Maximilian Nickel, Volker Tresp, and Hans-Peter Kriegel. 2011. A threeway model for collective learning on multi-relational data. In ICML.
[6] Bishan Yang, Scott Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In ICLR.
[7] Maximilian Nickel, Lorenzo Rosasco, and Tomaso Poggio. 2016. Holographic Embeddings of Knowledge Graphs. In AAAI.
[8] Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex Embeddings for Simple Link Prediction. In ICML.
[9] Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A webscale approach to probabilistic knowledge fusion. In SIGKDD.
[10] Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018. Convolutional 2d knowledge graph embeddings. In AAAI.
[11] Daniel Ruffinelli, Samuel Broscheit, and Rainer Gemulla. 2020. You CAN Teach an Old Dog New Tricks! On Training Knowledge Graph Embeddings. In ICLR.
[12] Zhiqing Sun, Shikhar Vashishth, Soumya Sanyal, Partha Pratim Talukdar, and Yiming Yang. 2020. A Re-evaluation of Knowledge Graph Completion Methods. In ACL.
[13] Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. 2017. Knowledge Graph Embedding: A Survey of Approaches and Applications. In TKDE.
作者简介:陈佳俊,2019年毕业于厦门大学自动化系,获得工学学士学位。现于中国科学技术大学电子工程与信息科学系的 MIRA Lab 实验室攻读研究生,师从王杰教授。研究兴趣包括知识表示与知识推理。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
后台回复【五件套】
下载二:南大模式识别PPT
后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!