聚类分析(系统聚类,K-mean聚类)
系统聚类分析
参考文献:https://blog.csdn.net/sinat_40431164/article/details/81017568?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
| 地区 |
食品 |
衣着 |
燃料 |
住房 |
交通和通信 |
娱乐教育文化 |
| 北京 |
190.33 |
43.77 |
9.73 |
60.54 |
49.01 |
9.04 |
| 天津 |
135.2 |
36.4 |
10.47 |
44.16 |
36.49 |
3.94 |
| 河北 |
95.21 |
22.83 |
9.3 |
22.44 |
22.81 |
2.8 |
| 山西 |
104.78 |
25.11 |
6.4 |
9.89 |
18.17 |
3.25 |
| 内蒙古 |
128.41 |
27.63 |
8.94 |
12.58 |
23.99 |
2.27 |
| 辽宁 |
145.68 |
32.83 |
17.79 |
27.29 |
39.09 |
3.47 |
| 吉林 |
159.37 |
33.38 |
18.37 |
11.81 |
25.29 |
5.22 |
| 黑龙江 |
116.22 |
29.57 |
13.24 |
13.76 |
21.75 |
6.04 |
| 上海 |
221.11 |
38.64 |
12.53 |
115.65 |
50.82 |
5.89 |
| 江苏 |
144.98 |
29.12 |
11.67 |
42.6 |
27.3 |
5.74 |
| 浙江 |
169.92 |
32.75 |
12.72 |
47.12 |
34.35 |
5 |
| 安徽 |
135.11 |
23.09 |
15.62 |
23.54 |
18.18 |
6.39 |
| 福建 |
144.92 |
21.26 |
16.96 |
19.52 |
21.75 |
6.73 |
| 江西 |
140.54 |
21.5 |
17.64 |
19.19 |
15.97 |
4.94 |
| 山东 |
115.84 |
30.26 |
12.2 |
33.6 |
33.77 |
3.85 |
| 河南 |
101.18 |
23.26 |
8.46 |
20.2 |
20.5 |
4.3 |
import pandas as pd
from sklearn import preprocessing
import scipy.cluster.hierarchy as sch
#用于进行层次聚类,画层次聚类图的工具包
from matplotlib import pyplot as plt
df = pd.read_excel("习题5.8.xlsx")
label =df['地区']
array = df.values[:,1:7]
def ZscoreNormalization(X):
scaler = preprocessing.StandardScaler().fit(X)
x_norm = scaler.transform(X)
return x_norm
X_norm =ZscoreNormalization(array)
Z = sch.linkage(X_norm,method='ward', metric='euclidean')
sch.dendrogram(Z)
plt.title('Clustering')
plt.xlabel('地区')
plt.ylabel('distance')
plt.show()
----------------------------------------------------------------------------------------------------
K-mean 聚类
K-means伪代码
输入:样本集;

聚类簇数:k
终止条件:迭代次数iteration或者的阈值
过程:
从样本集中随机选取个 k 样本作为初始均值向量:
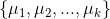
repeat
令

for

计算样本与各均值向量 的距离
根据距离最近的均值向量确定的簇标记:
将样本划入相应的簇:
end for
for
计算新的均值向量:
end for
until 达到终止条件
输出:簇划分:

import pandas as pd
from sklearn import preprocessing
import scipy.cluster.hierarchy as sch
#用于进行层次聚类,画层次聚类图的工具包
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from prettytable import PrettyTable
##数据准备
df = pd.read_excel("习题5.8.xlsx")
label =df['地区']
array = df.values[:,1:7]
##数据预处理
def ZscoreNormalization(X):
scaler = preprocessing.StandardScaler().fit(X)
x_norm = scaler.transform(X)
return x_norm
X_norm =ZscoreNormalization(array)
##K—mean 聚类
cluster = 4
cls =KMeans(cluster).fit(X_norm)
# print(cls.labels_) #输出分类列表
cls_result,results =[],[]
for i in cls.labels_:
cls_result.append(i)
results =list(zip(label,cls_result))
Results= PrettyTable(["地区", "K-mean分类"])
for i in results:
Results.add_row([i[0],i[1]])
print(Results)
