论文阅读1:AMIE: Association Rule Mining under Incomplete Evidencein Ontological Knowledge Bases
目录
Introduction
基本定义
挖掘模型
AMIE
算法
Implementation
参考文献
Introduction
一些研究存在的问题
关联规则挖掘本质上实现了一个封闭世界假设(CWA)。不能用于向数据库中添加新项。
当前ILP系统不能用于语义知识库:因为1)ILP需要否定语句作为反例,但语义知识库通常不包含否定陈述。2)运行很慢。无法处理KB提供的大量数据。
本文AMIE特点:系统被设计在OWA(开放世界假设,知识库中未包含的语句不一定是错误的)下工作;可以有效地处理大数据量的KB;可以提供模拟正知识库反例的方法;挖掘Horn规则。
基本定义
Rule:原子是一个在subject和/或object位置可以有变量的fact。Horn规则由head和boday组成,其中head是单个atom,body是一组atoms.头部为r(x,y)、body为{B1,…,Bn}的规则

规则的实例化是规则的副本,其中所有变量都被entity替换。如果实例化规则的所有body atoms都出现在KB中,则规则的prediction是实例化规则的head atom。
Language Bias:AMIE使用Language Bias限制搜索空间。如果rule中的两个atom共享一个变量或一个实体,则它们是连接的。如果规则的每个原子都与规则的其他原子传递连接,则规则是connected。如果规则中的每个变量至少出现两次,则规则是closed。AMIE只研究connected rules,避免构造包含不相关atoms的规则。研究closed rules。
挖掘模型
模型:考虑一个给定的Horn规则~B⇒ r(x,y)。用关系r来看待所有facts。fact可以为知识库已知的真实事实(KBtrue),知识库未知的真实事实,知识库中已知的错误事实(KBfalse),以及知识库未知但错误的事实(NEWfalse)。该规则将做出某些预测(蓝色圆圈)。这些预测可以是正确的(A)、错误的(C)或未知的(B和D)。
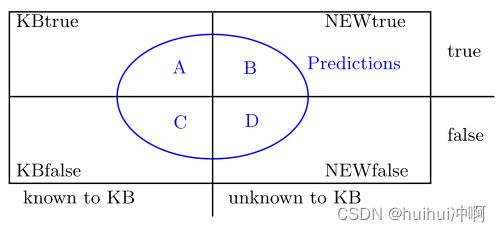
目标:找到能够做出不在当前KB的True prediction的rule。即最大化区域B,并最小化区域D。
挑战:第一,区域NEWtrue和NEWfalse是未知的。我们希望使用面积KBtrue和KBfalse来估计未知面积。然而,这导致了第二个挑战:语义知识库不包含负面证据。因此,区域KBfalse为空。
挑战的解决(也是评估准则):
1
- support
规则的支持量化了正确预测的数量。将规则的支持度定义为KB中出现的所有实例化的头部中不同的主题和对象对的数量。

- Head Coverage
support是一个绝对数字,没有考虑数字大小。规则的预测所涵盖的来自head关系对的比例。(不直接除以KB的大小,因为可能有些关系产生的预测本来就少,那对比不就不公平?)

2.生成负例的方法
- Standard Confidence标准置信度
将知识库中未包含的所有事实(即NEWtrue和NEWfalse)作为负面证据。规则的标准置信度是其在知识库中的预测的比例。但是它主要描述已知数据,惩罚在未知区域进行大量预测的规则,与目的(能在知识库外做大量的正确预测)想反。
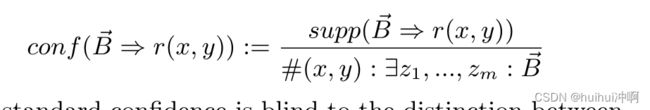
- Positive-Only Learning
将随机的事实作为负面证据。一个好的规则应该涵盖很多积极的例子,而很少或没有随机生成的例子。这确保了规则不会过于一般化。此外,该规则应该使用尽可能少的原子,从而实现高压缩。
- PCA confidence
和其它方法使用所有facts进行normalize,使用一系列我们知道它们是真的事实,以及我们假设它们是假的事实。
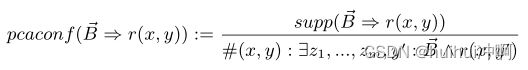
AMIE
介绍框架的核心算法和实现。
算法
目标:挖掘上述定义的形式的规则,找到有效的方法来探索搜索空间。通过Mining Operators迭代扩展规则来探索搜索空间。
Mining Operators:将规则视为atom序列。第一个原子是head atom,其他的是body atoms。
- 添加悬空atom(OD):向规则添加一个新atom,新atom使用一个新variable作为它的两个参数之一。另一个参数(variable或entity)与规则共享,即是出现在规则中的。
- 添加实例化atom(OI):向规则添加一个新atom,新atom使用一个entity作为它的两个参数之一。另一个参数(variable或entity)与规则共享,即是出现在规则中的。
- 添加闭合atom(OC)该操作符向规则添加一个新原子,以便它的两个参数与规则共享。
通过重复应用这些操作符,可以生成第3节中定义的整个规则空间。运算符生成的规则甚至比感兴趣的规则还要多,因为它们也生成了未关闭的规则。这些操作符不是单调的,因为一个操作符生成的原子可以在下一步被另一个操作符修改。
算法
通过依次学习预测每种关系的规则:对于每种关系,从规则体为空的规则开始,通过三种操作扩展规则体部分,保留支持度大于阈值的候选(闭式)规则。
该算法维护一个规则队列,最初只包含空规则。该算法迭代地将规则从队列中解队列。如果规则是闭合的,则输出该规则,否则则不输出。然后,算法对规则应用所有操作符,并将得到的规则添加到队列中(除非它们被puned out)。重复此过程,直到队列为空。

puning修剪
设θ = 0.01为head converage的下界。当添加更多的原子时,head converage单调地减少。这允许安全地丢弃任何越过阈值的规则。如果一条规则B1∧…∧Bn∧Bn+1格H并不比规则B1∧…∧Bn的置信度好,那么我们就不输出较长的规则了。这是因为较长的规则的置信度和头部覆盖都必然由较短的规则支配。通过这种方式,可以减少生成规则的数量(第6行和第7行)。最后,从不对已经在队列中的规则进行再排队,检验两条相等的规则是昂贵的。
Projection Queries
为了只选择满足头部覆盖限制的关系和实体,依赖KB来回答投影查询。选择一个实体或关系x,使得查询的结果H∧B1∧…∧Bn在KB上包含超过k个不同的H查询答案。选择k等于θ乘以H的关系的事实数量,那么结果规则的头部覆盖将大于θ。
Implementation

参考文献
AMIE | Proceedings of the 22nd international conference on World Wide Web (acm.org)