论文阅读笔记 | 三维目标检测——PartA2算法
如有错误,恳请指出。
文章目录
- 0. 前言与补充知识
- 1. 背景
- 2. 相关工作
- 3. 网络结构
-
- 3.1 Part-aware stage
-
- Anchor-free Proposal Generation
- Anchor-based Proposal Generation
- Discussion Two Proposal Generation Strategies
- 3.2 Part-aggregation stage
-
- ROI-aware feature pooling
- Part location aggregation
- 3.3 Overall loss
- 3.4 Date Augmentation
- 3.5 Pros and cons
- 4. 实验结果
paper:《From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network》
0. 前言与补充知识
回顾上一篇文章,PointPillars对每个点扩维,增加构造了质心点xyz坐标与中心偏移量xp,yp这五个特征,进行pillars量化操作的结果竟然比SECOND进行voxel量化的效果要好,这可能说明voxel的局部特征构建非常重要,这种增加质心点与偏移量的方法给PointPillars带来了极大的提升。或者说这种方法是一种隐式的voxel-based,因为并没有把z轴信息给全部丢弃,而是转化到了Pillars具体的每个点特征上,不过这是作为了一种手工特征,强加了部分的先验知识。但是整个网络结构来说,PointPillars是非常的清晰简洁的。
这今天介绍的PartA2,则是通过了详细的实验证明了,使用稀疏3d卷积来处理这种voxel的特征,要比直接使用PointNet++来提取点云特征要有效。同时voxel级别的量化并没有丢失太大的点云信息,保留的基本结果是一致的。这里引用参考资料1,介绍Sparse Convolution与Submanifold Sparse Convolution,如下图所示:

整篇文章的内容比较多,篇幅比较长,网络结构也比较复杂,我会尽可能的介绍得详细一些。ps:PartA2的作者也是PointRCNN的作者
1. 背景
在之前介绍到,PointRCNN中发现了基于点云的3d目标中相比2d检测有一个与生俱来的优势,就是3d的标注框不仅提供了检测的目标框,同时还提供语义分割的前景点(也就是目标框中的点)。在PartA2中,作者进一步发现了我们不仅可以获得需要检测的标注框及其包括的前景点,我们还可以获得每个前景点在标注框中的空间分布信息,或者说是每个前景点在标注框内的相对位置信息。在现有的研究下,其实并没有完全的将3d标注框的信息完全利用上,这种前景点在标注框的分布信息是有利于提高3d检测网络的性能的。
这种特殊的现象只发生在自动驾驶场景(outdoor)的点云3d检测任务中。因为室外场景的点云检测任务天然的将不同的物体相互区分开来且没有遮挡与重叠,而2d的检测中物体之间可能存在遮挡现象导致位置信息存在噪音,室内场景的点云检测也会存在遮挡现象(比如桌子的底下还有一张凳子),这样的标注信息就会存在噪声,数据点的分布就不明确,所以对于自动驾驶的点云3d检测任务的场景下,我们可以从标注中获取更多的信息。
PartA2被设计为一个two-stage的网络结构,其中stage1将对前景点进行语义分割,并且预测所有前景点的对象内部位置(这里称为intra-object part locations),这里的分割掩码信息(segmentation masks)与目标框内部位置信息(ground-truth part location annotations)直接从ground truth的标注中获取。stage2的作用就是对候选框中的语义信息以及前景点的位置分布信息进行聚合,进行后续的修正。
PartA2同时设计了anchor-free与anchor-based两种方案,各有优越点,分别称为PartA2-free与PartA2-anchor。其中,anchor-free避免了大量anhcor的生产,节省了内存消耗,更加轻量且更有效率;而anchor-based在每个特征点中放置多个具有不同方向和类别的先验框,需要更多的内存消耗但可以实现更高的召回率,最后的检测精度也更高。
此外,在第二个阶段进行roi pooling时,PartA2将其改进为自注意ROI点云池化操作(RoI-aware point cloud pooling operation),以解决PointRCNN中存在的候选框点表示模糊的问题,具体来说就是不同的候选框可能最终pooling的点的一样的,这会导致空间信息编码有误。这里提出的ROI-aware操作则会同时保留候选框中的全部体素(空体素以及非空体素),来消除之前pooling策略的模糊性问题,这有助于整个候选框的几何信息编码以及位置细化修正的有效表征。具体的编码方式同样是进行3d稀疏卷积来实现,后续的网络结构中会详细介绍。
通篇看下来,所观察到的点感觉比较新颖,第一次考虑到了标注框中点的空间分布信息,而且在对候选框的roi池化编码操作中也很有创意。大佬发了每一篇文章真的都让人耳目一新,收获满满。下面我会详细介绍整个PartA2结构。
2. 相关工作
- 对于3d检测的现有工作下,主要分成了3个部分:
基于rgb图像(from 2d images)、基于多传感器(图像点云融合,from multiple sensors)、以及直接基于点云进行检测(from point clouds only)。
1)直接基于图像的方法主要有单目和双目检测,但这些方法由于只使用2d图像,缺乏精确的深度信息,所有只能生成比较粗略的3d检测结果,并且会受到外观变化的显著影响。
2)对于多传感器融合的方法在实际应用中会遇到多传感器时间同步的问题。
3)而现有的仅基于点云进行检测方法,都没有完全利用3d标注框提供的丰富信息,比如前景点在对象内部的空间部分。PartA2的一个出发点就是为了利用这个额外信息来学习3d物体内的点部分以进行二阶段的信息聚合。
- 对于3d点云的特征提取主要有3个方法:
1)投影到鸟瞰图中利用2d卷积进行特征提取;
2)利用PointNet++等类似结构直接从原始点云中提取点特征;
3)对点云进行量化操作(voxel-based,pillar-based)然后利用3d稀疏卷积进行特征提取。这里基于3d稀疏卷积以及3d稀疏反卷积操作涉及了一个类似U-Net的结构对点云特征进行处理,也就是基于voxel对点云处理,属于第三个方法。paper设计的结构比PointNet++要更加高效。
- 这里还提及到了语义分割的3中常用方法:
1)基于3d/2d检测边界框,在其基础上添加一个用于预测分割掩码的分支,类似与MaskRCNN;
2)预估每个点的分割label,然后基于这些point-wise的特征embedding将点进行实例分组(比如计算点之间的相似性用于对每个实例的前景点进行分组);
3)将pixel聚类实现2d的实例分割方案,不过这些方法只能将前景点分组到不同的实例中,不估计3d边界框。
3. 网络结构
PartA2的完成结构如下所示,主要分为两个部分:part-aware stage以及part aggregation stage,后续内容也分这两个部分进行介绍。
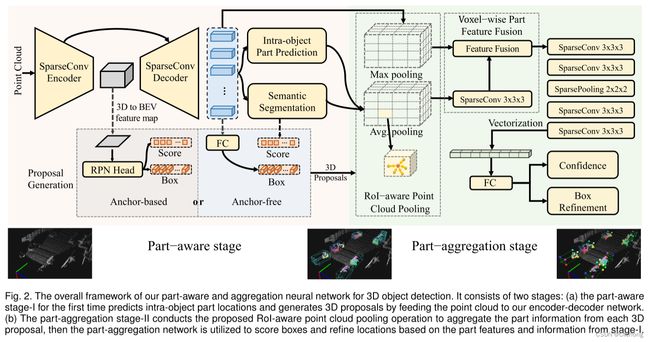
3.1 Part-aware stage
前文提到,PartA2其实属于的是voxel-based方法。对整个3d点云场景可能是70mx80mx4m,这里会将其在空间上划分为5cmx5cmx4cm大小的体素网格。将体素内的每个点特征值进行平均作为体素特征(voxel-based),也就是相当是利用体素中全部的point-wise feature平均为一个点,实现体素的初始化,此时在整个三维空间中大约还有16k个非空体素。此时所保留的体素通过可视化展示,其实损失的信息并不多,如下图所示保持了与原始点云的近似等效性,还能很好地保持三维物体的三维形状。

体素化后的点云特征会通过一个类似UNet的Encoder-Decoder架构对体素特征进行编码,其具体的结构如下图所示。可以看见,这里的特征提取网络主要是有3d稀疏卷积以及3d稀疏反卷积操作实现。通过步长为2的一些卷积层将输入降采样至1/8的大小,然后再通过Upsampling上采样至原来的分辨率,这样就得到了Voxel-wise的feature(这里需要注意的是,这里的卷积是具有4个维度的)。这里采用的网络结构比使用PointNet++更加的高效,此时所获得是就是voxel-wise的特征,后续将基于这voxel-wise特征进行局部位置预测与分割掩码预测。
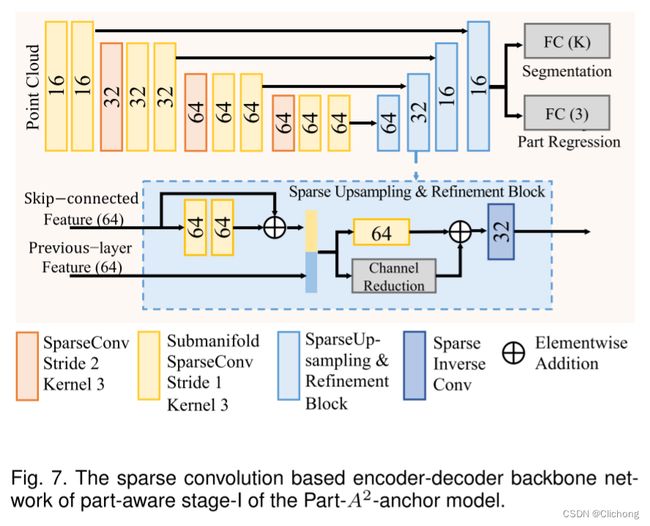
在背景中提到,在自动驾驶室外场景下的3d标注中,天然的包含了点的语义信息以及在标注框内部的相对位置信息,此时我们可以利用刚刚所获得的voxel-wise feature对这些信息进行前景点预测以及相对位置的获取。注意,这里所说的voxel化由于是有voxel内点的均值所获得,其实从另外一个角度来看每个voxel-wise特征也可以看成是一个均值化后的point-wise特征,这样对于前景点概念有更好的理解。也就是说,对于标注框中的voxel(前景点),我们是可以获得其在标注框的一个局部相对位置的,同时也可以获得其语义分割的掩码信息(属于哪个列)。对于边界框的中心设置坐标为[0.5,0.5,0.5],这样我们就获得相对位置的监督值,对每个前景点自身所在的局部位置进行预测。
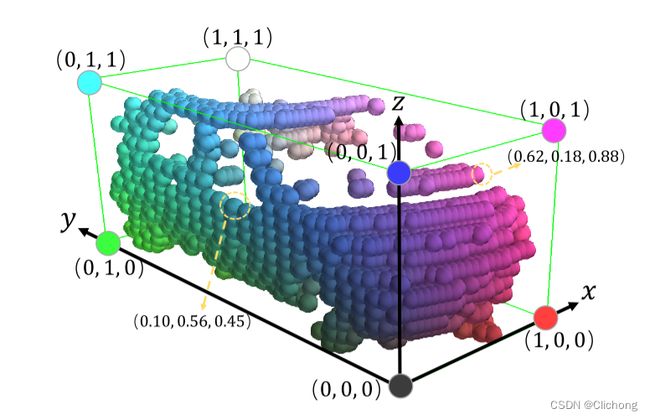
如PartA2的结构图所示,在特征提取Encoder-Decoder后,会添加两个分支来输出特征。一个分支用来预测每个前景点的相对位置信息(也就是分布信息),另外一个分支用来对前景点进行多类别语义分割,这两个分支都用Sigmoid函数作为用于产生输出的最后非线性函数。而由于进行语义分割时,背景点的数量一般比前景点的数量要多,所以存在一个类别不平衡的问题,需要利用focal loss来减少大量负样本的损失。显而易见,这里存在两个部分的损失,一个是使用focal loss的分割损失Lseg,另外一个的局部位置预测的损失Lpart。而由于这里每个前景点预测的内部位置在0-1区间,所以使用了二值交叉熵(binary cross entropy)来计算。
这里PartA2设计了分别设计了两种候选框的生成策略:anchor-free与anchor-based,两种方法的损失计算与结构均不一样,下面分别进行介绍。

Anchor-free Proposal Generation
对于采用anchor-free生成候选框策略的PartA2称为PartA2-free。
在PartA2-free结构中,对于Encoder-Decoder提取出来的特征,可以通过语义分割的掩码获取前景点,随后对这些前景点使用另外的一个分支来预测生成3d候选框,如上图所示的anchor-free部分。对于每个前景点如果直接回归标注框,那么回归的目标可能在一个比较大的范围内变化。比如GT角点上的前景点,其到对象中心的相对偏移远大于对象侧面上的前景点的相对偏移,所以如果对每个前景点直接预测相对偏移量那么总损失将被角点除的前景点的偏移损失所支配,这样会导致损失不平衡。
为了避免直接回归带来的损失平衡,PartA2-free采用bin-based的回归方式,与PointRCNN中一致。也就说,对于xy坐标以及角度θ来说,先分类缩小回归距离然后对残余距离进行回归操作,也就是先确定位置大概的区域后再进行小范围回归(其中角度的范围是2π,划分为w个区域)。而对于位置坐标z以及尺寸信息hwl,可以直接进行smooth-L1回归操作。详细见我在PointRCNN中的笔记。损失组成如下所示:

Anchor-based Proposal Generation
对于采用anchor-based生成候选框策略的PartA2称为PartA2-anchor。
如果采用anchor-based的策略,这里会对Encoder中输出的编码进行8x下采样同时将特征投影到鸟瞰图中,也就是将MxNxHxD转换为(M/8)x(N/8)x[(H/16)xD],相当于对于z轴的特征信息全部拼接了起来,转为为了2d的特征图。之后的操作就是类似了,在生成的2d特征图中的每个特征点,对于每个类别设计2种相互垂直方向但尺寸一致的3d先验框(priors)。正负样本通过设置在鸟瞰图上不一样的iou实现,比如对于汽车、行人和骑自行车的人,正样本IoU阈值根据经验分别设置为0.6、0.5、0.5,负样本IoU阈值分别设置为0.45、0.35、0.35。
通过iou筛选后的anchor一般都在GT附近,所以可以直接进行回归处理,此时的回归距离是比较小的因此不需要采用anchor-free的那种分区+残差距离预测来实现。这里的损失设置与SECOND方法完全一致,使用了sin(θ(gt) − θ(a))来编码方向损失,消除方向的模糊性。因为改方法会将两个相反的方向编码为相同的值,所以需要第三个分支来预测方向。由于gt的方向属于-π~π,所以这里的分支预测如果θ(gt)为正,则方向目标为1;否则方向目标为0。损失组成如下所示:

Discussion Two Proposal Generation Strategies
这两种3D候选框策略都有其优点和局限性。所提出的无锚点策略通常是轻量级的并且存储器高效的,因为它不需要评估3D空间中的每个空间位置处的大量锚点。由于3D对象检测中的不同类别通常需要不同的锚框,而无锚点方案可以共享逐点特征以生成多个类别的建议,因此对于多类别对象检测的效率更明显。第二种基于锚点的建议生成策略通过为每个类别预先定义锚点来覆盖整个鸟瞰图特征图,实现了略高的召回率,但具有更多的参数,需要更多的GPU内存。
3.2 Part-aggregation stage
通过以上步骤,现在获取到对象内部点的位置分布信息以及3d候选框,后续希望聚合一个候选框内所有点的位置部分信息以及point-wise点特征来进行候选框的评分以及修正。这里包含两个部分:roi-aware特征池化操作以及候选框信息聚合操作(part aggregation)。
ROI-aware feature pooling
在进行roi池化之前,需要先进行坐标系的规范化,这与PointRCNN中同样一致,所谓的坐标系规范化就是将每个候选框中的汇集点(pooled points)转换到各个相应候选框中的坐标系中。对于每一个候选框的规范坐标系的具体的操作是:1)原点位于框方案的中心;2)局部X和Y轴近似平行于地平面,其中X指向建议的头部方向,而另一Y轴垂直于X;3)Z轴与整体坐标系的Z轴保持一致。候选框中的所有汇集点坐标p都进行适当的选择和平移操作转化到规范坐标系p`上。正样本的候选框与其对应的GT同样被变换到规范坐标系以计算用于回归距离。规范坐标系基本上消除了不同3D方案的大量旋转和位置变化,并提高了特征学习的效率,以用于随后的框位置修正。
在PointRCNN的工作中,点汇集操作直是将一个候选框中的所有点特征进行聚合来对候选后进行修正,但这种3d候选框汇总引入了模糊性的问题,如下图所示,不同的候选框之间可能包含的是一样的汇集点,这种相同的汇集特征pooling feature可能会导致后续修正框的性能。
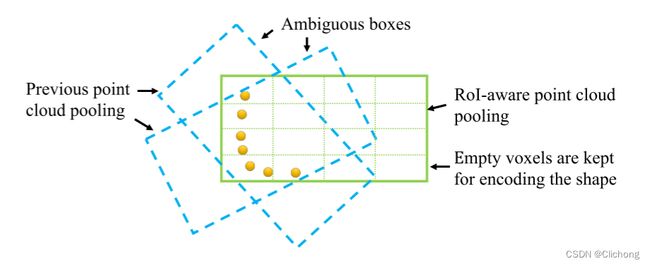
解决这种模糊性问题的关键是需要利用空体素的信息,来捕获完整的候选框空间位置。在PartA2的完整结构图中可以看出,这里对每一个候选框均匀的划分为一个固定的空间形状(这里是14x14x14的大小)。也就是说,对于任意不同尺寸的候选框,都划分成14x14x14的大小,对proposal进行voxel化。那么,对于候选框内的每个voxel,都会包含Part-aware Stage中的一些点(其实也是体素中心)。其中,对于每个voxel中的点,将其Encoder-Decoder输出的point-wise特征,进行max pooling池化操作;将其point-wise的内部信息(point-wise part location)以及语义分数(semantic scores)两个部分的特征拼接起来,进行avg pooling池化操作。那么,对一个切分为14x14x14的候选框来说,分别构建了两个池化特征,维度组成为14x14x14xC1与14x14x14xC2。
将候选框内部点分别根据不同的Point-wise信息构建成两个池化特征层既完成了ROI-aware feature pooling操作,同时考虑了空体素信息以及非空体素的信息。
Part location aggregation
随后将这两个3d的特征层在channels上进行拼接(先对avg pooling特征进行一个稀疏3d卷积),也就是变换成14x14x14x(C1+C2)。随后堆叠几个卷积核大小为3x3x3的稀疏卷积进行特征提取,再进行一个2x2x2的稀疏池化进行下采样操作,将特征体积降采样到7 × 7 × 7,以节省计算开销和参数。最后将特征转为为一个向量(feature vector),空体素保持为0,这里也是按照特定顺序对聚合的候选框voxel进行排列的。随后送入两个分支进行框评分以及修正。
与直接对点特征进行聚合相比,这里的part location聚合方法实现了局部信息以及全局信息的聚合,有效的学习到物体内部的空间分布信息,并且利用3d稀疏卷积节省了大量的计算量和参数量。同时,这里的置信度预测利用了soft label来进行交叉熵回归计算。如果iou>0.75,置信度的标签设置为1;iou<0.25,置信度标签设置为0;其余范围设置为2Iou-0.5(这里的iou是只候选框与GT的3d Iou计算)。
3.3 Overall loss
对于part-aware的损失主要包括三个部分:用于前景点分割的焦点损失、用于部分位置回归的二元交叉熵损失以及用于3D候选框生成的平滑L1损失
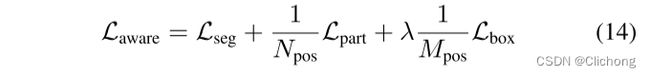
ps:其中对于3d候选框生成的损失Lbox中,对PartA2-free采用的是bin-based的框生成损失(bin-based box generation loss),对PartA2-anchor模型采用基于直接回归的框生成损失(residual-based box regression loss)。
对于part-aggregation的损失主要包括两个部分:候选框质量(objectness)回归的二元交叉熵损失项、用于3d候选框修正细化的平滑L1损失项
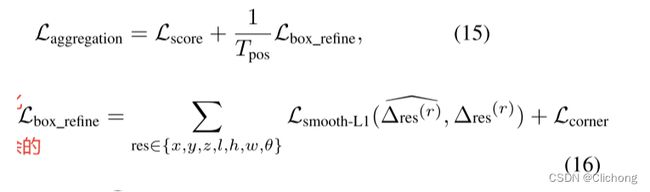
在第二阶段的损失函数中,还额外添加了8个角损失来进行正则化。虽然这种损失计算出来的信息是冗余的,但是是一种很好的正则化手段,在3DSSD中也使用上了这个附加损失,进实现更好的方向限制,提高准确率。(后续试验建议加上使用)此外,二阶段的方向损失不再需要新添加一个正负类别判断,而是直接回归即可,与PartA2-anchor稍有不同,这得益于iou评分的限制。
总的损失是以上两个阶段损失的叠加,如下所示:
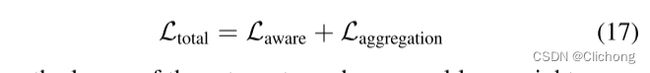
3.4 Date Augmentation
对于点云的3d检测常用的数据增强方法也就那几种,这里再一次总结如下:
1)Copypaste(将其他场景的点云粘贴在当前场景下,需要进行碰撞实验,避免重叠)
2)单独对GT进行旋转和平移
3)全局点进行全局旋转缩放与平移操作
3.5 Pros and cons
优点:
1)第一次考虑了标注框中点云的局部位置信息(也就是点分布信息)进行候选框特征的聚合
2)ROI-aware池化对候选框进行voxel化操纵,考虑所有voxel的信息以及几何空间位置(包括空体素以及非空体素),消除了候选框的模糊性问题
3)每个点所学习到的内部位置特征信息可以为其他任务进行拓展
缺点:
1)PartA2不能很好的拓展到室内场景的3d检测,因为3d边界框可能会存在重叠或者遮挡现象(比如桌子底下的凳子),因此室内场景的3d标注框不能提高精准的对象内部位置信息,存在模糊性
2)14FPS的推理速度远比不上PointPillar的62FPS,比SECOND的20FPS略差(认为FPS和HZ等价来进行比较),推理速度需要进一步优化以满足真实自动驾驶场景
4. 实验结果
整体实验结果如下所示:
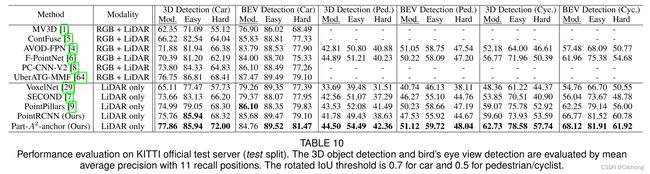
此外,PartA2中进行了详细的消融实验证明其有效性(下面只提及几个方面,其他内容详细看论文):
1)召回率测试:这里作者使用PointNet++与其所设计的SparseConvUNet进行对比,发现一样的anchor-free操作,SparseConvUNet得到的召回率较高;如果是anchor-based,其得到的召回率更高
2)RoI-aware Pooling的作用:对比了PointRCNN中的Pooling方法,效果提升不错
3)part-aware and aggregation是否起到了作用:作者通过去掉part locations prediction这部分,使用coordinates进行代替,效果变差,证明了part locations prediction的作用。作者通过去掉part-aggregation stage的部分,直接在part-aware stage的输出做预测,也就是把NMS加在了proposal上,效果对比不如在A2上的提升明显。
4)RoI pooling size:分的栅格约细,对于约难的问题处理约好,但对于简单的问题,可能会产生干扰。
5)soft label:在阶段二的置信度预测中使用了3d iou不同阈值设置不同的类别soft label,实验证明比普通的0/1硬标签在不同难易程度都带来了一定的提升(0.34%/0.66%/0.59%)
paper中需要注意,part locations prediction的回归是使用Cross Entropy Loss的,但这种回归的方式一般应该选用L1或者L2。此外,3d稀疏卷积能否进一步推理优化,改进PartA2的低推理速度的问题。