pytorch入门,resnet实现猫狗分类
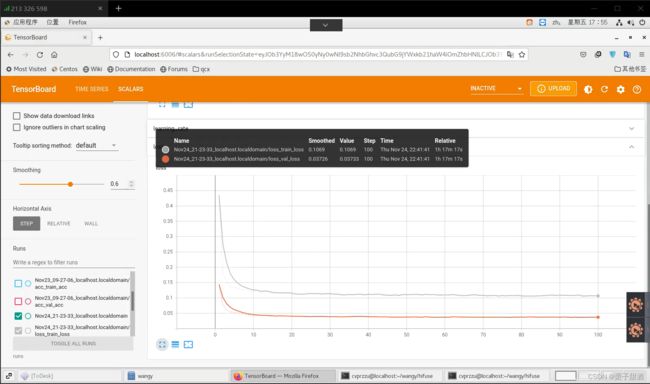
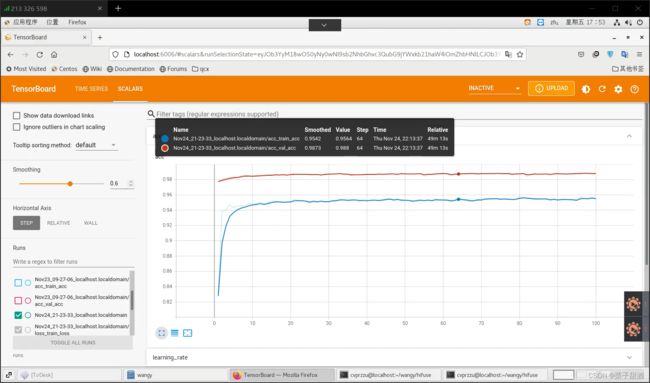
训练程序,获得最佳权重,loss、acc曲线
import os
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms, models
from utils import MyDataSet
from model_trans import densenet121 as creartmodel
from utils import read_train_data, read_val_data, create_lr_scheduler, get_params_groups, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
train_images_path, train_images_label = read_train_data(args.train_data_path)
val_images_path, val_images_label = read_val_data(args.val_data_path)
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
# transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = models.resnet50(num_classes=args.num_classes).to(device)
# model = creartmodel(num_classes=args.num_classes).to(device)
if args.RESUME == False:
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
# weights_dict = torch.load(args.weights, map_location=device)
#
# # Delete the weight of the relevant category
# for k in list(weights_dict.keys()):
# if "classifier" and "denseblock4" in k:
# del weights_dict[k]
# model.load_state_dict(weights_dict, strict=False)
pretext_model = torch.load(args.weights)
model2_dict = model.state_dict()
state_dict = {k: v for k, v in pretext_model.items() if k in model2_dict.keys() and 'fc' not in k}
model2_dict.update(state_dict)
model.load_state_dict(model2_dict)
if args.freeze_layers:
for name, para in model.named_parameters():
# All weights except head are frozen
if "fc" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
# pg = [p for p in model.parameters() if p.requires_grad]
pg = get_params_groups(model, weight_decay=args.wd)
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=args.wd)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs,
warmup=True, warmup_epochs=1)
best_acc = 0.
start_epoch = 0
if args.RESUME:
path_checkpoint = "./model_weight/checkpoint/ckpt_best_100.pth"
print("model continue train")
checkpoint = torch.load(path_checkpoint)
model.load_state_dict(checkpoint['net'])
optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch']
lr_scheduler.load_state_dict(checkpoint['lr_schedule'])
for epoch in range(start_epoch + 1, args.epochs + 1):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch,
lr_scheduler=lr_scheduler)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
# tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
# tb_writer.add_scalar(tags[0], train_loss, epoch)
# tb_writer.add_scalar(tags[1], train_acc, epoch)
# tb_writer.add_scalar(tags[2], val_loss, epoch)
# tb_writer.add_scalar(tags[3], val_acc, epoch)
# tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
tb_writer.add_scalars('loss', {'train_loss':train_loss,'val_loss':val_loss}, epoch)
tb_writer.add_scalars('acc', {'train_acc': train_acc, 'val_acc': val_acc}, epoch)
tb_writer.add_scalar('learning_rate',optimizer.param_groups[0]["lr"], epoch)
if best_acc < val_acc:
if not os.path.isdir("./model_weight"):
os.mkdir("./model_weight")
torch.save(model.state_dict(), "./model_weight/best_model.pth")
print("Saved epoch{} as new best model".format(epoch))
best_acc = val_acc
if epoch % 10 == 0:
print('epoch:', epoch)
print('learning rate:', optimizer.state_dict()['param_groups'][0]['lr'])
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_scheduler.state_dict()
}
if not os.path.isdir("./model_weight/checkpoint"):
os.mkdir("./model_weight/checkpoint")
torch.save(checkpoint, './model_weight/checkpoint/ckpt_best_%s.pth' % (str(epoch)))
#add loss, acc and lr into tensorboard
print("[epoch {}] accuracy: {}".format(epoch, round(val_acc, 3)))
total = sum([param.nelement() for param in model.parameters()])
print("Number of parameters: %.2fM" % (total/1e6))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=2)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--wd', type=float, default=1e-2)
parser.add_argument('--RESUME', type=bool, default=False)
parser.add_argument('--train_data_path', type=str, default="./data/train")
parser.add_argument('--val_data_path', type=str, default="./data/val")
parser.add_argument('--weights', type=str, default='pre-resnet50.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=True)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
#utils.py文件
import os
import sys
import json
import pickle
import random
import math
from PIL import Image
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
def read_train_data(root: str):
random.seed(0)
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
category = [cls for cls in os.listdir(root) if os.path.isdir(os.path.join(root, cls))]
category.sort()
class_indices = dict((k, v) for v, k in enumerate(category))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = []
train_images_label = []
supported = [".jpg", ".JPG", ".png", ".PNG"]
for cls in category:
cls_path = os.path.join(root, cls)
images = [os.path.join(root, cls, i) for i in os.listdir(cls_path)
if os.path.splitext(i)[-1] in supported]
image_class = class_indices[cls]
for img_path in images:
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images for training.".format(len(train_images_path)))
return train_images_path, train_images_label
def read_val_data(root: str):
random.seed(0)
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
category = [cls for cls in os.listdir(root) if os.path.isdir(os.path.join(root, cls))]
category.sort()
class_indices = dict((k, v) for v, k in enumerate(category))
val_images_path = []
val_images_label = []
supported = [".jpg", ".JPG", ".png", ".PNG"]
for cls in category:
cls_path = os.path.join(root, cls)
images = [os.path.join(root, cls, i) for i in os.listdir(cls_path)
if os.path.splitext(i)[-1] in supported]
image_class = class_indices[cls]
for img_path in images:
val_images_path.append(img_path)
val_images_label.append(image_class)
print("{} images for validation.".format(len(val_images_path)))
return val_images_path, val_images_label
def plot_data_loader_image(data_loader):
batch_size = data_loader.batch_size
plot_num = min(batch_size, 4)
json_path = './class_indices.json'
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
class_indices = json.load(json_file)
for data in data_loader:
images, labels = data
for i in range(plot_num):
# [C, H, W] -> [H, W, C]
img = images[i].numpy().transpose(1, 2, 0)
img = (img * [0.5, 0.5, 0.5] + [0.5, 0.5, 0.5]) * 255
label = labels[i].item()
plt.subplot(1, plot_num, i+1)
plt.xlabel(class_indices[str(label)])
plt.xticks([])
plt.yticks([])
plt.imshow(img.astype('uint8'))
plt.show()
def write_pickle(list_info: list, file_name: str):
with open(file_name, 'wb') as f:
pickle.dump(list_info, f)
def read_pickle(file_name: str) -> list:
with open(file_name, 'rb') as f:
info_list = pickle.load(f)
return info_list
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
accu_loss = torch.zeros(1).to(device)
accu_num = torch.zeros(1).to(device)
optimizer.zero_grad()
sample_num = 0
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}, lr: {:.5f}".format(
epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num,
optimizer.param_groups[0]["lr"]
)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
# update lr
lr_scheduler.step()
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
class MyDataSet(Dataset):
def __init__(self, images_path: list, images_class: list, transform=None):
self.images_path = images_path
self.images_class = images_class
self.transform = transform
def __len__(self):
return len(self.images_path)
def __getitem__(self, item):
img = Image.open(self.images_path[item])
if img.mode != 'RGB':
img = img.convert("RGB")
label = self.images_class[item]
if self.transform is not None:
img = self.transform(img)
return img, label
@staticmethod
def collate_fn(batch):
# https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
images, labels = tuple(zip(*batch))
images = torch.stack(images, dim=0)
labels = torch.as_tensor(labels)
return images, labels
@torch.no_grad()
def evaluate(model, data_loader, device, epoch):
loss_function = torch.nn.CrossEntropyLoss()
model.eval()
accu_num = torch.zeros(1).to(device)
accu_loss = torch.zeros(1).to(device)
sample_num = 0
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
accu_loss += loss
data_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(
epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num
)
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3,
end_factor=1e-2):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
return warmup_factor * (1 - alpha) + alpha
else:
current_step = (x - warmup_epochs * num_step)
cosine_steps = (epochs - warmup_epochs) * num_step
return ((1 + math.cos(current_step * math.pi / cosine_steps)) / 2) * (1 - end_factor) + end_factor
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
def get_params_groups(model: torch.nn.Module, weight_decay: float = 1e-5):
parameter_group_vars = {"decay": {"params": [], "weight_decay": weight_decay},
"no_decay": {"params": [], "weight_decay": 0.}}
parameter_group_names = {"decay": {"params": [], "weight_decay": weight_decay},
"no_decay": {"params": [], "weight_decay": 0.}}
for name, param in model.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias"):
group_name = "no_decay"
else:
group_name = "decay"
parameter_group_vars[group_name]["params"].append(param)
parameter_group_names[group_name]["params"].append(name)
# print("Param groups = %s" % json.dumps(parameter_group_names, indent=2))
return list(parameter_group_vars.values())
程序很正确,不知道为什么,结果很奇怪,我使用了kaggle猫狗数据集的20000张图片,数据集也不小,batch_size也很合理,结果欠拟合了,train的表现不如val,我用densenet也一样,不知道是什么问题