【论文阅读】LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions(WACV 2022)
LaMa: 基于傅立叶卷积的分辨率鲁棒的大掩模修复
图 1 本文提出的算法可以很好地修复遮挡面积较大的图像并且适用于各种图像,即使图像具有复杂的重复结构,本文的方法还可以推广到更高分辨率的图像上,即使我们是在 256x256 低分辨率图像上训练的。
文章目录
- LaMa: 基于傅立叶卷积的分辨率鲁棒的大掩模修复
-
- 速览
- 摘要
- 引言
- 方法
-
- 在浅层获取全局的上下文信息
- 损失函数
-
- 高感受野感知损失
- 最终的损失函数
- 训练集中的 mask 生成
- 实验
-
- 和基线模型对比
- 消融实验
- 推广到更高的分辨率
- 模型预告:Big LaMa
- 相关工作
- 讨论
速览
| 下载 | 收录 | 源码 | 机构 |
|---|---|---|---|
| arxiv | WACV 2022 | GitHub 4.2k PyTorch | 三星 AI |
@inproceedings{suvorov2022resolution,
title={Resolution-robust large mask inpainting with fourier convolutions},
author={Suvorov, Roman and Logacheva, Elizaveta and Mashikhin, Anton and Remizova, Anastasia and Ashukha, Arsenii and Silvestrov, Aleksei and Kong, Naejin and Goka, Harshith and Park, Kiwoong and Lempitsky, Victor},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={2149--2159},
year={2022}
}
摘要
- 问题描述:目前的图像修复算法在大块缺失区域、复杂几何结构以及高分辨率图像上的修复效果差强人意。
- 原因分析:在修复网络和损失函数都缺少有效的感受野。
- 解决方案: large mask inpainting(lama)
-
- 1)使用 fast Fourier convolutions(FFCs)以获取更大(wide)的感受野;
-
- 2)使用一个更大(high)感受野的 perceptual loss(感知损失);
-
- 3)训练的时候采用更大(large)的 mask 来验证前 2 步改进的效果。
- 实验结果:超过了以往的 SOTA 模型,鲁棒性更好(即使在比训练的分辨率 256x256 更高的图像上也有很好的效果),参数量和时间也更少。
关键字:图像修复(image inpainting), 大掩膜(large), 感受野(large mask), 傅里叶卷积(FFCs)
引言
首先,指出了图像修复问题的本质是尽可能真实地填补图像缺失部分,但要做到这一点需要 2 步,即先理解图像的大尺度结构,然后进行图像合成。
然后,介绍了训练图像修复模型的数据集是在真实图像上进行随机 mask 来产生的。
接着,指出了一个大的、有效的感受野对于理解图像全局结构的重要性,所以作者引进了 FFCs(让网络即使在浅层也拥有整个输入图像的全部感受野) 和 perceptual loss 来增大感受野。
最后,为了发挥大的感受野的优势,训练图像进行大面积的 mask。
方法
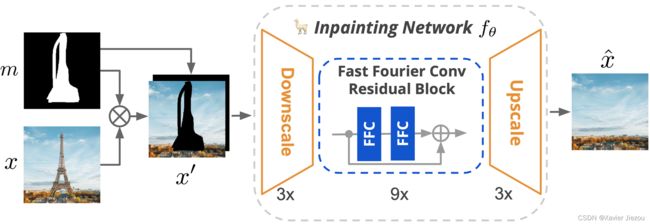
图 2 LaMa 是一个基于前馈 ResNet 类型的修复网络,它使用:最近提出的快速傅里叶卷积、一种结合了对抗损失和高感受野感知损失的多损失组合以及一个大掩膜生成程序。
在浅层获取全局的上下文信息
要想还原较大范围遮挡的图像,网络在浅层就应该获得更大的感受野。而目前的卷积模型,如 ResNet 的感受野增长是缓慢的。特别是对于大范围的遮挡,整个感受野可能都落在被遮挡的区域。
FFC 将通道划分为两个并行的分支:局部分支和全局分支。局部分支使用传统的卷积网络获取局部信息,全局分支使用 FFT(傅里叶变换)获取全局上下文信息,最终将这两个分支获得的输出进行融合。
损失函数
对于图像修复问题来说,损失函数的选取至关重要,特别是当被遮挡的区域很大时。
高感受野感知损失
原始的监督损失要求生成器尽可能地去还原 Ground Truth。但是当遮挡区域很大时,已有的可见区域的信息不足以还原,因此模型会做出很多摸棱两可的判断,从而导致模糊。
本文提出了 high receptive field perceptual loss(HRF PL),利用一个基本的预训练模型来评估预测图和目标图之间的距离。因为针对 large mask 的修复问题的重点是理解图像的全局结构,因此不需要精确的还原,允许有一定的变化。
预训练模型的选取也很重要,分割模型会关注图像的高级语义信息,而分离模型可能会更关注图像的纹理。
最终的损失函数
最终的损失函数是对 HRF PL 和其他几个损失函数(包括对抗损失)的融合。
训练集中的 mask 生成
训练模型时采用了一种激进的 large mask 生成策略,随机生成遮挡面积较大的 wide 或 box 遮挡。

图 3 来自不同训练 mask 生成策略的样例。作者认为 mask 生成方式会极大地影响最终的修复效果。
实验结果表明,使用 large mask 策略会提高模型的性能,无论是在 narrow 亦或是 wide mask 上进行评估。
实验
- 网络:模型的网络框架是 GAN,主体网络结构是 ResNet,其中加入了 FFC。
- 数据集:Place 和 CelebAHQ。
- 评估指标:FID 和 LPIPS(相比于 L1 和 L2 距离,这些指标更适合评估 large mask 的修复效果)。
和基线模型对比
优于绝大多数的模型,指标好的没本文算法的参数量少,参数量少的没本文算法指标好。

表 1 本文算法在公开数据集上的定量评估。
当然,也做了用户调研,调研的结果也是比其他 SOTA 模型要好的。
消融实验
感受野:对比傅里叶卷积、传统卷积和膨胀卷积发现,傅里叶卷积因为感受野的缘故在 wide mask 上能有效提高 FID 和 LPIPS,尤其在重复结构上表现好,且可以迁移到比训练图像更高分辨率的图像上。
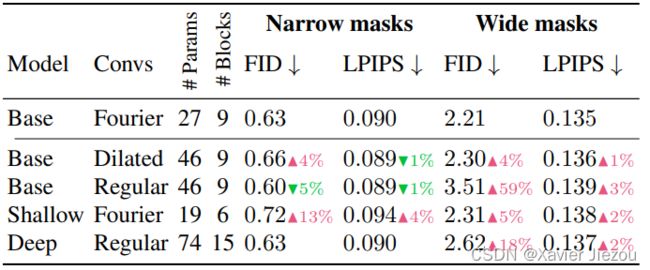
表 2 在其他组件保持不变的情况下,不同 LaMa 架构的性能。基于 FFC 的模型在窄掩模上可能会牺牲一点性能,但在宽掩模上明显优于具有常规卷积的较大模型。
图 4 在 512x512 的图像上各种修复算法的对比结果。FFCs 能够很好的生成重复的结构,例如玻璃和铁丝网。

图 5 将修复模型迁移到更高分辨率的图像上。随着分辨率的提高,基于传统卷积的模型开始产生致命的伪影,而基于 FFC 的模型继续生成精细的语义一致的图像。
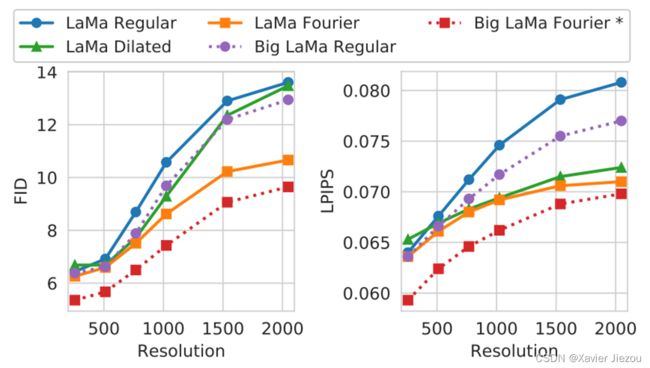
图 6 基于 FFC 的修复模型可以迁移到在训练中从未见过的更高分辨率的图像上,质量倒退明显更小。
损失函数:作者验证了通过膨胀卷积实现的感受野感知损失确实能够提高修复质量。

表 3 LaMa-Regular 在不同的感知损失函数上训练的结果对比。
掩膜生成策略:更宽的训练掩膜在窄或宽的掩膜上都能提高修复质量。

表 4 使用窄掩模或宽掩模训练不同修复方法的性能指标。
推广到更高的分辨率
直接在高分辨率图像上训练很慢,并且计算成本也很昂贵,但大多数的现实世界的图像编辑场景需要修复算法能够在高分辨率上 work。
基于 FFC 的模型能够很好地迁移到高分辨率上。我们认为 FFC 模型在不同尺度下具有鲁棒性是因为如下三点原因:
- 1)wide-image 感受野
- 2)尺度改变后仍然保留了频谱的低频
- 3)1×1 卷积在频域中的 inherent scale equivariance
模型预告:Big LaMa
为了验证我们的算法对真实高分辨率图像的拓展性和适用性,我们训练了一个大的名为 Big LaMa-Fourier 模型,相比 LaMa-Fourier 模型,它使用的生成器的深度更深,使用更大的数据集和 batch size。
相关工作
首先,介绍了深度学习前的图像修复算法和基于深度学习(特别是卷积神经网络)的图像修复方法。
接着,指出了获取局部和全局信息对于图像修复网络的重要性,也介绍了前人在这方面的一些研究。我们的研究证实了远距离位置之间信息有效传播的重要性。我们方法的一个变体严重依赖于 dilated convolutional blocks。作为更好的替代方案,我们提出了一种基于频域变换(FFC)的机制。这也符合最近在计算机视觉中使用 Transformers 的趋势,并将傅立叶变换视为自注意力的轻量级替代。
然后,从更宏观的角度发现很多前人的算法都是基于两步走的策略,而本文指出了一步也能实现很好的效果。
此外,我们还发现只要训练掩膜的外形足够丰富,掩膜生成的确切方式不如掩膜的宽度重要。
最后,介绍了在图像修复网络中常用的损失函数,包括有 pixel-wise 损失、对抗损失、 WGAN 损失、以及感知损失等。本文发现这些损失都不是最优的,并提出了一个更好的替换方案。
讨论
主要贡献:
本文中,实现了简单的 single-stage 方法来修复 large-mask。并被证明是图像修复领域的 SOTA 模型,并给出了框架实现、损失函数以及训练图像生成策略,而且在比较难的修复问题上(比如重复的结构)也表现好。
图 7 LaMa 在重复结构上的修复示例图。
不足之处:
- LaMa 在透视失真和复杂背景上表现不好;
- FFC 是否能够解释周期信号的这些变形仍然是一个问题;
- 除傅里叶和膨胀卷积外,还有其他能够获取高感受野的方案比如 ViT。