彻底看懂RNN,LSTM,GRU,用数学原理解释梯度消失或者梯度爆炸
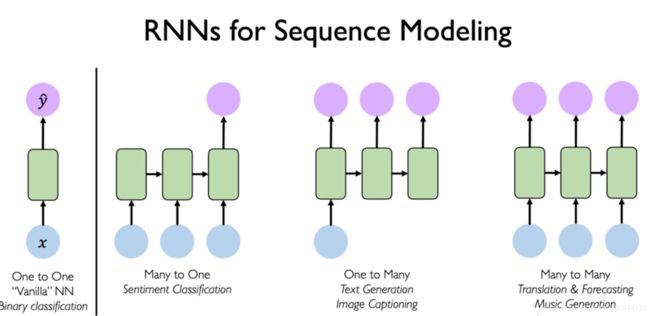
Recurrent Neutral Network
章节
- RNN概述
- LSTM
- GRU
- 梯度困区
- Seq2Seq模型
- 何去何从
- 模型之外
RNN概述
为什么它叫做递归神经网络呢?与其他网络有何不同?接下来用简单例子阐述:
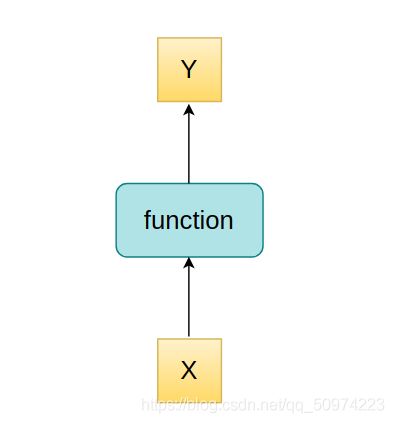
这是比较简单的示意图,比如说一个网络只有一层,那么,那一层代表的函数方法就是这个网络实际对输入所起的作用,即Y = Funtion(X),我们实际上想找出那个function它究竟是什么。
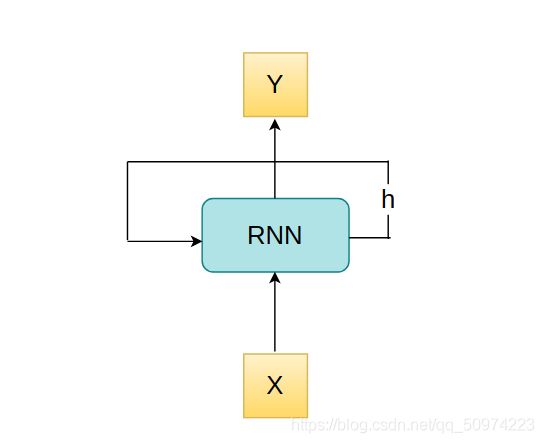
可以从下图看出,RNN得到一个输出不仅仅靠输入的X,同时还依赖于h,h在RNN中被叫做cell state,那么h如何得出呢?由公式(1)可知,h_t是由h_(t-1)经过某种函数变换得到的,换句话说,我要得到目前这一个的,我还必须经过前一个才能做到。这里我们可以类比一下斐波那契数列,f(t) = f(t-1) + f(t-2),某一项需要由前两项一起才能完成,RNN是某一个h需要前面一个h来完成,这也是为什么被叫做递归神经网络。顺带一提,这里的function有权重参数,即为W,而这个W是共享的,意思是无论是h_1到h2还是h_2到h_3,它们用的function其实是一样的。
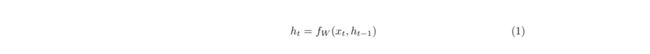
所以,复杂一点的RNN长这样:
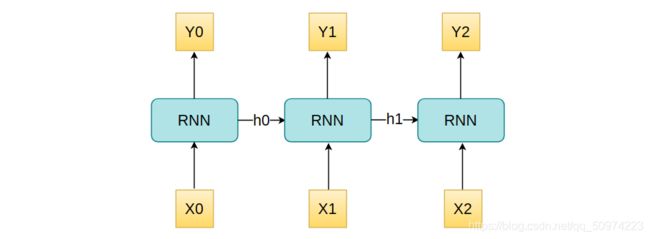
每次输出完一个y,它同时还会有一个h出来,作为下一层的参数一起使用。从这一点来看,RNN跟其他网络不同的一点是前一层的输出同时可以作为后一层的输入,经过一层就会更新一次h,那么,h究竟是如何更新的呢?tanh是一种常用的激活函数,可见Activation。
![]()
y_t可以由此得出:
![]()
从上述公式中可以看出有不同的W,即不同的权重矩阵,这些矩阵是机器自己去从数据中去学出来,同时也可以是人为设置的。注意,这些不同类之间的矩阵不同,但是如果说是同一个function,那么权重矩阵都是共享的。
传统的DNN,CNN的输入和输出都是固定的向量,而RNN与这些网络的最大不同点是它的输入和输出都是不定长的,具体因不同任务而定。
LSTM
LSTM和GRU比较有创新的一点就是采用了门结构来控制整个模型,既然是门,那就可以打开和关闭,如何定义打开还是关闭呢?我们用sigmoid来完成这一点,如果经过sigmoid函数的值越接近0,受到重视的程度就越低,相当于门正在慢慢关闭,越接近于1呢,受到重视的程度就越高,相当于门正在慢慢打开,下面把LSTM切分为不同的门结构来讲。
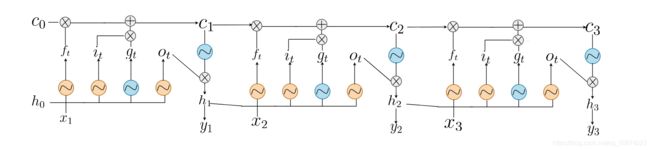
我相信你一开始看到这个图是一脸懵逼的,接下来我带你手撕LSTM
- Forget Gate
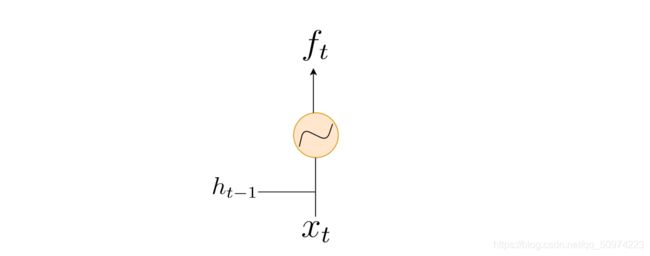
其中两个W都是权重矩阵,两个b都是截距,是通过机器去不断学出来的,下文出现的W和b虽然具体内容不同,但是代表的意思是一样的。忘记门决定了哪些信息是重要的,如果是不重要的我们就直接选择遗忘,是LSTM中较为核心的一点。
![]()
- Input Gate
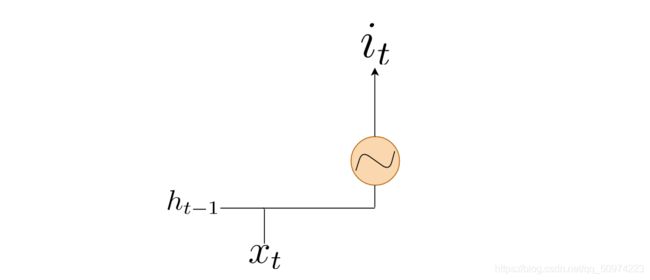
![]()
- Cell Gate
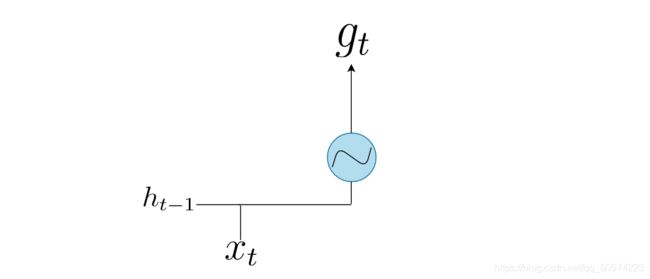
需要注意的是,这里的激活函数换成了tanh。
![]()
- Cell State
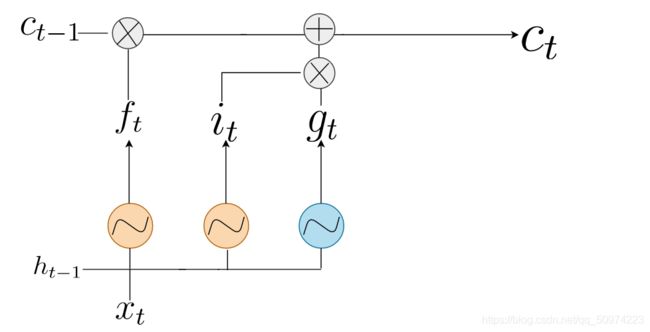
![]()
式子分为两部分,前一部分是说前面的cell state有哪些需要保留,哪些需要遗忘,cell gate用来暂存需要补充到新的c_t的内容。两者相加,便完成了cell state的更新了。其实为什么叫cell state——细胞状态,在我看来,不妨从细胞膜的选择透过性来说,这里c_t的更新不是上一部分直接拿上来就用,而是进行选择性录入,跟物质运送到细胞内有异曲同工之妙。
同时你会发现整个LSTM很大一部分都是围绕着Cell State展开的,那些门间接在保护或者过滤输出,至于为什么LSTM能缓解梯度消失以及维持一个较为稳定的梯度流,可以在梯度困区中找到答案,下一节会具体比对RNN和LSTM。
注意这里的是哈达玛积(Hadamard product),是对应位置元素相乘。
- Output Gate

![]()
- Hidden State
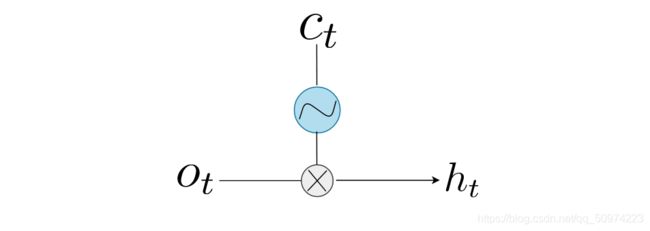
![]()
最后我们完成LSTM一层的搭建

叠加三层就长成了一开始的样子:
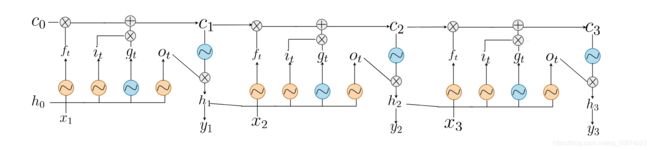
梯度困区
RNN通过Hidden State(h_t)路径完成梯度流动:
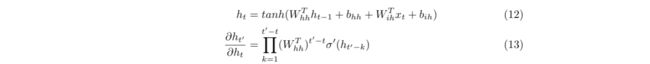
由上式易得,权重矩阵和激活函数很容易对RNN的梯度造成不可逆的影响,关于sigmoid函数为什么会导致梯度下降问题,建议去BackPropagation中的梯度消失部分一看究竟,这里不再细说。其实最重要的不是激活函数,对梯度传播真正起决定作用的是权重矩阵,因为随着梯度的传播过程,乘以权重矩阵的指数倍,换句话说,若权重矩阵里都是比较小的数,那么,梯度就会指数性下降;同样地,如果权重矩阵里都是比较大的数,那么,梯度就会指数性上升。
所以,对RNN梯度下降以及梯度爆炸问题,可以从这两个角度进行切入。
- 梯度初始化
我们可以初始化权重矩阵使之变为正交矩阵,最简单的初始方法就是使权重矩阵变为单位阵(Identity Matrix),这样随着梯度不断的流动,可以缓解指数性上升或者下降的问题。
- 切换激活函数
因为sigmoid会导致梯度下降,所以我们可以切换激活函数如RELU或者RELU的变种,如Leaky RELU。
另外针对梯度爆炸问题,可以采用梯度削减(Gradient Clipping):
首先设置一个clip_gradient作为梯度阈值,然后按照往常一样求出各个梯度,不一样的是,我们没有立马进行更新,而是求出这些梯度的L2范数,注意这里的L2范数与岭回归中的L2惩罚项不一样,前者求平方和之后开根号而后者不需要开根号。如果L2范数大于设置好的clip_gradient,则求clip_gradient除以L2范数,然后把除好的结果乘上原来的梯度完成更新。当梯度很大的时候,作为分母的结果就会很小,那么乘上原来的梯度,整个值就会变小,从而可以有效地控制梯度的范围。有一点疑惑的就是,梯度削减会使得原来的梯度过大的部分发生变化,方向既然发生了变化,为什么最后还能使得loss收敛呢?Deep Learning大概结果反推出解释吧。
当然了,上面这些措施只能是稍作改变,不痛不痒。
为了更好地缓解这些问题,LSTM被提了出来,结构已经介绍过了,其实LSTM绝对不能解决上述梯度问题,最多进行缓解,它可以在一条路径上保持较为稳定的梯度流——Cell State(c_t),其他的路径上同样会有梯度消失的问题,与RNN的原因一样,换句话说,LSTM通过维持一条高速公路来拯救其他路径(公式里的V_t+k代表着f_t里面的输入)。另外,虽然LSTM有高速公路,但仍然不能处理很长距离的句子,说起LSTM的名字也很有趣,Long Short-Term Network,其实只是比较长的短期网络啦,并不是真正能处理很长距离的句子。
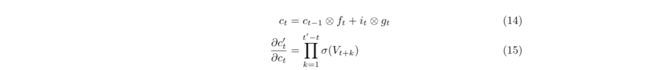
LSTM可以学习到权重矩阵使得sigmoid出来的值接近于1,因而更好地缓解了梯度下降以及梯度爆炸的问题。
GRU
其实LSTM是对RNN的改良升级,相对于LSTM来说,门结构变少,即参数量变少,训练起来速度更快,在实际任务中与LSTM相差无几,所以2014年提出之后就逐渐变得流行起来,当然啦,实际任务中肯定两个都训练,择优录取(下图选自于斯坦福大学CS224N系列课程,这里用n_t代替h_t加波浪符,为了书写方便)。
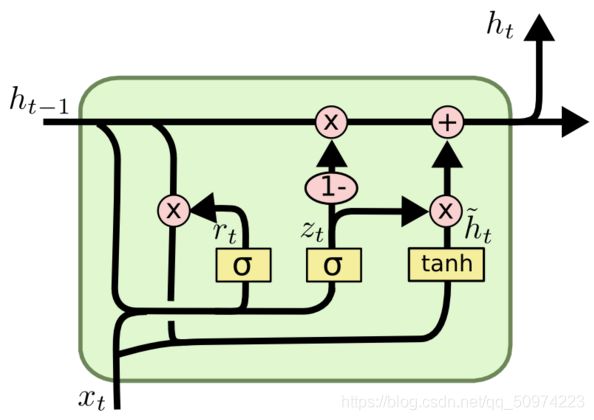
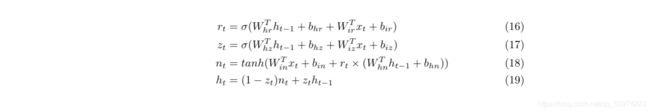
r_t被叫做重置门(Reset Gate),z_t被叫做更新门(Update Gate)。整个模型的思路是拿到h_t-1和x_t之后,先把重置门和更新门进行更新一下,然后用r_t重置掉h_t-1里的一些内容,再加上x_t,暂存到n_t里面。最后用z_t决定要以多大的比例将暂存的和旧的放到新的h_t里面进行更新。
Seq2Seq模型
由于无法同时多项任务,人们通常在实际任务中采用多个RNN,比如最有名的seq2seq模型,用多个RNN充当编码器(Encoder),再用多个RNN充当解码器(Decoder)。Seq2Seq模型其实是序列入,序列出模型,比较常见的是机器翻译,比如我们今天要把中文翻译成英语,那么编码器进入的是中文的序列,解码器出来的是英文的序列。
如何训练呢?首先是Encoder端,用以将序列转换为向量并且提取有效特征,具体来说,每一个时间步长输入多少长度的序列其实是未知的,经过LSTM会转换为(h,c),直到Encoder端结束输入,最后的状态(h_,c_)作为Decoder的起始状态,记为s_0,Decoder端的第一个输入是[CLS]表示开始,接下来凭借Encoder端的输入开始输出翻译后的结果,翻译完一个之后,它会预测下一个可能是什么,把它转换为向量,向量里面是每一个词的可能性,因为这是监督学习,我们把德语的标签同样转换为向量,然后计算两者之间的交叉熵损失(Cross-Entropy),进而优化我们的损失函数(以下图仍选自CS224N)。
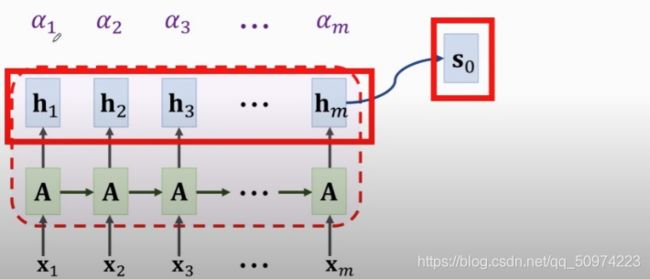
由于RNN缺乏处理长距离信息的能力,人们提出了注意力机制用以提高它的表现。加了注意力机制的seq2seq模型,这里讲一下与transformer一致的注意力机制。首先有两个矩阵W_k和W_q,一个表示为要被查的(Key),一个表示去查的(Query),具体可以看Transformer。用s_0和h_i去乘以矩阵q以及k,得到结果后两者做内积,最后用softmax归一化得到关系向量,这样一开始的s_0大概就知道跟哪个最接近,大大增加了翻译的准确度。

何去何从
尽管RNN以及它的变种十分强大,但是由于无法并行运算,计算成本高等原因,最终还是避免不了逐渐退出主流的命运,当然,如果想要取代它,至少在我看来目前是不可能的,CNN就是一个例子。可能我们看到具体模型名字如RNN,LSTM的机会少了,但是这些模型的内涵逐渐被人们挖掘并加以提升,如LSTM的“高速公路”设置与ResNet以及Transformer中残差相连的方式有异曲同工之妙。seq2seq模型中的注意力机制被Google沿袭,这才有了Attention is all your need这篇论文。
学习老的旧的模型你可以花的精力不多,但是它的灵魂之处你一定要明白,旧模型不是让你去抛弃的,而是用来培养你的某种直觉。你学习模型的时候应当把自己代入当时的历史角色,你面对什么问题,踩了什么坑,为什么会想到这个模型,如果你不求甚解,可能觉得模型凭空产生,可是你越了解某个模型,就越觉得它处理某类问题其实是很自然而然的。
Transformer那篇论文有很多厉害的点,但其实那些厉害的小点在那些所谓的老模型中或多或少都会有映射,旧模型是用以培养某种直觉,或许能够在新问题上大放异彩。
模型之外
The purpose of computing is insight, not numbers. —— Richard Hamming.
很多时候,直觉(Intuition)和洞察力(Insight)是最重要的,做算法,不是只会调参,看看结果然后瞎编,而是遇到某类新问题,你有一种感觉,感觉往那个方向做是正确的。就像RNN,说不定有些Transformer至上者觉得RNN这些一无是处,殊不知前者是站在后者的肩膀上才有了今天的高度。学会以学模型的方式来训练自己的直觉和洞察力是很重要的。著名数学家拉马努金的故事甚至超越小说,他没有受过数学的教育,只通过一本数学教科书,还是比较老的那种,通过他自己的一步一步推导,他能够从公式推导的过程中汲取灵感,培养直觉,才最终建立起自己的数学宇宙。
其实爱因斯坦的伟大之处就在于他能够设置某种场景的假设,虽然听起来有点站不住脚,也没有严密的数学论证,但那恰恰是很多伟大理论的开端。
Less sure about everything. —— Steve Jobs
学习模型,很多时候看教程或者视频老师并不会每一个点都会给你讲透,在他看来都是理所当然的,或许他自己也不求甚解,但如果想真正成为了解模型的少数人,不要觉得一切都是理所当然的,学会寻找好的问题,而且越是简单的就越值得思考,比如说很少有人会问为什么掰手指会响,1971年数学家提出猜想,到如今斯坦福大学博士生用数学方式模拟出结果,一定程度上还只是验证了“气泡溃灭说”,并发表在环球科学杂志上,还没有确切说解决,你觉得这个问题简单吗?
用心去观察,提问这件事,多多益善,越是简单,越是理所当然的,就越要弄明白。
有了问题,就去做出假设,然后去验证,得出结论。学会像科学家一样思考。
在我学RNN的过程中,很多我以前都是不求甚解,糊里糊涂,但通过问问题,寻找答案,独立思考最终找到了较为合理的答案,这个过程是很美妙,很令人激动的。了解某类模型就像是主线任务,一个一个小问题就像是支线,引领你前往魔法森林,The Question Is A Gift!
万物互联。
其实看到LSTM的cell state我想到了细胞膜的选择透过性,看到Gate其实我想到了以前看过的一篇英语文章,大概作者的亲人逝去了,作者很难过,然后最后想开了:我们要打开一扇门,把坏情绪留在门后,进入一扇门就蜕变成新的自己,迎接新的世界,这其实跟LSTM通过门来选择性记忆也有神似之处。
当我们一开始学的时候,知识是某一个点,学的多了,发现有些知识有重合之处,几个点就可以连成线,再往后学,发现自己把某个领域学过了,就成了一个面,再往后学,就发现那些不同的面构成了一个立体的世界。学的知识越多,你拥有的维度越多,思考问题的角度也就越多,启发式算法就是从不同角度思考算法问题,从而提出较为优美的解决方案。一切都是联系着的。
公式是钥匙。
不要看到公式就感觉像是结束键,公式只是答案之门的钥匙,你转动的方式会决定你看到的内容,学会演绎公式,解释公式,联系现实将公式代入,你会获得完全不一样的体验。
觉得写的好的可以去GitHub,那里有我写的机器学习和深度学习系列教程,不定时更新,另外还有一些免费优质学习资源。如果有问题要交流,也欢迎加我的微信Yunpengtai 来交流。