VggNet
经典分类网络:VggNet
一、网络概述
VGG可以看成是加深版的AlexNet,和AlexNet不同的是,VGG中使⽤的都是⼩尺⼨的卷
积核(3×3)
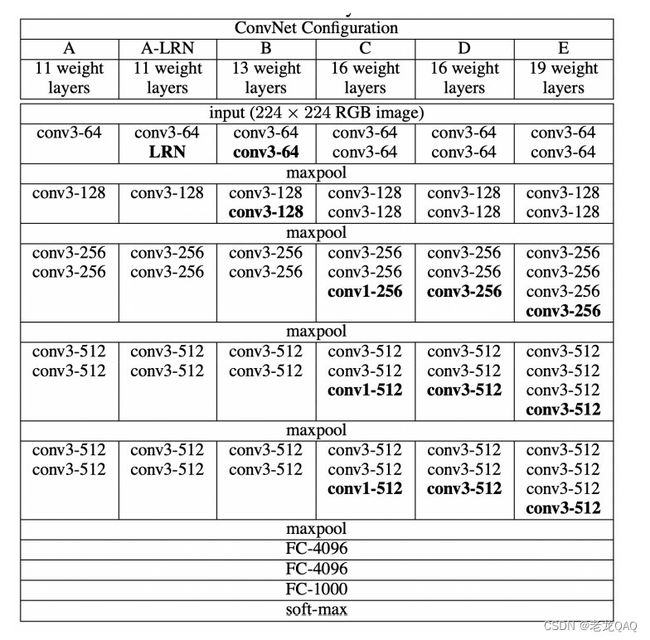
自定义VggNet
from torchvision import models
import torch
from torch import nn
from torch.nn import functional as F
class VggNet(nn.Module):
"""
自定义Vgg网络
"""
def __init__(self):
super(VggNet, self).__init__()
# 提取特征
self.features = nn.Sequential(
# stage1
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage2
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage3
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage4
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# stage5
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
# maxpool
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
# 修正形状
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7, 7))
# 做分类
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Flatten(),
nn.Linear(in_features=25088, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1000)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
o = self.classifier(x)
return o
vgg = VggNet()
X = torch.randn(8, 3, 224, 224)
y = vgg(X)
y.shape
# output:torch.Size([8, 1000])