经典网络VGGNet介绍
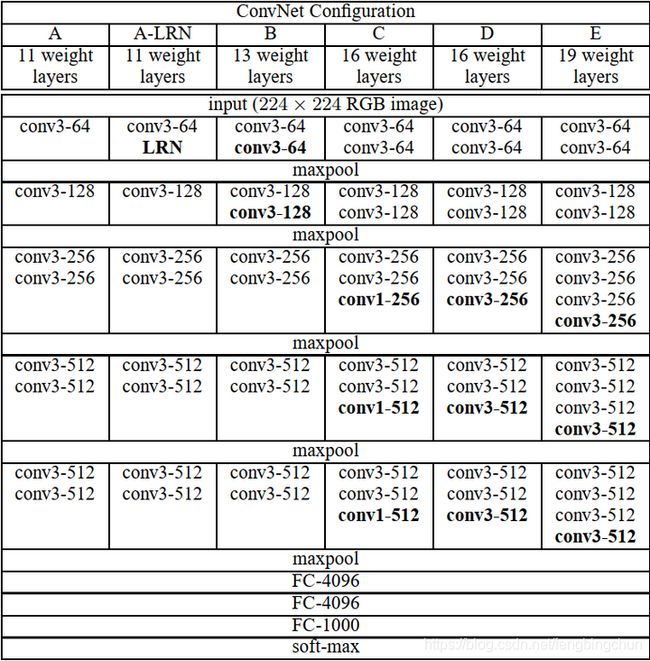
经典网络VGGNet(其中VGG为Visual Geometry Group)由Karen Simonyan等于2014年提出,论文名为《Very Deep Convolutional Networks for Large-Scale Image Recognition》,论文见:https://arxiv.org/pdf/1409.1556.pdf,网络结构如下图所示,其中D和E即为VGG-16和VGG-19:
下图是来自https://neurohive.io/en/popular-networks/vgg16/ 中VGG-16架构的截图:

VGG-16(13个卷积层+3个全连接层)与VGG-19(16个卷积层+3个全连接层)的区别:每个卷积层后跟ReLU
(1).VGG-16:2个卷积层+Max Pooling+2个卷积层+Max Pooling+3个卷积层+Max Pooling+3个卷积层+Max Pooling+3个卷积层+Max Pooling+3个全连接层。
(2).VGG-19:2个卷积层+Max Pooling+2个卷积层+Max Pooling+4个卷积层+Max Pooling+4个卷积层+Max Pooling+4个卷积层+Max Pooling+3个全连接层。
假如输入图像大小为n*n,过滤器(filter)为f*f,padding为p,步长(stride)为s,则输出大小为:如果商不是整数,向下取整,即floor函数。参考:https://blog.csdn.net/fengbingchun/article/details/80262495

VGGNet网络证明了增加网络深度有利于分类精度,使错误率下降。VGGNet模型应用到其它图像数据集上泛化性也很好。
VGGNet网络:
(1).结构简洁:卷积层+ReLU、最大池化层、全连接层、Softmax输出层。
(2).使用连续几个较小卷积核(3*3)替换AlexNet中的较大卷积核且采用same padding(即p=(f-1)/2),既减少参数,又进行了更多的非线性映射,可以增加网络的拟合能力。分为5段卷积,每段包括2至4卷积层。
(3).最大池化,小池化核(2*2),stride为2。
(4).通道数即feature maps数逐渐翻倍增加,使得更多的信息可以被提取出来。
(5).训练时将同一张图像缩放到不同的大小,在随机裁剪到224*224大小以及随机水平翻转,增加训练数据量。
(6).在测试阶段,将3个全连接层替换为3个卷积层,这样输入层可以接收任意宽或高的图像。
VGG-16架构:13个卷积层+3个全连接层,predict时对各层进行说明,参照:https://github.com/fengbingchun/Caffe_Test/blob/master/test_data/Net/VGG-16/vgg-16_deploy.prototxt
(1).输入层(Input):图像大小为224*224*3。
(2).卷积层1+ReLU:使用64个3*3的filter,stride为1,padding为1,输出为224*224*64,64个feature maps,训练参数(3*3*3*64)+64=1792。
(3).卷积层2+ReLU:使用64个3*3的filter,stride为1,padding为1,输出为224*224*64,64个feature maps,训练参数(3*3*64*64)+64=36928。
(4).最大池化层:filter为2*2,stride为2,padding为0,输出为112*112*64,64个feature maps。
(5).卷积层3+ReLU:使用128个3*3的filter,stride为1,padding为1,输出为112*112*128,128个feature maps,训练参数(3*3*64*128)+128=73856。
(6).卷积层4+ReLU:使用128个3*3的filter,stride为1,padding为1,输出为112*112*128,128个feature maps,训练参数(3*3*128*128)+128=147584。
(7). 最大池化层:filter为2*2,stride为2,padding为0,输出为56*56*128,128个feature maps。
(8).卷积层5+ReLU:使用256个3*3的filter,stride为1,padding为1,输出为56*56*256,256个feature maps,训练参数(3*3*128*256)+256=295168。
(9).卷积层6+ReLU:使用256个3*3的filter,stride为1,padding为1,输出为56*56*256,256个feature maps,训练参数(3*3*256*256)+256=590080。
(10).卷积层7+ReLU:使用256个3*3的filter,stride为1,padding为1,输出为56*56*256,256个feature maps,训练参数(3*3*256*256)+256=590080。
(11). 最大池化层:filter为2*2,stride为2,padding为0,输出为28*28*256,256个feature maps。
(12).卷积层8+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为28*28*512,512个feature maps,训练参数(3*3*256*512)+512=1180160。
(13).卷积层9+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为28*28*512,512个feature maps,训练参数(3*3*512*512)+512=2359808。
(14).卷积层10+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为28*28*512,512个feature maps,训练参数(3*3*512*512)+512=2359808。
(15). 最大池化层:filter为2*2,stride为2,padding为0,输出为14*14*512,512个feature maps。
(16).卷积层11+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为14*14*512,512个feature maps,训练参数(3*3*512*512)+512=2359808。
(17).卷积层12+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为14*14*512,512个feature maps,训练参数(3*3*512*512)+512=2359808。
(18).卷积层13+ReLU:使用512个3*3的filter,stride为1,padding为1,输出为14*14*512,512个feature maps,训练参数(3*3*512*512)+512=2359808。
(19). 最大池化层:filter为2*2,stride为2,padding为0,输出为7*7*512,512个feature maps。
(20).全连接层1+ReLU+Dropout:有4096个神经元或4096个feature maps,训练参数(7*7*512)*4096=102760488。
(21). 全连接层2+ReLU+Dropout:有4096个神经元或4096个feature maps,训练参数4096*4096=16777216。
(22). 全连接层3:有1000个神经元或1000个feature maps,训练参数4096*1000=4096000。
(23).输出层(Softmax):输出识别结果,看它究竟是1000个可能类别中的哪一个。
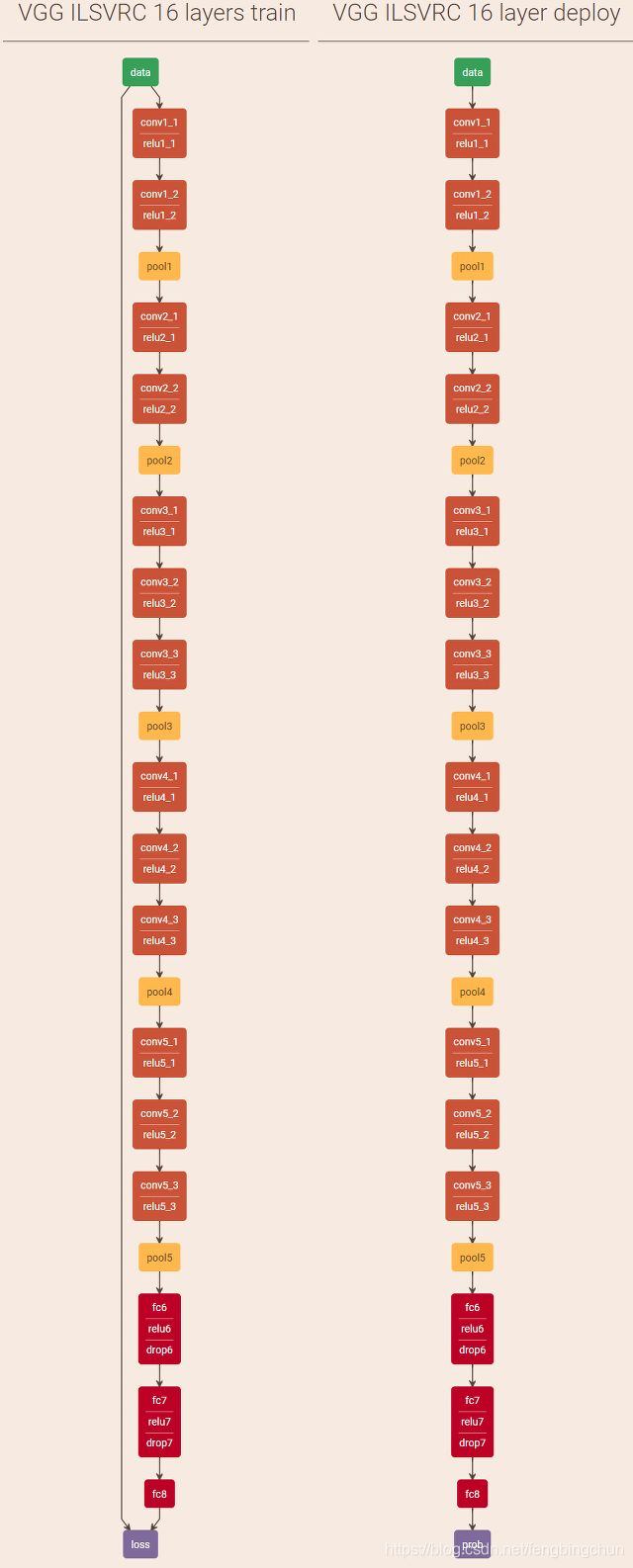
train和predict的可视化结果如下图所示:
GitHub:https://github.com/fengbingchun/NN_Test