C# 学习笔记入门篇(上)
文章目录
- C# 学习笔记入门篇
-
- 〇、写在前面
-
- Hello World!
- 这篇学习笔记适合什么人
- 这篇学习笔记到底想记什么
- 附加说明
- 一、命名空间
-
- “进入”命名空间
- 嵌套的命名空间、分立的命名空间
- 习题
- 习题答案
- 二、类与面向对象
-
- 相关概念
- 在 C# 中定义类
- 静态方法,程序入口
- 习题
- 三、变量
-
- 其实已经学过变量了
- 基本数据类型
- 大家都是类
- 表达式计算
- 从控制台输入
- 上节习题答案
- 习题
- 四、编写方法
-
- 其实已经学过如何编写方法了
- 表达式主体方法
- 上节习题答案
- 习题
- 五、顺序结构、选择结构
-
- 其实已经学过顺序结构了
- 选择结构之 `if` 语句
- 布尔值
- 布尔值,必须是布尔值
- 选择结构之 `switch` 语句
- 变量的作用域
- 上节习题答案
- 习题
- 六、循环结构
-
- 背背背背背背背起了行囊
- 先背一个行囊再说
- `for` 循环
- 更复杂的循环逻辑
- 上节习题答案
- 习题
- 七、C# 对象模型(一)
-
- 我没有对象,但为什么我要研究对象模型
- 经典的内存模型
- 栈,甜蜜的栈?
- 寸土寸金
- 你看这堆它又长又宽——引用类型
- 新世界
- 栈,甜蜜的栈!——结构体
- 新せかい
- shì jiè 与せかい的统一
- 上节习题答案
- 习题
- 八、数组(一)
-
- 海纳百川,有容乃大
- 对象模型,数组验之
-
- 数组元素的初始化
- 数组元素的内存模型
- 为数组中的每个元素赋值
- 数组元素,循环遍之
- 多维数组
- 数组的数组
- 上节习题答案
- 习题
- 九、C# 对象模型(二)
-
- 窥豹一斑,具体而微——接上回
- 彼唱此和,此唱彼和——`ref` 关键字
-
- \*\*`ref` 关键字的 C++ 对应
- 深入浅出,浅入深出——`out` 关键字
- 动中有静,静中有动——`const` 关键字、字面量、枚举,`readonly` 关键字
-
- `const` 关键字、字面量、枚举
- `readonly` 关键字
- \*\*`const` 关键字与 `readonly` 关键字的 C++ 对应
- 色即是空,空即是色——`null` 关键字与可空类型
- 上节习题答案
- 习题
- 第八章答案
-
- 1. 初始化数组的部分元素
- 2. 模 `2^64` 剩余系
- 3. 丢番图难题
- 4. 逆序数
- 5. 约瑟夫问题
- 6. 幻方问题
- 7. 有限元法
- 8. 杨辉三角
C# 学习笔记入门篇
〇、写在前面
Hello World!
子曰:“君子不器。”以此言开头,似乎我想表达对大家再多学一门编程语言的期望,因为此言的翻译是:
君子不能像器皿一样(只有一种用途)。1
但事实上我只是想感叹下自然语言的高深罢了,毕竟,这句话又能被翻译为:
君子不应拘泥于手段而不思考其背后的目的。2
相较于自然语言,采用上下文无关文法的编程语言则简单很多。下面的程序展示了 “Hello World!” 程序在 C# 中的写法;不得不承认,它真的很简单。
using System;
namespace HelloWorld
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
}
}
}
简单到什么程度,只需要在 Visual Studio 新建一个 C# 控制台项目,即可自动生成以上代码,真可谓“信手拈来”!读者可能会不屑,亦或会不解,这篇学习笔记到底想记什么?下面听我娓娓道来。
这篇学习笔记适合什么人
在我的 Python 学习笔记入门篇中,写道:
适合我。
不适合什么都不会的人。适合很会 C++ (C++ 11 及以上版本)的,熟悉基础算法的,了解部分高级数据结构的,有一定 C++ 开发经验的,熟悉计算机基本知识的,不会 Python 的人。
此后我回忆,这实在是太苛刻了!所以对于这篇笔记,我希望面向的读者是:
- 我。
- 很会 C++(C++ 20 及以上版本)的,熟悉基础算法的,了解部分高级数据结构的,有一定 C++ 开发经验的,熟悉计算机基本知识的,不会 C# 的人。
- 完全不会编程的人。但需要会至少两门自然语言。
但这又对我苛责许多!所以,我恳求读者在必要时高抬贵手,指出我的错误和不妥。
这篇学习笔记到底想记什么
我们的主角是 C# 语言本身,所以这篇学习笔记记录:
- C# 的词法、语法、语义。
- C# 程序对应的小标题(如“程序 0:你好,世界!”)。
这篇笔记基本不涉及:
- C# 开发环境的配置与选择。
- C# 项目开发技巧。
- ……
看到这儿,想要学习 C# 读者应该会疑惑:我应该跟着这篇学习笔记学习 C# 吗?我的建议是:不。我更希望读者能够将读这篇学习笔记作为一种消遣——哪怕看完后什么也没有学会,但还记得开头的“君子不器”,不也是一种“君子不器”吗?
附加说明
主要参考资料:
- 菜鸟教程:C# 教程
- 《Visual C# 从入门到精通》(第 9 版),John Sharp 著,周靖 译,清华大学出版社
本笔记在 bilibili 和 CSDN 上同步更新。需要注意两平台上的版权差异:
- bilibili:未经允许,禁止转载。勘误以评论的形式进行。
- CSDN:遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和声明。勘误以直接重新发布的形式进行。
就这样吧。
一、命名空间
命名空间(namespace)好似一个容器,将不同来源、不同用途、乃至不同作者的代码分门别类地存放起来。在逻辑层面上,命名空间的用途仅此而已。
C# 允许代码存在于命名空间之外,这和 C++ 一样,不过无论是在 C# 还是在 C++ 中都不推荐这么做!
class 自由人 { }
namespace 阴暗的角落
{
class 老六
{
static void Main(string[] args)
{
}
}
}
程序 1 中,命名空间“阴暗的角落”把类“老六”收纳了起来,这让我们知道:想要找到(使用)“老六”,必须要想办法“进入”“阴暗的角落”。
我们之后再来看什么是类。
Tip: 已经掌握 C++ 的读者,是否感觉写得太水了呢?对于有 C++ 基础的读者,请在之后的内容中关注与 C++ 的对比,而对新手而言,请跳过。无论如何,最有效的学习方法总是和编译器打交道,而不是和我!
“进入”命名空间
有两种方法“进入”命名空间:
- 你已经在命名空间中了,尽情地享用吧!
- 使用
using语句“使用命名空间”。
Tip: 被
括起来的内容表示行内代码。
// using 阴暗的角落; // 我们这里不用它。
class 自由人 // 不推荐在命名空间外中定义类。
{
static void 试试看()
{
new 阴暗的角落.老六();
}
}
namespace 阴暗的角落
{
using System;
class ななみ
{
static void Try()
{
new 老六();
}
}
class 老六
{
static void Main(string[] args)
{
/* System. */Console.WriteLine("鲨");
}
}
}
从程序 2 中可以看到,如果你在一个命名空间外,又想调用其中的东西,那么你有两种方法。你可以用 namespace.something 达到目的,也可以在当前命名空间中提前 using 那个命名空间。
本小节到此为止的信息量其实已经相当大了,见下面的总结。
-
C# 的注释格式与 C++ 完全相同。
使用//(双斜线)书写行内注释。
使用/* ... */书写块状注释。
注释是代码的精髓,可以使用注释说明代码的作用、细节等。注释总是被编译器完全忽视,不会对真正的代码产生影响。 -
C# 的语句需要以分号结尾。
路过的乞丐提醒程序员少了一个分号的笑话中,程序员用的语言可能是 C#,但这个程序员估计是在用记事本写代码,不推荐。 -
“使用命名空间”这一概念总是存在于某一命名空间中。
using语句只能在命名空间的开头使用(或者在命名空间外的最开头使用),如果前面已经有namespace或者class了,后面就不能有using了。即,using语句仅能存在于源文件开头,或紧接在某个namespace后。
此处,‘using’ 语句等同于 C++ 中的using namespace,不同于 C++ 中的using! -
C# 在根本上支持 Unicode。
程序 1 和程序 2 都是可以真正运行的,即使其中含有大量非英文的字符!在控制台中也是可以正常输出中文的。 -
C# 中,可以在前面使用后面的内容!
C++ 只能在后面使用前面的内容,但程序 2 完全说明了:C# 可以在前面使用后面的内容;尽管ななみ在前面,她仍然能看到后面的老六!
Tip: 无论是代码中还是总结中有看不懂的内容,都可以跳过。这不会影响你对命名空间的理解!
嵌套的命名空间、分立的命名空间
namespace n1
{
namespace n2
{
class A // 1. 嵌套的命名空间使用方法:n1.n2.A
{ }
}
namespace n2
{
using System; // 2. using 语句仅在这个大括号内有效。
class B { }
}
namespace n2
{
// class A { } // 3. 错误:不能重复定义。
}
}
namespace n1.n2 // 4. 一次性嵌套。
{
class C
{
static void Main(string[] args)
{
}
}
}
习题
还是留一点习题作为思考吧。带 * 的内容表示选做,带 ** 的内容供有基础的读者选做,带 *** 的内容会具有相当的挑战性。
- *安装 Visual Studio,新建一个 C# 控制台项目,粘贴程序 1、2、3,生成并运行。尝试修改代码并使得程序仍然能成功生成。在修改代码的过程中你能感受到写代码比默写古诗文简单吗?
**在修改代码的过程中你能感受到写 C# 比写 C++ 简单吗? - 在命名空间
n1中存在类クラス,在命名空间n2中也存在类クラス。根据命名空间存在的意义,n1.クラス和n2.クラス必然是不同的两个类。但是,如果在 n2 中使用了using n1;,会发生什么?
*编写程序验证你的想法。 - 在命名空间
n1中存在命名空间n2和n3,如果想要在n2中使用(using)n3,应该怎样写?
*编写程序验证你的想法。 - *程序 2 中,
class后面显然表示一个名字。能够把其中的名字ななみ修改为七海Nana7mi吗?能够把它修改为7七海ななみ吗?
在 Visual Studio 中验证这个问题。
习题答案
仅供参考。
- 可以使用微软给亲儿子 C# 提供的 IntelliSense。
- 不会报错。直接写
クラス表示n2.クラス。即使写了using n1;,也必须写n1.クラス表示n1中的クラス。 - 直接在
n2中写using n3;即可。也可以写using n1.n3。 - 可以。不能。
二、类与面向对象
相关概念
程序 0、1、2、3 中的 class 便是类。类(class)不完全等同于类型(type),那它到底是是什么呢?下面的图示说明了面向对象程序设计的理念,而类则是面向对象程序设计中的重要概念。

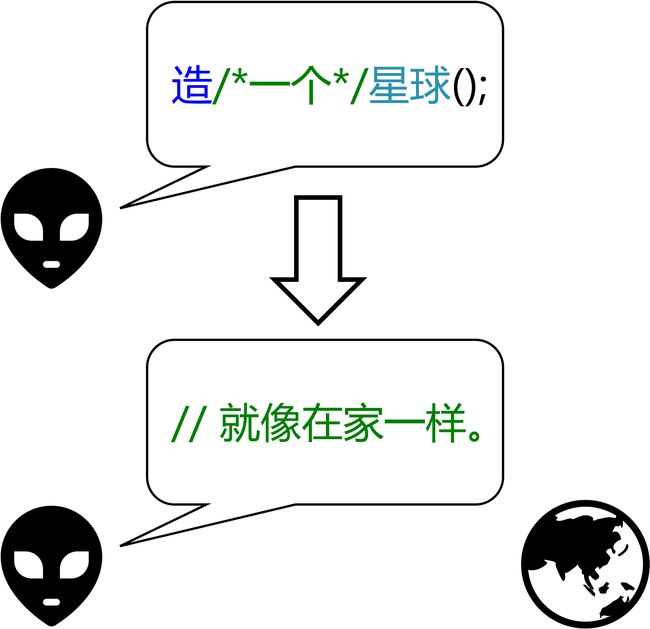
图《I’m 外星人》中,星球便是一个类,而这地球是类的一个实例(instance),也称为一个对象(object)。一个类可以“造”出任意多个实例,比如上图中星球类就造出了两个球,这两个球可能不同,但它们都属于星球类。
面向对象编程的精髓在于,你写程序的思路是“让某个对象做某事”,有别于面向过程的“自己设计整套流程做事”。面向对象的好处是可以将不同类隔离开来:图中的白外星人不需要知道地球是不是毁得很冲动(),它只需要让地球毁灭吧()即可;如果你想让地球晒干了沉默()后再毁得很冲动(),你只需要修改星球类的代码。
事实上,图中,“外星人”也是一个类,而“白外星人”和“黑外星人”是“外星人”的两个实例,或者说它们是两个“外星人”对象。
它们都属于外星人,凭什么一个烦,一个感到就像在家一样?让我们解剖下这两个外星人对象。
Tip: 一个不严谨的地方在于,注释是不会被执行的。这里我们假设图中的注释是一种补充说明,写的是这两个外星人的真实情况。

对象由数据和方法(method) 组成。白外星人和黑外星人都可以表达自己的情绪,“表达情绪”是外星人共有的方法。而不同的外星人可以有不同的数据,可以处于不同的状态,自然可以表达不同的情绪了。
不同于 C++,C# 是一门完全面向对象的程序,所以熟悉以上《I’m 外星人》的模型是很有必要的。如果你坚持要使用 C++,也请多多地面向对象哦。


在 C# 中定义类
让我们直接尝试使用 C# 复刻《I’m 外星人》的一个小片段。
Tip: 每一份代码中总会出现我不会在现在解释的新东西,我只能尽量使得这些新东西是通过已出现的代码依葫芦画瓢尝试出来的。代码中标有 * 的注释适合初学者思考,标有 ** 的注释适合有 C++ 基础的读者思考。
class 外星人
{
public string 颜色; // *什么是 public?
public void 表达情绪() // *为什么没有 static 了?*void 又是什么意思?
{
if (颜色 == "黑") { /* 感觉像家一样 */ } // *什么是 if?*这个颜色是谁的颜色?
else if (颜色 == "白") { 烦 = true; } // *什么是 else if?
}
bool 烦; // *为什么没有 public?*什么是 bool?
}
class 小剧场
{
static void Main(string[] args)
{
var 黑外星人 = new 外星人(); // **什么是 var?**为什么要 new?
var 白外星人 = new 外星人();
黑外星人.颜色 = "黑"; // 必须亲自给外星人化妆。*为什么?
白外星人.颜色 = "白";
白外星人.表达情绪();
黑外星人.表达情绪();
}
}
暂且不表程序 4 中的一系列问号,我们做一个总结。
- C# 中,定义类的方法为
class 类名 { /* 数据与方法 */ },注意,与 C++ 不同,C++ 定义类的方法为class 类名 { /* 数据与方法 */ };,多一个分号! - C# 中,要让某个对象执行某个方法,请写
对象.方法()。 - C# 中,要访问某个对象的某个数据,请写
对象.数据。
Tip: 并不是所有的方法和数据都能让你直接执行或访问:外星人可不一定允许你把它的大脑完全解剖,不然你就是外星人专家了,这不会让你很累吗?事实上,程序 4 中之所以我们可以访问
颜色数据并执行表达情绪(),是因为它们是public的,第一个问号被回答了。
静态方法,程序入口
没错,我们来回答第二个问号:什么是 static?如果类的某个方法用 static 修饰了,那就表明这个方法属于这个类本身,而与属于这个类的对象无关,称这个方法为一个静态方法。例如,程序 4 中,表达情绪是某个外星人的行为,但如果我想汇报外星人的人口,这就不是某个外星人的事儿了。然而,因为汇报外星人的人口与“外星人”类显然是紧密相关的,所以我们可以将汇报人口设计为一个静态方法。
public static void 汇报人口()
{
// ...
}
其中 public 的作用是允许在类的外部使用这个方法。要使用静态方法,一个显然的想法是写 外星人.汇报人口()。
Tip: C++ 中允许写成
白外星人.汇报人口()或黑外星人.汇报人口(),但 C# 中不行。请始终写成类.静态方法()。
到此为止,我们可以来审视 Main 了。程序 0、1、2、3、4 中,Main 都是某个类(但不限定是哪个类) 的一个静态方法,并且我们默认程序从 Main 开始运行,我们称 Main 是程序的入口。一般地,一个程序总是从入口开始运行;当入口中的所有内容结束后,程序终止。
C# 中,必须存在且仅存在一个类拥有名为 Main 的静态方法。它将作为整个程序的入口。这个类可以位于任一命名空间中。
Main 后面的 string[] args 是一系列字符串,事实上它们是程序的命令行参数。相关的内容我们暂时不提,就这样吧。
习题
- *从程序 0 到 4 中任选一个程序,将
Main后面括号内的string[] args删除,思考会发生什么?
*上机实践验证你的猜想。
*将Main后面括号内的string[] args修改为string[] args1, string[] args2,思考会发生什么?
*上机实践验证你的猜想。 - ***只使用程序 0 到 4 中出现过的知识点编写程序,输出
****。要求能够只修改源代码中的一个字符使得新程序的输出为7777。要求使用面向对象的思路实现。 - 思考如何实现
外星人.汇报人口()。
答案于下一节公布。
三、变量
其实已经学过变量了
程序 4(见上节)中,我们见到了以下语句。
public string 颜色; // *什么是 public?
var 黑外星人 = new 外星人(); // **什么是 var?**为什么要 new?
显然,第一条语句说明了外星人类中应当有“颜色”这一数据。第二条语句字面上表示我们造了一个外星人。两者的共同点是,它们都声明了一个用于存放数据的容器。不同的是,前者只是一种说明,说明每个属于外星人类的对象都需要这样的一份数据,而后者则实实在在地生成了一份容器。
我们称这种存放数据的容器为变量。顾名思义,变量是可变的,程序 4 中的以下语句即体现了这一性质。
黑外星人.颜色 = "黑"; // 必须亲自给外星人化妆。*为什么?
该语句是赋值语句,将黑外星人的颜色进行了改变。
Tip: 这条赋值语句不仅改变了
颜色变量,也改变了黑外星人变量。
基本数据类型
C# 中存在一系列基本数据类型(直译为基元数据类型,primitive data type),它们包含整数、浮点数、布尔值(即逻辑值,只能是真或假)、字符、字符串。
using System;
class Program
{
static void Main()
{
int win = 810975;
int lose = 922768;
long win_and_loss;
win_and_loss = (long)win * lose;
string tip = "赢了,但又输了: ";
Console.WriteLine(tip + win_and_loss);
}
}
程序 5 出现了三种基本数据类型:int、long、string,分别代表 32 位整数、64 位整数、UTF-16 字符串。从语法上看,C# 与 C++ 很类似,下面做一个总结:
- C# 中,使用
类型 变量名;语句声明一个变量。
变量遵循先声明,后使用的原则。要使用一个变量,必须先在前面声明它。 - C# 中,使用
变量名 = 值;语句为变量赋值。赋值语句的意思是,在计算出值后,将变量名代表的变量修改为这个值。 - C# 中,使用
类型 变量名 = 值;语句声明一个变量,同时给这个变量赋值。
对变量的首次赋值称为赋初值。C# 中遵循先赋初值,后使用的原则。要将变量用于除赋值外的用途,必须保证这个变量已经被赋初值。例如,程序 5 中,如果删去win_and_loss = (long)win * lose;,则程序不能通过编译,因为之后用到了tip + win_and_loss。 - C# 中,使用
((类型)值)表达式将值转换为指定类型。这与 C++ 中 C 风格的类型转换语法相同。在语法上 C# 只支持这一种转换方式,意即,C# 不支持 C++ 中类型(值)这样的类型转换。
类型转换的作用不言而喻。程序 5 中,如果不进行类型转换,win * loss就超出了int的范围(-2147483648~2147483647)。 - C# 中,支持一些 C++ 中不支持的隐式类型转换。程序 5 中
string加上long时long会首先隐式转换为string,而两个字符串相加意味着字符串的连接,所以运行结果为赢了,但又输了: 748341778800。
Tip: 不是说使用
类型 变量名;声明变量吗?为什么程序 4 中写的是var 变量名 = new 类型();?之后我们将看到两者的不同。目前,请仿照程序 5 进行编程。程序 4 是乱写的!
还有好些基本数据类型没有被展示出来。没关系,如果你是新手,你完全可以在需要时自行搜索。
大家都是类
我们认为,可变的类的实例(即可变的对象)是一个变量,即使这个类不包含任何数据(如一个空的类)。但反过来对吗?对 C# 而言,任何变量都是对象。
using System;
class Program
{
static void Main()
{
float a_floating_point = 1; // 发生 int 到 float 因式类型转换。
var a_string = a_floating_point.ToString(); // 有数据,有方法,就是对象。
Console.WriteLine(a_string);
}
}
Tip:
ToString方法不是把a_floating_point变成string,而是得到一个新的string。一个类型确定的变量一旦声明,其类型不再发生改变。
Tip: 综合程序 4、6,可以看出
var可能等效于 C++ 中的auto,即自动推导定义时所赋初值的类型并将其设为变量的类型。事实的确如此,所以要注意,var不是动态类型,仍然是一个固定的类型,只是编译器帮我们推导了。
表达式计算
这太简单了,只是一些加减乘除罢了。
using System;
class Program
{
static void Main()
{
var iiyo_koiyo = long.Parse("114514") * (114514 * (11 - 4 + 5 / 1 - 4) + (114 * 514 + (114 * 51 * 4 + (1 + 145 * 14 + (1 - 14 + 5 + 14)))));
Console.WriteLine(iiyo_koiyo);
}
}
运行结果:
114514114514
Tip: 给你的变量取个好名字,
iiyo_koiyo这个名字就不错,至少能够通过编译。不好的名字是无法通过编译的,例如7七海ななみ,我们已经见过这个例子了。
Tip: 搞不清楚先算谁后算谁?加括号就行了!
我们更应该关注运算符的运算规则。
using System;
class Program
{
static void Main()
{
Console.WriteLine(4 / 3);
Console.WriteLine(-4 / 3);
Console.WriteLine(4 / -3);
Console.WriteLine(-4 / -3);
Console.WriteLine(4.0 / 3);
Console.WriteLine(4 / 3.0);
Console.WriteLine(4 % 3);
Console.WriteLine(-4 % 3);
Console.WriteLine(4 % -3);
Console.WriteLine(-4 % -3);
Console.WriteLine(4.1 % 3.0);
Console.WriteLine(-4.1 % 3.0);
Console.WriteLine(4.1 % -3.0);
Console.WriteLine(-4.1 % -3.0);
}
}
运行结果:
1
-1
-1
1
1.3333333333333333
1.3333333333333333
1
-1
1
-1
1.0999999999999996
-1.0999999999999996
1.0999999999999996
-1.0999999999999996
这么大的运算量,看上去一定一头雾水吧。下面我来替大家做个总结:
- C# 中,
/的含义由语境决定,与 C++ 相同。当两侧都是整数时,/表示整数除法;当存在一侧是浮点数时,/表示浮点数除法,不是浮点数的操作数将会被转换为浮点数。 - C# 中,
/和%是向零取整,与 C++ 相同。换句话说,/运算的符号满足“同号为正异号为负”,%运算的符号与被除数的符号相同。 - C# 中,
%运算符支持浮点数,结果的符号与被除数相同。
Tip: C# 和 C++ 很像,又多了好多便捷的功能,所以如果你会 C++ 的话 C# 会很简单。
从控制台输入
下面是我们的第一个具有输入和输出的真正的实用化程序。
using System;
class Program
{
static void Main()
{
var a = long.Parse(Console.ReadLine());
var b = long.Parse(Console.ReadLine());
Console.WriteLine(a + b + 7);
}
}
运行时,输入:
1
1
运行结果:
9
Tip: 不要输入
1 1,一定要换行!仔细理解程序⑨中 ReadLine 的含义。
可见,想要进行输入,我们只需要让控制台对象去读一行就行了。这正是面向对象的思路。
Tip:
Console果真是一个对象?不同于 C++ 中的cin,cout,Console实际上是一个类,ReadLine等方法都是静态方法。不过第一眼把Console认成对象也无妨。
上节习题答案
- 什么也不会发生。会编译出错。
- 略。
思路:设计一个类,其中保存一个字符(char),表示要输出的字符,提供一个连续输出 4 个该字符的方法;在程序入口处创建对象,为该字符赋初值,然后调用提供的方法即可。 - 保存一个外星人相关的数据,即外星人的数量。汇报人口时直接使用这个数量。当新建外星人时,将这个数量加一,当外星人死亡时,将这个数量减一。
注意这个题目没有要求你写 C# 程序,只是叫你思考,所以不是选做题。
习题
- C# 中,如果一个基本数据类型变量没有初始化就被使用,会发生什么?
*编写程序验证你的想法。
**C++ 中这个问题的答案又是什么?
**编写程序验证你的想法。 - 从程序 5 到 9 总结出
var的作用及注意事项?
*编写程序验证你的想法。 - 计算
a * b的 C# 程序应该怎么写?其中a和b都是输入的浮点数。提示:程序 7 和程序 9 中都用到了类型.Parse方法。
*上机编写程序。 - ***程序 7 中的那个表达式是怎么生成的?编写程序生成那样的表达式。
四、编写方法
其实已经学过如何编写方法了
程序 4 中,我们写道:
public void 表达情绪() // *为什么没有 static 了?*void 又是什么意思?
{
if (颜色 == "黑") { /* 感觉像家一样 */ } // *什么是 if?*这个颜色是谁的颜色?
else if (颜色 == "白") { 烦 = true; } // *什么是 else if?
}
每一个程序中,我们都有一个静态方法 Main。
static void Main(string[] args)
{
// ...
}
它们都是方法(method)!在学习了变量后,我们可以提炼出方法的语法。
(public) (static) 类型名 方法名(参数列表) { 方法的实现 }
其中的类型名表示方法的返回值的类型。若方法没有返回值,则请在类型名处写 void。
Tip: 在 C++ 中,我们称方法为成员函数,称静态方法为静态成员函数,而不属于任何类的函数(function) 我们就直呼其名了。如果你接受函数这个名字,就能理解何为返回值了:返回值是函数的运算结果。用 C# 的话说,返回值是方法的运算结果。
在方法中,使用 return 语句返回。
using System;
class Program
{
public static int my_method(int a, int b)
{
int mul = a * b;
return mul % 10;
}
static void Main()
{
Console.WriteLine(my_method(9, 9));
}
}
程序 10 中,my_method(9, 9) 运算的结果是 1,而这个 1 由 return mul % 10; 语句产生。可见,返回值是由 return 语句产生的,且语法为:
return 返回值;
方法一旦返回,就运算结束了。 如果一个方法没有返回值,则 return 语句也可以被使用,此时 return 语句的作用只是结束这个方法的工作。
class Program
{
static void vacation() { return; }
static void holiday() { }
static void Main()
{
vacation();
holiday();
}
}
程序 11 中,vacation 和 holiday 是完全等价的。对于 void 型方法(即没有返回值的方法),可以认为大括号结尾自动有一个 return; 语句。而对于非 void 型方法,返回语句绝不能省略。
表达式主体方法
咱的 C++ 又要出来溜达了。
int my_function(int a, int b)
{
return a * b % 10;
}
int main() {}
C++ 说:“我的 my_function 比程序 10 中的 my_method 更简单。”但事实上,在 C# 中,我们还能更上一层楼。
class Program
{
public static int my_method(int a, int b)
=> a * b % 10;
static void Main() { }
}
这样的写法省略了大括号和 return,但功能上与程序 10 的 my_method 完全一致。对于只返回一个表达式的方法,可以用这种表达式主体方法提高代码可读性。
Tip: C# 中额外的空格和空行对代码的语义不产生任何影响,所以程序 12 中的
my_method可以写在同一行内。甚至整个程序都能写在一行以内(见程序 13)!
class Program { public static int my_method(int a, int b) => a * b % 10; static void Main() { } }
不要把 C# 中的表达式主体方法与 C++ 中的推导指引弄混。虽然它们都使用一个长得很像的箭头符号指向一句很短的代码。
template<class T>
my_class(T, T) -> my_class<T>; // 当构造函数的参数类型为 (T, T) 时,my_class 的模板参数取 T。
Tip: 觉得自己会 C++,但从来没见过上面这样的推导指引?没关系,这是 C++17 新增的内容。
我们暂时只涉及这一点点关于方法的知识。目前这点内容足够大家写一个顺序执行的完整程序了。
上节习题答案
- 会编译错误。
C++ 中不一定会编译错误,取决于编译器实现。对于 MSVC,能够判断简单的情况,抛出编译错误。但如果骗过了编译器,则在 Debug 模式下未初始化的变量填充 0xcc(仅为了便于调试),在 Release 模式下行为未定义。
注:C# 不像 C++,如果没有特殊的技巧,是难以骗过 C# 编译器的。 - 事实上在 Tip 中已经说明。强调一点,必须在声明变量的同时初始化,不能先声明变量,再初始化。
- 见“习题答案 3-3”。
- 请参见 https://github.com/itorr/homo/blob/master/homo.js
using System;
class Program
{
static void Main(string[] args)
{
var a = float.Parse(Console.ReadLine());
var b = float.Parse(Console.ReadLine());
Console.WriteLine(a * b);
}
}
习题
之后,上机编写程序的习题会逐渐增多,所以上机的选做符号将被省略。如果不愿意上机或无法上机,思考如何编写程序即可。
- 编写一个方法,计算
a的 4 次方,其中a是整数。同时编写一个计算整数的 4 次方的完整程序,输入一行一个整数,输出运算结果。(建议上机实践,你能发现哪些问题?) - 编写一个方法,输入为两个字符串,将这两个字符串用逗号连接作为输出。例如,输入为
"我不做人了"、"JOJO"时,输出为"我不做人了,JOJO"。编写完整程序验证你的方法的是否被正确编写。 - 读习题程序 4-3。回答:
++current是什么意思?请查阅相关教程,自学“自增自减运算符”。- 程序的运行结果是什么?如何理解“函数(function)”这一概念,它与数学中的函数不同在哪儿?
using System;
class counter
{
public int current;
public int increase()
{
return ++current;
}
}
class Program
{
static void Main(string[] args)
{
var my_counter = new counter();
my_counter.current = 0;
Console.WriteLine(my_counter.increase());
Console.WriteLine(my_counter.increase());
}
}
五、顺序结构、选择结构
其实已经学过顺序结构了
每一个程序中,我们都有一个静态方法 Main。
static void Main(string[] args)
{
// ...
}
虽然没有明说,但是我们默认了代码是从上往下执行的。这是因为冯诺依曼结构计算机具有顺序执行的特点,如下图所示。

图中,IP 是指令指针寄存器,保存了下一步将要执行的代码在内存中的位置。之所以我们说代码存在于内存中,是因为冯诺依曼结构计算机还具有程序存储的特点,而图中的“Main 中”二字则表示,下面的方格是 Main 方法的程序在内存中的(示意)结构。
按冯诺依曼结构计算机顺序执行的特点进行工作,当执行完 vacation 时,就应当执行紧挨着的 holiday。像这样的简单程序结构被我们称为顺序结构。
总结:顺序结构在 C# 中就是从上往下写代码。
选择结构之 if 语句
但很快我们就发现了问题:图中,我们使用了方法 vacation(),那首先就应该执行 vacation() 内的代码,而图中直接省略了这一步,跳到了 vacation() 完全执行完毕的样子。事实上,这正是图中 “step over” 的含义所在,我们直接跳过了执行内部代码的示意。
Tip: 图中称 “step over” 为“单步执行”,是因为在调试器古老的翻译中就是如此。现在 Visual Studio 对 “step over” 的翻译是“逐过程”。
如果想要进入到vacation()中,应该选择 “step into”,现在的翻译是“逐语句”,古老的翻译是“单步进入”。
那么,vacation 和 holiday 的执行是完全顺序的吗?显然不是。例如,如果我们写:
vacation();
vacation();
// ... 重复 100 个。
我们不可能把 vacation 方法的代码堆叠 100 次以强制实现顺序执行。另外,如果要实现复杂的逻辑,很容易发现不可能以完全顺序的方式完成。例如,如果要计算 1 + 2 + ... + 1000000,我们难道要写成:
class Program
{
static void Main(string[] args)
{
long a = 0; // 注意必须是 long,为什么?
a += 1; // 等价于 a = a + 1;
a += 2;
// ... 省略 999997 行。
a += 1000000;
}
}
此时,计算机的强大体现在指令指针寄存器 IP 可以跳转(jump),它可以在任何时候跳到任何地方,然后继续执行;当然,在现代 CPU 中,跳转必须是“合法的”,不然就闪退、死机、蓝屏!借由跳转,我们可以构造出两种基础的程序结构,即选择结构和循环结构。
如果你学习过高中数学,那你对顺序结构、选择结构、循环结构一定不陌生,毕竟高考要考,所以我们直接进入 C#。在 C# 中,选择结构主要通过 if 语句实现。
using System;
class Program
{
static void Main(string[] args)
{
var 是否礼貌 = Console.ReadLine();
if (是否礼貌 == "是")
Console.WriteLine("ありがとうございます!");
if (是否礼貌 == "否")
Console.WriteLine("パカ!");
}
}
程序 15 中,分别输入"是"和"否",你将得到两个不同的回答,而当输入别的内容时,你将得不到任何输出。
如果我们假设一个人没有回答是,他就一定不是礼貌的,应该怎么用 C# 表达这份含义?程序 16 展示了 if-else 语句的使用方法。
using System;
class Program
{
static void Main(string[] args)
{
var 是否礼貌 = Console.ReadLine();
if (是否礼貌 == "是")
Console.WriteLine("ありがとうございます!");
else
{ // 当有不止一条语句时,必须用大括号括起来。
Console.WriteLine("パカ!");
Console.WriteLine("パカ!");
}
}
}
但对于这个问题,更好的写法是,在 else 中再次判断变量是否礼貌,以防回答"我礼貌"的人被误伤。如果要在 else 中紧挨着使用 if 语句进行判断,可以简写为 else if。程序 17 展示了 else if 的用法。
using System;
class Program
{
static void Main(string[] args)
{
var 是否礼貌 = Console.ReadLine();
if (是否礼貌 == "是")
Console.WriteLine("ありがとうございます!");
else if (是否礼貌 == "否")
Console.WriteLine("すみません!");
else
{ // 这个大括号可以省略,省略后就是 else if。
if (是否礼貌 == "我礼貌")
Console.WriteLine("谢谢。");
else
Console.WriteLine("讲文明,树新风。");
}
}
}
布尔值
程序 16 中,我们假设了非“是”即“否”。只有在这种假设下,我们才能使用 if-else 结构。这说明,if 语句中的条件只有两种情况:满足,或不满足。如果一个变量也像这样非黑即白,我们则称这种变量为布尔变量,其类型为布尔型。布尔型的值被称为布尔值。布尔值只能取 true 和 false。
Tip: 布尔是人名。一般我们又称布尔值为逻辑值。
true(真)和false(假)是 C# 的关键字,你取的名字不能是关键字。
using System;
class Program
{
static void Main(string[] args)
{
bool someone_into_hell = true;
bool is_me = false;
if (is_me && someone_into_hell) // && 表示(逻辑)与。
{
Console.WriteLine("这下寄了。");
}
else
{
Console.WriteLine("要么没人入地狱,要么这个某人不是我,要么两者都不满足。");
Console.WriteLine(!someone_into_hell && is_me); // ! 表示(逻辑)取反。没人入地狱。
Console.WriteLine(!is_me && someone_into_hell); // 这个某人不是我。
Console.WriteLine(!someone_into_hell && !is_me); // 两者都不满足。
}
}
}
运行结果:
要么没人入地狱,要么这个某人不是我,要么两者都不满足。
False
True
False
程序 18 说明,布尔值是可以参与运算的。事实上,布尔值共有三种运算:逻辑与(&&)、逻辑或(||)、逻辑非(!),称它们为逻辑运算符。
Tip: 布尔值之间的运算有一套高深的理论,称为布尔代数。这里大家懂点基本的逻辑就行。
如果一个布尔表达式(由布尔值的运算组成的表达式) 难以理解,可以按程序 18 中所示的方法进行分析。程序 18 列举了两个布尔值所有的可能取值:
- 有人下地狱,这个某人是我,所以我下地狱。
- 没人下地狱,这个某人是我,所以我不下地狱。
- 有人下地狱,这个某人不是我,所以我不下地狱。
- 没人下地狱,这个某人也不是我,所以我不下地狱。
这种分析方法即列举真值表。
布尔表达式有两个需要着重注意的点:
- 逻辑运算符的优先级和结合性不同。最重要的一条规则是先与后或。不清楚?没关系,加上一大批括号就行了。
&&和||满足短路运算原则。从左向右计算时,如果表达式的值已经确定了,就不再进行后面的计算了。例如在程序 18 中,如果已经知道了没人下地狱,就不必检查那个某人是否是我,反正我总不会下地狱。
Tip: 使用 Visual Studio 编写 C# 程序,它可以帮你删去额外的括号。但有时,保留括号能够增强程序的可读性,所以 Visual Studio 不会帮你删去所有不必要的括号。
布尔值,必须是布尔值
程序 5 中,我们写道:
win_and_loss = (long)win * lose;
(long)win * lose 表示先把 win 转换为 long 类型,再执行乘法运算。现在我们有了布尔值,很自然地会想到:win_and_loss 不就是把 win 和 lose 求与(and, &&)吗?
using System;
class Program
{
static void Main()
{
int win = 810975;
int lose = 922768;
bool win_and_loss;
win_and_loss = (bool)win && (bool)lose; // 错误:无法将类型"int"转换为"bool"。
string tip = "赢了,但又输了: ";
Console.WriteLine(tip + win_and_loss);
}
}
当我们还在思考一个整数是怎么变成一个逻辑值时,C# 编译器直接给我们泼了盆冷水:C# 不允许把整数变成一个逻辑值。这与 C++ 不同,C++ 中,如果整数为 0,它是可以被隐式转换为 false 的;如果整数不是 0,它被隐式转换为布尔值时将变为 true。
要得到布尔值,除了直接写 true 和 false、写布尔变量组成的布尔表达式,我们还可以通过比较运算符得到它。
using System;
class Program
{
static void Main()
{
int win = 810975;
int lose = 922768;
bool win_and_loss;
win_and_loss = (win != 0) && (lose != 0); // 括号可省略,但留着可读性更强。
string tip = "赢了,但又输了: ";
Console.WriteLine(tip + win_and_loss);
}
}
!= 表示不等于。win != 0 只有两种结果:“不等于”“不是不等于”,所以这个表达式的值是布尔型的。
其他的比较运算符包括小于(<)、小于等于(<=)、大于(>)、大于等于(>=)、等于(==)。注意,一个等号(=)是赋值号,而两个等号(==)是等于。
#include 以上 C++ 程序中,按语境应该找茬,但是程序的运行结果是却是:
15 斤 30 块,给。
得了,这下瓜贩不怕刘华强了,但导演看到刘华强得绕路走了。之所以程序的运行结果是故意不找茬,是因为 if (西瓜 = 15) 这句话少写了一个等号!下面展示了 西瓜 = 15 这个表达式的运算流程:
西瓜 = 15(此时变量西瓜的值为14)西瓜(此时变量西瓜的值为15)true(整数隐式转换为布尔值)
所以无论之前 西瓜 是多少,刘华强都不会找茬。C# 中,由于不允许将整数转换为布尔值,而 if 语句的括号中又一定是一个布尔值,所以从根本上解决了刘华强不按剧本演戏的问题。感谢 C# 让我们看到了《征服》重置版。
using System;
class Program
{
static void Main()
{
int 西瓜 = 14;
if (西瓜 == 15)
Console.WriteLine("15 斤 30 块,给。");
else
Console.WriteLine("你这哪儿够 15 斤,你这秤有问题呀。");
}
}
运行结果:
你这哪儿够 15 斤,你这秤有问题呀。
选择结构之 switch 语句
在 C++ 中,switch 语句很少被使用;在 Python 3.10 之前,压根就没有 switch 语句。所以大家可能对它很不熟悉。
Tip: 最新发布的 Python 3.10 中引入了
match-case语句,即是所谓的switch语句。
using System;
class Program
{
static void Main()
{
var 买点啥 = Console.ReadLine();
switch (买点啥)
{
case "switch":
case "Switch":
Console.WriteLine("买了 Switch。");
break;
case "PS":
case "ps":
Console.WriteLine("买了 PS。");
break;
case "PC":
{ // 括号不是必须的,但之后有大用途。
Console.WriteLine("买了 PC。");
break;
}
default:
Console.WriteLine("不买了");
break;
}
}
}
从程序 22 看来,switch 语句的一个重要作用是代替以下累赘的 if 语句:
string s = "..."; // 可以是 int,不能是 float。
if (s == "A") {}
else if (s == "B") {}
else if (s == "C") {} // 救命,我不想再写 s == 了。
else {}
的确可以。
Tip: C++ 中,
switch语句不支持字符串。所以面对少量简单的字符串,你只能像上面这样写if。当然,对于更复杂的字符串集合,应该设计更好的算法以保证执行效率。
但 switch 的执行规则与上面所示的大有不同。在逻辑上可以分为两步:
- 跳转到分支(
case)标签后的代码。当传给switch的值等于任何一个case后的常量值时,令当前运行的程序为该case下面的第一行代码。注意,我们认为case不是代码,它只是一个标签。如果不存在这样的标签,则跳转到default标签后的第一行代码。如果不存在default标签,则直接跳过这个switch。
注意,case后面的常量值必须是唯一的。 - 顺序执行。执行时忽略标签的存在,直到运行到
switch大括号的尽头,或者遇到break语句,或者因为不可抗力直接结束了整个方法的运行。
根据顺序执行的特点,我们自然会想到,如果没有 break,不就可能把下面所有的代码全部执行完了吗?的确如此。但由于一般而言这都是因为程序员忘记写 break 了,所以 C# 直接让没有 break 的分支报错(包括最后一个分支),从根本上解决了这一问题。当然,这也限制了 switch 的功能。
如果一个分支有代码,但没有 break,则被称为贯穿。上一段的意思即 C# 不允许贯穿。
Tip: 乖乖地按程序 22 的样子使用
switch就没错。
C++ 中,贯穿同样是危险的,但贯穿又是有用的。
#include 运行结果:
比 1 大!
比 0 大!
有时,我真的想像这样一次输出两行话,所以贯穿可能是有用的。但是万一我真的是忘记写 break 了呢?C++ 编译器会在你贯穿时给出一个警告,告诉你别这样。如果你想让 C++ 编译器知道你是真的想贯穿,请使用 [[fallthrough]] 标签。
#include Tip: 觉得自己会 C++,但从来没见过上面这样的
[[fallthrough]]标签?没关系,这是 C++17 新增的内容。
变量的作用域
程序 16 中,我们说:
else
{ // 当有不止一条语句时,必须用大括号括起来。
Console.WriteLine("パカ!");
Console.WriteLine("パカ!");
}
这是 if、else 后所接语句的硬性要求。但除此之外,大括号还会影响变量的可访问位置。
using System;
class Program
{
static void Main()
{
int a = (-2);
{
int b = a * a;
a = b;
}
Console.WriteLine(a);
Console.WriteLine("And where is b?");
}
}
程序 23 中,变量 b 在它所在的大括号结束的那一刻就被销毁了。大括号之后,不仅 b 的值不见了,你叫它的名字它也不会应了。想要让 b 答应你的呼唤,只能在定义 b 之后、大括号结束之前呼喊它,称这个区域为变量 b 的作用域,又称在该区域内能够访问到变量 b。
对于 switch 语句,变量的作用域仍然满足这一规律,所以在 switch 的大括号之内定义变量一定要谨慎,因为变量还必须先初始化,后使用。如果某个分支的代码能够访问到某个变量,但在进入该分支时却轮不到该变量被初始化,那么 C# 编译器会直接报错。解决方法有两个:
- 只在最后一个分支不加大括号定义变量并使用。
- 打个大括号吧。
Tip: 在
switch这方面,C++ 略有不同。C++ 中,如果某个分支的下面还有其他分支,那么位于上面分支的变量不能在定义时被初始化(例如int a = 0;),但 C# 可以。
由于 C++ 有时允许使用未初始化的变量,所以在下面的分支中有时又能使用上面分支的变量,即使该变量未能在下面的分支中被初始化(此时程序一定不是正确的,但编译器未必报错)。
总结:使用大括号缩短变量的作用域,减少当前位置可以访问的变量数量,有助于你更好地把控你的程序。switch 中,遇事不决打括号。
上节习题答案
- 见习题答案 4-1。问题在于不存在求 4 次方的运算符。另外,由于一个数的 4 次方很大,所以最好用
long,但即使是long,输入的数据也只能在五万左右以下才能得到正确的答案。 - 见习题答案 4-2。掌握字符串的
+运算符的使用方法。 - 答案:
- 是
current += 1的意思。但在更复杂的表达式中有更复杂的含义,请自学。 - 第一行
1,第二行2。与数学中的函数相比,程序中的“函数”不是单值的。程序中“函数”的结果除了与参数相关,还与程序当前的状态相关,或者说与程序所有变量的取值相关。
- 是
using System;
class Program
{
static long to_the_power_of_4(int a)
{
return (long)a * a * a * a;
}
static void Main()
{
var number = int.Parse(Console.ReadLine());
Console.WriteLine(to_the_power_of_4(number));
}
}
using System;
class Program
{
static string cat(string a, string b)
{
return a + "," + b;
}
static void Main()
{
var a = Console.ReadLine();
var b = Console.ReadLine();
Console.WriteLine(cat(a, b));
}
}
习题
- 角谷猜想第一步。编写程序,输入一个整数 a,如果 a 是奇数,则输出 3a + 1;如果 a 是偶数,则输出 a / 2。
- 直角三角形。编写程序,输入三行,每行一个浮点数,表示三角形的三条边长。如果这个三角形是直角三角形,输出“是”;否则输出“否”。
你发现了什么问题?回答为什么switch不能判断浮点数。 - 消息处理。编写程序,输入一个整数
message。如果message是0,则什么也不做;如果message是1,输出“DUDE”;如果message是2,输出"NOOB";否则输出"Unknown"。 - *在完成 3. 的基础上,调试程序。观察“当前行”的变化情况。
六、循环结构
背背背背背背背起了行囊
循环结构有什么用?有了循环结构,我们就能背背背背背背起了行囊。
using System;
class Program
{
static void Main(string[] args)
{
int i = 0;
while (i < 5)
{
Console.Write("背"); // WriteLine 换行而 Write 不换行。
i++; // 等价于 ++i; 也等价于 i += 1; 也等价于 i = i + 1;
}
Console.Write("背起了行囊,离开家的那一刻,我知道 C# 的歌,有太多特别的特。");
}
}
运行结果:
背背背背背背起了行囊,离开家的那一刻,我知道 C# 的歌,有太多特别的特。
程序 23 中,我们只写了两个“背”字,运行结果中却能有六个“背”。如果你愿意,你可以背 100000 次行囊,可见,循环结构为程序进行复杂计算提供了结构基础。
与 if 语句完全一致,while 语句的结构为:
while (布尔值)
{
// ...
}
当 while 语句中只有一条语句时,同样可以省去大括号。不过一般 while 语句中不会只有一条语句,因为这种情况多半是一个死循环。
using System;
class Program
{
static void Main(string[] args)
{
int i = 0;
while (i < 5) // i < 5 始终为 true。
Console.Write("背");
}
}
程序 24 无法停机,你将看到控制台中一直在输出“背”。
下面我们来分析 while 语句的执行步骤。执行 while 语句时,首先判断布尔值是否为真,如果为假,则直接跳过整个 while 循环;如果为真,则执行大括号内的程序,并在执行完成后回到判断布尔值是否为真这一步骤。
using System;
class Program
{
static void Main(string[] args)
{
int i = 5;
while (i <= 35)
{
Console.WriteLine(i + "×" + i + "=" + i * i); // *括号内的表达式是如何运算的?
i += 10; // 别忘了写 i = i + 10;
}
}
}
运行结果:
5×5=25
15×15=225
25×25=625
35×35=1225
如果你愿意,可以把 i <= 35 修改为 i <= 100005,这样就能用短短 13 行的程序生成 10001 个等式字符串。
Tip: 为什么是 10001 个?以后写循环结构时你需要经常思考这样的问题。如果你弄错成 10000 个了,就称你犯了差一错误,你应该不想让别人多赚你一块钱吧。
先背一个行囊再说
行囊总是要背的。无论你是不是老兵,你都应该背上一个行囊。C# 中的 do-while 语句可以帮你先背起一个行囊。
using System;
class Program
{
static void Main(string[] args)
{
bool 是老兵 = false;
int 年 = 0;
do
{
Console.Write("背");
年++;
是老兵 = true;
} while (是老兵 && 年 < 10); // 别漏了分号。
Console.Write("起了行囊。");
}
}
运行结果:
背背背背背背背背背背起了行囊。
程序 26 中,一开始你不是老兵,但结果表明你最终背起了行囊——这是因为你成功背起了第一个行囊。可见,do-while 语句会首先执行大括号内的程序,然后再判断 while 后的布尔值。如果为假,则跳过整个 do-while 语句;如果为真,则回到 do 之前,重复之前的步骤。
for 循环
按道理,只需要 while 循环就足够了,do-while 等价于:
{
// ...
}
while (布尔值)
{
// 同上...
}
只是为了方便罢了。那 for 循环又能带来什么方便呢?
using System;
class Program
{
static void Main(string[] args)
{
int counter = 0;
for (int i = 0; i < 3; i++) // {
for (int j = 0; j < 3; j++) // {
for (int k = 0; k < 3; k++)
counter++;
// }}
Console.WriteLine(counter);
}
}
运行结果:
27
从语义上看,for (A; B; C) 等价于:
A;
while (B)
{
// ...
C;
}
对,但不完全对。第一个差别是,A 处定义的变量的作用域是大括号内,而不是大括号外。所以你不能在循环结束后继续访问 A 处定义的变量。
第二个差别是,A、B、C 不能想写什么就写什么。A 必须形如:
// 1. 类型 变量名 = 初值
// 2. 类型 变量名
// 3. 类型 变量名1 (= 初值), 变量名2 (= 初值), ...
即 A 处只能定义相同类型的任意多个变量,并可以在定义时给任意变量赋初值。注意这些变量的作用域都只是在对应 for 的大括号内。
B 显然只能是一个布尔值,而 C 只能是一个表达式,不能是更复杂的多条语句。A、B、C 均可留空,但分号不能省略。当 A、C 留空时,等价于什么都不做,而当 B 留空时,等价于 B 是 true。
using System;
class Program
{
static void Main(string[] args)
{
for (; ; ); // 当大括号里什么都没有时,用分号代替大括号。
}
}
Tip:
if和else在没有语句要执行时也可以用分号代替大括号。所以一般而言不要在if后面打分号!
程序 28 的作用就是不断循环,其他什么事都不用做。如果你希望你的电脑的 CPU 热起来,请多运行几个程序 28。
Tip: 假设你的电脑是 4 核的,即使你运行 4 个程序 28,你的电脑也不会死机。这是操作系统帮你调度 CPU 的功劳。
for 循环和与它等价的 while 循环还有第三个差别,我们将在下一小节看到。
更复杂的循环逻辑
程序 27 中,我们用到了嵌套循环。只要明白了循环不过是顺序执行与跳转的结合,就不难理解嵌套循环的执行思路。
有些时候,我们希望立即终止循环,可以使用 break 语句。
using System;
class Program
{
static void Main(string[] args)
{
while (true)
break;
}
}
只看程序 29 的 while,你会认为这是一个死循环,但看到 break 后,你就知道这个程序只是来搞笑的。
有些时候,我们希望跳过一次循环,可以使用 continue 语句。
using System;
class Program
{
static void Main(string[] args)
{
for (int i = 29; i < 35; i++)
{
if (i == 30)
continue;
Console.WriteLine(i);
}
}
}
运行结果:
29
31
32
33
34
到此,我们可以给出 for 循环和与它等价的 while 循环的第三个差别了,那就是,for 循环使用 continue 语句后会首先执行 C,再判断 B。而 while 语句中的 continue 会使得程序直接跳转到判断布尔值的位置。
using System;
class Program
{
static void Main(string[] args)
{
int i = 29;
while (i < 35)
{
if (i == 30)
continue;
Console.WriteLine(i);
i++;
}
}
}
程序 31 无法停机。控制台中会输出一个 29,之后程序便陷入了死循环。
上节习题答案
-
见习题答案 5-1。
-
见习题答案 5-2。问题是,可能你输入的三个数在你看来明明就是直角三角形数,但程序却输出“否”(例如
0.03、0.04、0.05)。原因是浮点数不是实数,无法精准地保存所有以实数形式给出的数;而浮点数运算的结果也往往不等于等值的实数做相同运算得到的实数结果,称这种现象为浮点误差。一个更简单的例子是0.1 + 0.2 != 0.3。正是因为浮点误差,
switch语句才不能进行浮点数类型的判断。要判断浮点数之间的相等,正确的方法是在两数之差的绝对值小于一个
epsilon时即认为相等,见习题答案 5-2 中的注释。 -
见习题答案 5-3。
using System;
class Program
{
static void Main(string[] args)
{
var a = int.Parse(Console.ReadLine());
if (a % 2 == 0) // 偶数。
Console.WriteLine(a / 2);
else // 否则一定是奇数。
Console.WriteLine(3 * a + 1); // 注意 * 号不能省。
}
}
using System;
class Program
{
static void Main(string[] args)
{
var a = double.Parse(Console.ReadLine());
var b = double.Parse(Console.ReadLine());
var c = double.Parse(Console.ReadLine());
if (a * a + b * b == c * c)
Console.WriteLine("是");
else
Console.WriteLine("否");
/* 正确判断浮点数相等的方法。
if (Math.Abs(a * a + b * b - c * c) < 1e-6)
Console.WriteLine("是");
else
Console.WriteLine("否");
*/
}
}
using System;
class Program
{
static void Main(string[] args)
{
var msg = int.Parse(Console.ReadLine());
switch (msg)
{
case 0:
break;
case 1:
Console.WriteLine("DUDE");
break;
case 2:
Console.WriteLine("NOOB");
break;
default:
Console.WriteLine("Unknown");
break;
}
}
}
习题
学完本节后,面向过程编程的精髓我们就学完了,我们能编写运算量很大的程序了!但我们处理的数据量仍然很少。要处理海量数据,需要用到数组,而数组的讲解将会在了解 C# 对象模型之后进行。
-
角谷猜想。编写程序,输入一个正整数 a(a 是
int型),如果 a 是奇数,则将 a 赋值为 3a + 1 并输出新的 a;如果 a 是偶数,则将 a 赋值为 a / 2 并输出新的 a。重复进行以上操作,直到 a 的值变为 1。提示:将习题答案 5-1 中的代码包装成方法,就不用完全从头写。*角谷猜想的内容是:对于任意正整数 a,经过以上步骤总能变成 1,而不会发散至无穷大或者在一个不包含 1 的闭环内循环。虽然已经验证 2 的 62 次方以内的数都能回到 1,但是过程中出现的数可能远大于一开始的数。编写程序找到最小的无法全程用
int型变量正确执行以上步骤的起始数。这个(找最小起始数)程序要运行多久(在 Release 配置下)?**如果编写完全相同的 C++ 代码,这个(找最小起始数)程序又要运行多久(在 Release 配置下)?
-
判断质数。编写程序,输入一个大于 1 的正整数 a(a 是
int型),如果 a 是质数,则输出“素数”;如果 a 是合数,则输出“合数”。提示:注意题目要求,如果你输出了“质数”,那你在上机考试中将得到 0 分!请按要求输出“素数”。*输入 1000000007,你的程序要运行多久?如果不能在一瞬间内出结果,你能想办法改进吗?
-
线性同余随机数生成器。拷贝习题程序 6-3 中的
my_rand类到你的代码中,编写完整程序,使用my_rand类生成 1000000 个随机数,输出这 1000000 个随机数的均值(向零取整为整数)。提示:使用
var r = new my_rand();生成这个类的实例。提示:这个问题有标准答案,因为这个随机是伪随机。
class my_rand
{
int x = 114514;
public int rand()
{
return x = (int)(((long)1664525 * x + 1013904223) % ((long)1 << 32));
}
}
七、C# 对象模型(一)
我没有对象,但为什么我要研究对象模型
尽管我还没有对象(若你有对象请你低调),但我知道弄清对象模型已是当务之急。我不希望当我有对象的时候经常不清楚对象在哪儿,也不希望对象抛弃我时我不知道 TA 的想法、不知道 TA 将何去何从。
在 C# 中也是如此。我们知道数字电路中的数据都是二进制,它们一比特(bit)一比特地存在着;知道目前计算机中的数据也是二进制,最小存储单元是一字节(byte)(注:1 字节等于 8 比特);知道 C# 的对象的数据也以二进制的形式存在于计算机的内存中。但我想问:
int的数据范围是-2^{31} ~ 2^{31}-1,只需要 32 个比特、即 4 个字节的存储空间。在 C# 中,一个int类型的变量真的只需要 4 个字节的存储空间吗,它是不是还需要一点空间存储它的名字,亦或是它的年龄?- 可以注意到,方法的参数事实上出现了两次,一次是在定义方法时,此时称参数为形参(parameter);一次是在使用方法时,此时称参数为实参(argument)。既然在运行时形参会传给实参,那么形参与实参是否严格相同,亦或完全不同?
- 如果万物皆为对象,那么你写出来的
114514也应该是一个对象。事实上这样直接写出来的常量被称为字面量(literal)。字面量显然不能被修改,那它作为对象还和以变量形式存在的对象一样吗?
这些问题其实可以更具体地被称为内存模型。诸如此类的问题还能再写出好几个,但这里太小了写不下。
经典的内存模型
这里的经典指 C++。在 C++ 中,存储数据的部分内存可以大致地分成两个区域:
-
栈(stack)空间。里面保存了你的局部变量,你的函数(C# 中称为方法)调用轨迹。可见,每个线程(thread)都有一个独立的栈,因为每个线程都有自己的函数调用轨迹。放心,如果你不知道线程也没有关系,但你至少应该听过多线程一说。
栈空间的大小是有限的,取决于创建线程时提供的参数。这个大小不会很大,所以局部变量占的空间不能太多,函数调用的轨迹也不能太深。
栈空间被耗尽的情况时有发生,但目前我们在 C# 中还做不到。要使得局部变量占用大量的空间,我们需要用到数组,即一次性存储大量变量的语法。要使得函数调用轨迹过深,我们需要用到递归,即函数自己调用自己,这其实与 C# 语法无关,是算法设计常用的技巧。
-
堆(heap)空间。里面保存了动态申请的变量(
new)。堆空间是整个程序共享的,大小没有硬性的限制。
这里的经典,其实又指以上模型是目前的程序通用的模型。基本上任何高级编程语言生成的程序都会采用类似的模型。自然 C# 也不例外。
Tip: 事实上内存一般被细分成五个区域,这里没有写全。
Tip: 单片机程序可能没有堆,因为可能没有操作系统,无法动态申请内存。单片机的物理内存也很小,不应有很多东西留在堆里。所以看起来单片机程序就像只有栈一样。
下图展示了一个简单的栈空间。

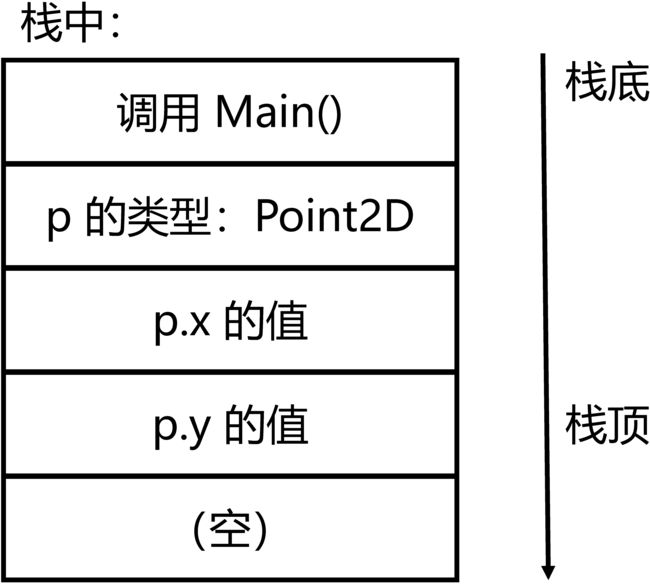
从图中可以看出以下栈空间的以下特点:
- 栈空间是从栈底往栈顶生长的。只能从栈顶加入新数据,也只能从栈顶删去已存在的数据。
- 形参和实参是不同的变量,在内存中由不同的单元存储。这意味着在方法内直接修改形参是无法实现修改实参的效果的。
- 栈空间追踪方法调用轨迹是通过保存之前的 BP 等寄存器实现的。
需要注意的是,作为一个示意图,它只能说明栈空间的原理,与真实情况不同。熟悉栈空间内存结构的读者请忽略图与真实情况的较大差异。
栈,甜蜜的栈?
我们把所有东西都放进栈里不好吗,为什么非得弄一个堆空间?考虑下图中出现的问题。
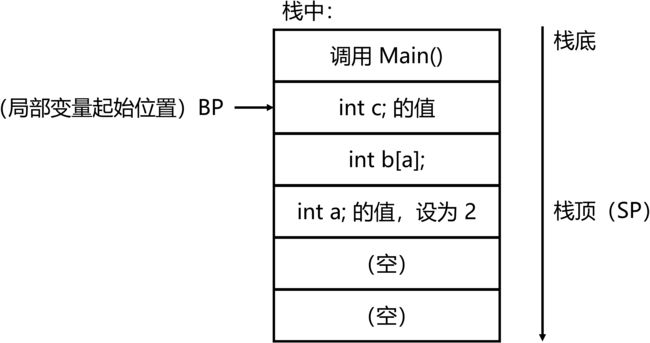
为什么说这个栈空间不可能呢?一般来说,我们程序寻找变量的方法是从 BP 开始跳跃固定长度。如果 b 不是一个长度为变量 a 的数组,那它一定只占一个格子,程序会很清楚 a 的位置,从 BP 开始往下数第 3 个就是了,这个 3 可以由编译器直接求出。但是当 b 是一个长度为 a 的变长数组时,编译器就不知道从 BP 开始数几个为妙了。
所以可以通过下图所示的方法解决这一问题。
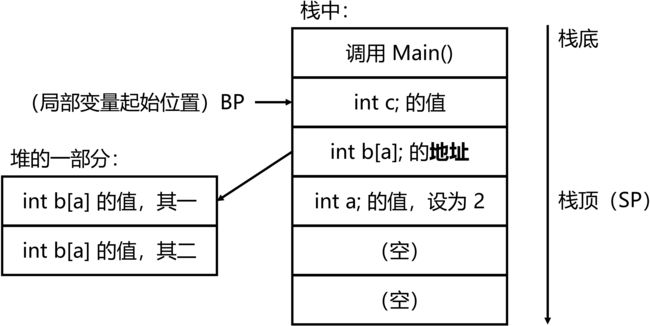
由于 b 的地址的长度是固定的,所以编译器也能知道从 BP 开始数多少个格子是 a。
Tip: C 语言中,有的编译器可以动态求
a的值并实现变量的正确寻址。但编译器的具体实现是不确定行为,编译器完全可以用上图涉及堆的方法实现。而且标准 C 语言并不支持这种写法,因此不推荐编写这样的程序,即使编译器支持。
寸土寸金
至此,我们感受到了栈空间的寸土寸金:
- 栈空间有大小限制,如果一个变量占用的空间太大,设计程序时就应该主动将其放到堆空间。
- 栈空间有变量类型限制。如果一个变量的长度可变(如长度不是常数的数组),设计程序时就不能把它放到栈空间,否则编译器会报错。
下面我们来看在 C# 中哪些变量会被放到栈空间中。不出所料,int、float、double、char 这种简单的类型在被直接声明时都将被放到栈空间。由于它们的数据实实在在地存在于栈中,所以我们也称这些类型为值类型。作为局部变量,值类型的变量在内存中的存储方式正如上面小节中的第一幅图所示。
由于 string 类型的长度并不固定,所以很自然地可以认为 string 类型的数据并不真正地放在栈上。的确如此,不过在栈上总得存放一点关于 string 的东西,它就是引用(ref)。
你看这堆它又长又宽——引用类型
目前为止,我们写出的所有稍复杂类型的变量实际上都属于引用类型,例如(二)中程序 4 的黑外星人。下图展示了引用的内存模型。
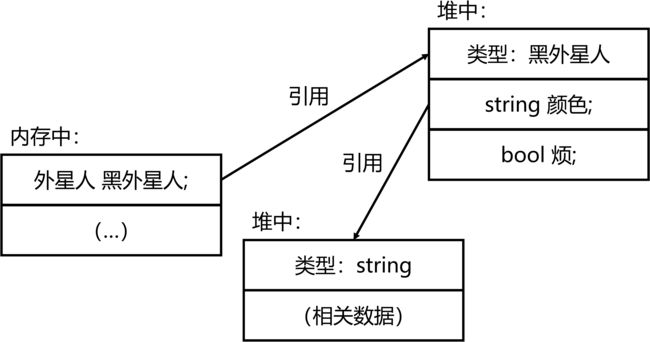
对比该图与上一张图,我们知道引用和地址在本质上是一个东西,它们的作用都是给图中的箭头指示方位。我们还知道了引用是占用空间大小固定的变量类型。
Tip: 看到图中的箭头了吗?这就是 C++ 中的内存地址变量被称为指针的原因。C++ 中的内存地址变量在 C# 中被称为原始指针,仅在特殊情况下使用。一般而言,在 C# 中只使用引用,引用在本质上是一种包装好的指针。
程序 32 以及其中的注释展示了哪些变量属于引用类型。
using System;
class People
{
public string name;
public int age;
}
class Program
{
private static void Main()
{
People me = new People(); // me 是一个引用,因为是自定义类(class)。
me.age = 0b1000; // me.age 是一个值,因为是 int。
me.name = "千年王八"; // me.name 是一个引用,因为是 string 类。
People another_me = me; // another_me 是一个引用。
another_me.age = 0b10000; // *这修改的是谁的 age?
another_me.name = "万年乌龟"; // *这修改的是谁的 name?
Console.WriteLine(me.name + ' ' + another_me.name);
}
}
Tip:
0b前缀表示这个字面量是二进制数。以防你不知道,与十进制数32相等的二进制数是0b100000。正所谓千年王八万年龟,十万行的代码没人追——开个玩笑,还是有很多人想看看《太吾绘卷》初版代码的真容的。
程序 32 的运行结果为:
万年乌龟 万年乌龟
这说明 me 和 another_me 引用的是同一个对象!这不难理解,既然 me 和 another_me 都是引用,那么用 me 给 another_me 赋值,就如同把一个箭头原封不动地复制了一份;这两个箭头都指向了堆上的同一块内存空间。
不难知道,如果我们在程序 32 的末尾接着输出 me.age,得到的结果将会是 16,虽然 age 这一变量是值类型。导致这一结果的本源在于 People 类是引用类型,所以与 age 是否是值类型无关。
Tip: 为什么我们令
age为0b10000,输出的结果却应该是16,而不是0b10000?别忘了,作为一个简单的值类型,int只保存这个整数是多少,不会额外保存给它赋值的字面量到底用的是几进制数。事实上字面量本身也不过是一个int类型的值。如果你想输出二进制数,必须放弃将整数转换为字符串时采用十进制的默认配置。这可以通过调用进制转换的方法(method)实现——虽然我还不知道这个方法叫什么,但肯定已经有人帮你写好了。
新世界
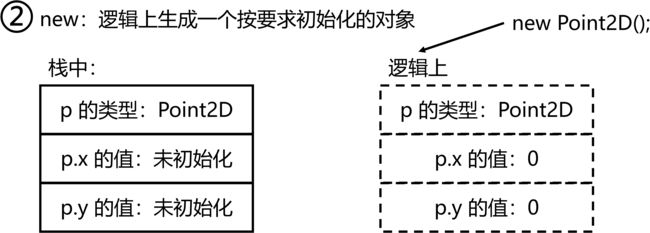
终于,我们正式开始学习 new 关键字。程序 4 中,我们已经写过:
var 黑外星人 = new 外星人(); // **什么是 var?**为什么要 new?
当时说我是乱写的,我可不是乱写的!现在我们知道,黑外星人 是一个引用,而 new 的作用就是在堆上开辟一块内存空间,并返回一个指向该内存空间的引用。
Tip:
外星人后面的那个括号表示参数。与 C++ 不同,即使没有参数,C# 的这个括号也不能省。
下面的图展示了使用 new 关键字的整个流程。


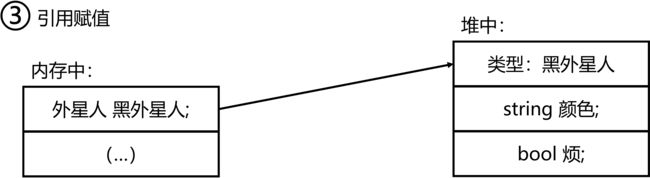
当离开引用类型的变量的作用域(见第(五)节的“变量的作用域”小节)时,我们就无法访问这个变量了,这个引用也就自然消失了,我们没有理由保留它。但是引用指向的内存空间由谁来释放?事实上,C# 相比 C++ 最显著的区别即是,C# 的内存管理由 C# 内部程序集托管,空闲的内存空间将会由垃圾回收器(GC)自动清扫。相关的内容将在之后学习。
栈,甜蜜的栈!——结构体
从上面的三张图可知,new 一下可真够费劲的,不仅要在堆上申请一份内存,用完后还得由 GC 回收。我们又知道我们写出来的类总是引用类型,这就使我们陷入了进退两难的境地。
class 三
{
public int san;
public void 三つ()
{
san = 3;
}
}
class Program
{
private static void Main()
{
int obstacle; // 在栈上。
obstacle = 3; // 但是不够面向对象。
三 难 = new 三();
难.三つ(); // 很面向对象,但是在堆上。
}
}
程序 33 中,我们想要编写一个类,这个类的作用只是计数,但我们还希望它有一些辅助功能:
- 能够手动将计数器变成
3。 - 能够将计数器减一,并在不够时输出一行错误信息。
- 设计数器的当前值为
x,能够计算(x + 3) * 3 - x / 3。 - ……
不幸的是,程序 33 中只写了第一个功能,但我们用了两种不同的方法:
- 编写一个叫作
三的类,其中保存一个整数(表示计数器),然后编写方法执行功能。 - 由于
三这个类在数据域上只有一个整数,我们直接在代码里存一个整数得了,命名为obstacle,就不写类了。需要哪些功能,我们就在obstacle中写这些功能就行了,例如,要实现功能三,我们写int result = (obstacle + 3) * 3 - obstacle / 3;。
明眼人都能看出来,如果我们设计了 1000 个功能,然后想有 1000 个这样的类,那方法二是行不通的。但是方法一实在是太耗费资源了,我只想存一个整数,为什么要在堆中申请内存,然后多一个引用变量指向它?能不能结合以上两个方法的优点?
C# 给了我们机会,方法是使用结构体(struct)。
using System;
struct Point2D
{
public int x;
public int y;
public int dot()
{
return x * x + y * y;
}
}
class Program
{
private static void Main()
{
Point2D p; // 不用 new 了。
p.x = 1;
p.y = 2;
Console.WriteLine(p.dot());
}
}
下图展示了结构体的内存模型。
可见,结构体除了可能额外存储一些本身的类型信息外,其中的数据的内存模型与栈上声明的变量的内存模型完全相同。
Tip: 之所以说可能,是因为这个图是我随便画的。其中包含了结构体内存模型的精髓,那就是结构体的数据不用额外在堆上申请一片内存空间,只需要就地占用一片空间。
C# 的 struct 与 C++ 的 struct 完全不同。C++ 的 class 与 struct 只是有访问权限的区别,而 C# 的 class 与 struct 的内存模型都完全不同了!
新せかい
我们从程序 34 中看到,结构体不需要 new,此时属于该结构体的变量的表现与函数中的 int 型局部变量一致,必须先初始化,后使用。如果其中有些变量不能从外部访问,就必须由结构体自己初始化,这将在之后学习。
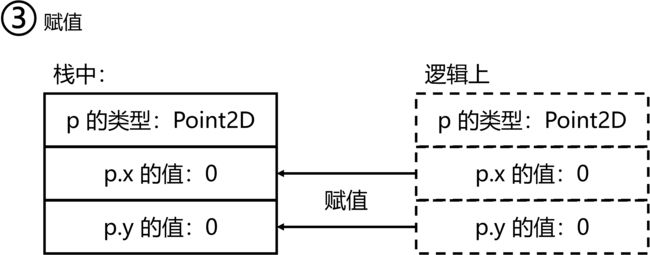
但事实上,结构体也能 new,此时 new 的作用仅仅是初始化。下面的图展示了 new 关键字作用于结构体的整个流程。

shì jiè 与せかい的统一
本小节的标题中,shì jiè 代表“新世界”小节中讲解的 class,せかい(读作 se kai)代表“新せかい”小节中讲解的 struct。事实上,C# 的所有对象要么是类的实例,要么是结构体的实例。前文中提到的“int、float、double、char 这种简单的类型”实质上都是结构体!将类(class)与结构体(struct)统一,就可以得到所有的 C# 对象,如下图所示。
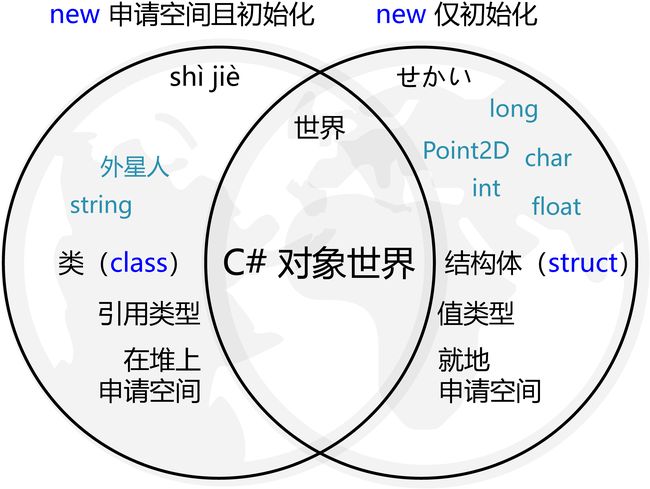
由此,就不难理解哪些类型是引用类型,哪些类型的数据是就地存放的了。
总结:
- 大体而言,C# 中的类型(type)只有两种:类(class)、结构体(struct)。它们都是面向对象中的“类”,都由数据和方法两个部分组成。它们的实例都被称为对象。
- 保存类(class)的实例的变量是引用,对象的数据位于堆上单独分配的一块内存;保存结构体(struct)的实例的变量是值,对象的数据直接就地存放。
- C# 的很多基本简单类型都是结构体,例如
int、long、float。C# 的string类型比较复杂,是一个类。 - 一般来讲,类具有复杂数据和复杂行为,例如
外星人就适合使用class来实现;结构体有少量数据和简单行为,例如二维点类型Point2D就适合用struct来实现。 - 对于类(class),
new关键字的作用是申请空间并初始化。对于结构体(struct),new关键字的作用只有初始化。
Tip: 程序 32 中,
new People()似乎并没有初始化变量,我们还得在后面手动初始化,那为什么说对于class而言new关键字的作用包含初始化?事实上,这里的“初始化”是指初始化People的实例。如果你写在People类里写了相关代码,你就可以在初始化People实例时初始化其中的变量。而对struct而言,初始化结构体实例会默认初始化其中的变量。class和struct在初始化方面是统一的,不同的实际上是它们的默认行为。
之后我们再继续学习更多关于 class 和 struct 的区别。
上节习题答案
-
见习题答案 6-1-1。
解决第二问的思路是,判断过程中是否存在大于2147483647的数。计算时使用long类型的变量。见习题答案 6-1-2。
C++ 版本的程序见习题答案 6-1-3。绝对运行时间取决于计算机的配置,相对来讲 C++ 在这个问题上的运行速度是 C# 的 1.3 倍。可见 C# 的速度还是很快的。 -
见习题答案 6-2。
如果运行太慢,请检查你的程序是否像习题答案 6-2 那样只检查到根号 a。想一想为什么可以这样。 -
见习题答案 6-3。
答案是136401。
using System;
class Program
{
static int step(int a)
{
if (a % 2 == 0) // 偶数。
return a / 2;
else // 否则一定是奇数。
return 3 * a + 1;
}
static void Main(string[] args)
{
var a = int.Parse(Console.ReadLine());
while (a != 1)
{
a = step(a);
Console.WriteLine(a);
}
}
}
using System;
class Program
{
static long step(long a) // 改成 long。
{
if (a % 2 == 0) // 偶数。
return a / 2;
else // 否则一定是奇数。
return 3 * a + 1;
}
static void Main(string[] args)
{
for (long i = 2; ; i++)
{
long a = i;
bool found = false;
while (a != 1)
{
a = step(a);
if (a > int.MaxValue) // int.MaxValue == 2147483647
{
Console.WriteLine("最小的满足条件的数是 " + i);
found = true;
break;
}
}
if (found) // 找到了就终止循环,没找到就继续循环。
break;
}
}
}
#include ::max() == 2147483647
{
std::cout << "最小的满足条件的数是 " + std::to_string(i) << std::endl;
found = true;
break;
}
}
if (found) // 找到了就终止循环,没找到就继续循环。
break;
}
}
using System;
class Program
{
static bool is_prime(int a)
{
int to = (int)Math.Sqrt(a);
for (int i = 2; i <= to; i++)
{
if (a % i == 0)
return false;
}
return true;
}
static void Main(string[] args)
{
int a = int.Parse(Console.ReadLine());
if (is_prime(a))
Console.WriteLine("素数");
else
Console.WriteLine("合数");
}
}
using System;
class my_rand
{
int x = 114514;
public int rand()
{
return x = (int)(((long)1664525 * x + 1013904223) % ((long)1 << 32));
}
}
class Program
{
static void Main(string[] args)
{
int n = 1000000;
var r = new my_rand();
long sum = 0;
for (int i = 0; i < n; i++)
sum += r.rand();
Console.WriteLine(sum / n);
}
}
习题
-
阅读习题程序 7-1。回答下面的问题:
Main中的变量w显然已经被初始化,那么scale的值是多少?- **由于
ActionableCircle是一个类,所以w.ac是一个引用。ac指向哪儿? NamedCircle是string,所以NamedCircle.name是一个引用。w.ac.circle.name是否已经被初始化?说清理由。
-
小节标题《shì jiè 与せかい的统一》包含了中文和日文,如果不使用拼音和假名,而是写为汉字(hàn zì)和漢字(かんじ,读作 kan ji),标题将变为《世界与世界的统一》。这就非常奇怪,明明前者是中文,后者是日文,为什么写出来一模一样?
**根据对以上问题的思考,编写 C# 程序,输入一行字符串,该字符串要么是中文句子,要么是日文句子。如果这个句子是中文,则输出“中文”;如果这个句子是日文,则输出“日本語”。例如,如果输入为“我很好。”,则输出“中文”;如果输入为“私は元気です。”,则输出“日本語”。
using System;
struct NamedCircle
{
public string name;
public float x, y, r;
}
class ActionableCircle
{
public int id;
public NamedCircle circle;
}
struct Wrapper
{
public float scale;
public ActionableCircle ac;
}
class Program
{
static void Main()
{
var w = new Wrapper();
}
}
八、数组(一)
海纳百川,有容乃大
循环结构有如计算密集型程序的心脏,而数组乃数据密集型程序的胸襟。所谓数组(array),是在内存中连续存储的一串元素。C# 的数组是类,是引用类型。根据面向对象的设计原则,你不用理会类或者结构体内部到底是如何实现的,你只用学习使用这个类提供的接口,即这个类公开的(public)的方法,所以本节的重点是了解数组的使用方法、外在表现和逻辑模型。
程序 35 简简单单地创建了一个数组,可谓小试牛刀。
class Program
{
static void Main()
{
int[] 四十米大刀 = new int[40];
int 鸡 = 0;
四十米大刀[鸡] = 1;
}
}
与此前见到的名字不同,数组类型的名字由 [] 结尾。**就类型名而言,int[] 是一个整体,表示元素类型为 int 类型的数组。**由于数组是引用类型,所以 int[] 四十米大刀; 只是一个引用,想要知道 int[] 的更多信息,我们需要观察 int[] 被创建的实例,即 new 产生的东西。
数组的 new 语句的格式为:
new 元素类型[数组大小];
创建数组时必须指定数组大小。事实上,C# 中的数组是定长数组,一旦实例被创建,数组大小就无法被改变。但一个数组类型的变量可以多次赋值,因为数组变量不过是一个引用。
class Program
{
static void Main()
{
int age = 18;
int[] 女 = new int[age];
age += 18;
女 = new int[age];
}
}
程序 36 中,数组大小看似是从 18 改变为了 36,实际上只是引用指向了另一个数组。
Tip: 数组的大小可以为
0,但不能为负数。
由于数组在内存中被连续存储,所以数组具有随机访问(random access)的能力。所谓随机访问,是指我想访问第几个元素就访问第几个,访问第一个和访问第一百万个没有任何区别。要访问数组的第 i 个元素,请写 数组名[i]。
Tip: 从程序 35 可以看出,数组的头部是
数组名[0],是所谓“数组下标从 0 开始”,这样做在计算机中会显得很自然。作为一门编程语言,下标从 0 开始是天经地义的;如果你见到了数组下标从 1 开始的语言,那它可能是易语言,也可能是 MATLAB,他们俩什么货色大家都懂吧(
在创建数组的同时能够同时指定其中元素的初始值,这种情况下 new 语句会更灵活,能够省略类型或大小信息。程序 37 展示了四种初始化数组的语法。
class Program
{
static void Main()
{
int[] 三连 = { 1, 1, 1 }; // 在定义的同时初始化,省略 new, type, size。但不能使用 var。
三连 = new int[3] { 1, 1, 1 }; // 使用 new type[size] { ... } 创建一个带有初始值的数组。
三连 = new int[] { 1, 1, 1 }; // size 可以省略,此时 size 为 3。
// 三连 = new int[4] { 1, 1, 1 }; // 不可以!不能说给四连却只给三连。
三连 = new[] { 1, 1, 1 }; // 同时省略 type 和 size。
// an_array = new[3] { 1, 1, 1 }; // 不可以!不能自以为三连是踩、取关、举报。
}
}
Tip: 以防你不知道,37 乘 3 等于 111。
根据我的经验,很少有情况需要在声明数组时就给所有值进行初始化,所以程序 37 中的内容不是那么重要。
对象模型,数组验之
在本小节中,我们将通过数个有关数组的程序来验证 C# 对象模型,并进行补充。
数组元素的初始化
对于 class,new 语句的功能包含开辟内存空间和初始化。当我们不在定义数组的同时初始化其中的元素时,其中的元素被初始化了吗?有两种可能:
- 没有被初始化,每一个元素都需要经过第一次赋值再使用。
- 被初始化成了一个默认值。
稍加思考可以发现,第一种猜测是不靠谱的。C# 为了保证程序的稳健性,一定会尽全力阻止我们使用未初始化的变量。考虑以下代码:
var an_array = new int[1000000];
an_array[114514] = 0;
如果第一种猜测成立,那么当我们写 an_array[114514] += an_array[233]; 时,程序应当报错,因为我们使用了未初始化的变量 an_array[233]。程序怎么可能这么清楚地知道只有 an_array[114514] 被初始化了呢?这是一个不可能的任务。
Tip: 当你想验证你的想法时,不妨想想看如果是你,你会怎么设计 C#。如果你要实现第一种猜测的功能,你需要额外用一个布尔值类型的数组来保存每个元素是否已经被初始化,你愿意做这么复杂而占用大量内存空间的事情吗?
上例中,我们姑且认为 int 类型的默认初始值为 0 0 0。那如果数组元素的类型是引用类型呢?
var an_string_array = new string[1000];
同样我们可以有两种猜测:
- 上例中,数组中的每个元素都被初始化为了空字符串
""。 - 数组中的每一个元素被初始化为了一个空引用。
事实上,第二种猜测是正确的,上例中数组里的每一个元素都被初始化为了一个特殊的对象 null,表示一个空的引用,我们将在之后学习。要说明第一种猜测的错误性,我们需要探索数组的内存模型。
数组元素的内存模型
数组是一种引用,所以其内存模型可以用图 8-1 所示的形式表示。

根据结构体的内存就地分配的原则,图 8-1 中所示的各项元素必然就是 int 类型变量的值本身。
Tip: 复习本节的第一段,数组的元素在内存中是连续存储的。
而遇到 string 这样的引用类型时,根据引用类型的特点,可以用图 8-2 所示的形式表示其内存模型。

图 8-2 表明,string 类型的数组中的每一个元素都是 string 类型的引用。new 的使命就是分配这些引用的空间,然后把它们初始化为 null,没有理由为这些引用进一步分配空间指向不同的空字符串。
Tip: 再次复习上一节的内容。对于类,
new的作用是分配内存并初始化;对于结构体,new的作用是初始化。本节我们见到了new时自动初始化为默认值的情况,这将在下一节中详细介绍。
为数组中的每个元素赋值
根据面向对象的设计原则,可以猜测数组存在一个方法,其功能是给数组中的每个元素赋值。程序 38 展示了这样的方法。
class Program
{
static void Main()
{
int[] laugh = new int[233333];
System.Array.Fill(laugh, 233); // 将 laugh 中的每个元素填充为 233。
System.Console.WriteLine(laugh[233]); // 输出 233。
}
}
程序 38 中的关键是静态方法 System.Array.Fill,从语义上这是很好理解的。但这句代码隐含了一个信息:int[] 类型似乎可以和 System.Array 类型划等号。事实上,所有的数组都是 System.Array 的实例,但 System.Array 是一个抽象基类,不能被直接创建。目前,我们只需知道 System.Array 提供了所有数组都应该支持的操作。System.Array 与 int[] 的具体关系将在稍晚之后学习。
数组元素,循环遍之
所谓遍历数组(又称迭代(iterate)数组),是指访问数组中的每一个元素,并对这些元素进行相同的操作。很容易想到使用循环结构实现遍历数组。程序 39 展示了对数组中的所有元素求和的方法。
using System;
class Program
{
static void Main()
{
int n = int.Parse(Console.ReadLine());
var an_array = new int[n];
for (int i = 0; i < an_array.Length; i++)
an_array[i] = i + 1; // 对数组元素进行赋值。
long sum = 0;
for (int i = 0; i < an_array.Length; i++)
sum += an_array[i]; // 对数组中的所有元素求和。
Console.WriteLine(sum);
}
}
程序 39 中,an_array.Length 表示该数组的长度。按道理,Length 应该是一个表示“获取数组长度”的方法,但它却没有调用方法时应有的括号,这是因为它是一个属性(property)。属性在本质上仍然是在调用方法,我们将在以后具体学习。
Tip: 标准 C++ 语法中没有属性,但是有些 C++ 编译器支持用扩展的语法编写属性。
程序 39 中的 i 是一个哑变量(dummy variable)。在循环体内 i 表示“第几个元素”,而在循环体外这个 i 就没有意义了,所以最好像程序 39 这样把变量 i 定义在 for 语句的第一个分句处。
Tip: 哑变量这个名字是我临时取的。与别人交流的时候最好称这个变量为 “循环变量”,或者直接说 “
ijk的那个i”,程序员们一听就懂。
很多时候我们需要像程序 39 这样遍历数组中的每一个元素,而又有很多时候我们不关心元素是数组中的第几个,此时我们希望能够避免使用哑变量 i。为此 C# 提供了专用的 foreach 语句,我们将在之后进行学习。事实上,for 语句在功能上完胜 foreach 语句,引入 foreach 语句纯粹是为了使得代码更易读,所以我们不用着急学习它。
多维数组
将 n * m 个数排成一个 n 行 m 列的表,即得到了一个矩阵(matrix)。下面是一个 2 * 3 矩阵的例子:
[[1 1 4]
[5 1 4]]
其中的方括号只是为了增加可读性。矩阵作为一种强大的数学工具,我们常常需要编写程序来处理它们,而最重要的一个步骤便是将它们保存在内存中。注意到,2 * 3 的矩阵总是只有 6 个元素,因此我们可以用一个大小为 6 的数组保存 2 * 3 矩阵。
using System;
class Program
{
static void Main()
{
int[] matrix = new int[] { 1, 1, 4, 5, 1, 4 };
int column = 3; // 列数。
int row = matrix.Length / column; // 行数,等于 2。
for (int x = 0; x < row; x++)
{
for (int y = 0; y < column; y++)
Console.Write(matrix[x * column + y] + " ");
Console.WriteLine("");
}
}
}
从程序 40 可见,如果我们用(一维)数组保存一个 row * column 的矩阵,我们需要写 matrix[x * column + y] 来访问矩阵第 x 行第 y 列的元素,并且这里的下标都是从 0 开始的。
程序 40 中 matrix.Length 为 6,我们用 matrix.Length / column 计算出了 row。能不能直接让数组帮我们存上矩阵的行数和列数?这样我们就不用在外面定义 column 变量了。要实现这样的功能,我们可以使用 C# 提供的二维数组。
using System;
class Program
{
static void Main()
{
int[,] matrix = new int[2, 3] { { 1, 1, 4 }, { 5, 1, 4 } };
for (int x = 0; x < matrix.GetLength(0); x++) // 第 0 维的长度是行数。
{
for (int y = 0; y < matrix.GetLength(1); y++) // 第 1 维的长度是列数。
Console.Write(matrix[x, y] + " ");
Console.WriteLine("");
}
}
}
程序 41 演示了 C# 中二维数组的使用方法,我们直接做一个小结:
- C# 中二维数组的类型名形如
int[,],是一个整体。 - 要获取二维数组每一维的长度,使用数组的
GetLength(维数)方法。维数从0开始,第0维是行,第1维是列。 - 要访问二维数组的元素,请写形如
matrix[x, y]的代码。其中x表示行,y表示列。
特别注意,对于二维数组,C# 只是帮我们额外保存了行数与列数,其内存结构与一维数组仍基本一致,如图 8-3 所示。

C# 还支持更高维度的数组,如三维数组 int[,,],四维数组 int[,,,]……图 8-4 展示了三维数组的内存结构。

最后,我们来了解初始化多维数组的语法。类似于一维数组,多维数组的初始化有以下几种选择。
int[,] example = { { 1, 1, 4 }, { 5, 1, 4 } }; // 定义时初始化,省略 new, type, size,不能用 var。
new int[2, 3] { { 1, 1, 4 }, { 5, 1, 4 } } // 同时指定类型和大小。
new int[,] { { 1, 1, 4 }, { 5, 1, 4 } } // 只指定类型,大小自动推导。
new[,] { { 1, 1, 4 }, { 5, 1, 4 } } // 类型和大小都自动推导。
想要通过编译,必须写出全部的元素,例如,下面的写法都是非法的:
new int[2, 3] { { 1, 1 }, { 5, 1 } } // 错误:不是一个 2 * 3 的数组。
new int[,] { { 1, 1, 4 }, { 5, 1 } } // 错误:无法推导出数组的大小。
new int[,,] { { 1, 1, 4 }, { 5, 1, 4 } } // 错误:不是一个三维数组。再加一层大括号就正确了。
可见,C# 数组初始化的语法非常严格,我们不用学习很多的特殊情况。但这也限制了一些想法的实现,详见本节习题 8-1。
数组的数组
顾名思义,数组的数组就是数组的数组,这不是搁这搁这——如果用 C++ 来描述这件事就昭然若揭了。
#include 前面提到,在 C# 中,所有的数组都是 System.Array 的实例,如果能像 C++ 一样写成 System.Array 就一目了然了,但是不可以!C# 为数组的数组提供了专门的语法,如程序 42 所示。
using System;
class Program
{
static void Main()
{
long[][][] array_of_array_of_array = new long[42][][]; // 使用 new long[size][][] 创建数组的数组的数组。
array_of_array_of_array[0] = new long[1][]; // 使用 new long[size][] 创建数组的数组。
array_of_array_of_array[0][0] = new[] { -80538738812075974, 80435758145817515, 12602123297335631 }; // 类型为 long[]。
var an_array = array_of_array_of_array[0][0]; // 数组是引用类型。
long sum = 0;
for (int index = 0; index < an_array.Length; index++)
{
long product = 1;
for (int power = 0; power < 3; power++)
product *= an_array[index];
sum += product;
}
Console.WriteLine(sum - array_of_array_of_array.Length);
}
}
程序 42 的运行结果是:
0
Tip: 以防你不知道,
(-80538738812075974)³ + 80435758145817515³ + 12602123297335631³ = 42。以防你不知道,写两遍程序 42 将会产生 42 行代码。
数组的数组的内存结构如图 8-5 所示。
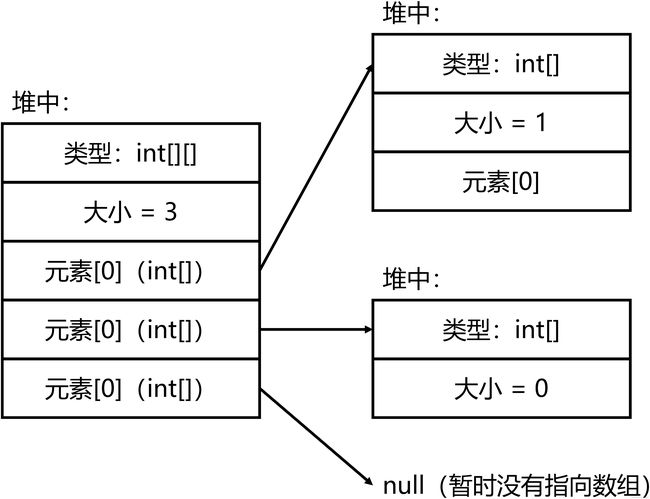
没什么好说的,数组的数组也不过只是一个数组罢了!我们往往也称数组的数组为交错数组(Jagged Arrays),因为外层数组指向的内层数组大小可以不同。
Tip: 小心,不要和 C++ 的数组搞混。C++ 中多维数组与数组的数组都使用
array[x][y][z]的格式访问其基本元素;而 C# 中,多维数组使用array[x, y, z],数组的数组使用array[x][y][z]。
上节习题答案
- 本题的主要目的是理解
new对struct和class的作用,以及理解引用类型需要先指向才能使用。其中涉及了初始化的默认值,需要上机调试才能知道答案,因为理论还没有讲。w.scale等于0(浮点数)。w.ac指向null,即暂时没有指向任何对象。w.ac并没有指向任何对象,还没有进行ActionableCircle对象的创建,所以该问没有意义。
- 本题的主要目的是了解字符在计算机中的表示。
- 因为中文汉字和同形的日文汉字在 Unicode 中使用相同的代码(码位),所以用中文的“世界”和日文的“世界”是无法区分的。有些时候输入日文会显示出不同的形状,是因为那些文本框支持显示不同的字体。
- 思路:中文中没有假名,所以判断句子中是否存在假名即可。具体代码略。
习题
恭喜你学会了数组的基本操作,到此,你已经可以使用 C# 编写非常强大的程序了——你可以用循环编写计算密集型程序,用数组编写数据密集型程序!所以从本节开始习题的数量和难度都会大幅提升,习题中也会融入不少算法元素;不过不要担心,习题的目的是熟悉 C# 语法,所以其中的算法部分会给足提示。习题的另一个目的是介绍一些有趣的问题,有兴趣的读者不妨搜索下习题的小标题。
-
初始化数组的部分元素。编写 C# 程序,要求创建一个大小为
114514的int[],其中前6个元素被初始化为{ 1, 1, 4, 5, 1, 4 },剩下的元素保持为0。保证n >= 6。如果你会 C++,可以参考习题程序 8-1,你的任务就是编写等效于习题 8-1 的 C# 程序(但不要像习题程序 8-1 那样使用全局变量)。 -
模
2^64剩余系。阅读程序 42,其运行结果是0,但这真的证明了(-80538738812075974)³ + 80435758145817515³ + 12602123297335631³ = 42吗?答案是否定的,因为程序 42 中的乘法实际上**溢出(overflow)**了!所谓溢出,是指运算结果超出了数据的表示范围,例如int的范围是-2147483648 ~ 2147483647。但有趣的是,即使发生了算术溢出,程序的运算结果仍然是0,请解释原因,并解释为什么程序 42 无法证明该等式。 -
丢番图难题。编写程序,求解方程
a³ + b³ + c³ = n,其中a、b、c都是整数未知数,n是一个0到100的整数,只需要输出任意一组解,或者宣布无解。你可以上网搜索问题的相关资料。提示:当n等于42时,答案已经知道了! -
逆序数。有
n个不同的数排成一排,如果其中的第i个数大于第j个数(i != j),则称i和j构成一个逆序对。称一个序列不同逆序对的总数为该序列的逆序数。编写 C# 程序,第一行输入一个整数n,接下来n行每行包含一个整数(int范围内),保证这n个整数互不相同。求将这n个整数排成一排构成的序列的逆序数。*这道题应该限制
n的范围为多少比较合适? -
约瑟夫问题。有
n个人围成一个圈,标号为0, 1, 2, ..., n - 1。从0号人开始报数,每报m个人就让最后一个报数的人退出,然后继续报数,最后这n个人只会剩下一个。编写 C# 程序,输入两行,每行一个整数,分别是n、m,使用数组模拟以上过程,最后输出"铁轨总得创死一个人,要不然就把第 {x} 号人创死吧。",其中x是最后那个人的序号,注意下标从0开始。保证n <= 1000000,n * m <= 100000000。例如,当
n = 3,m = 2时,一开始0, 1, 2围成圈,0号报一,1号报二,所以1号最先退出。然后0 2围成圈,2号接在1号后面报一,0号报二,所以0号退出。最后剩下2号被眼巴巴地创死。 -
幻方问题。一个
n * n的矩阵,其中被填入了1到n * n的每一个数,且该矩阵每行、每列及两条对角线上的数字之和都相同。编写 C# 程序,输入一个奇数n,输出一个这样的幻方。这个问题并不容易,所以下面直接给出构造方法:首先将1写在第一行的中间。之后,按如下方式从小到大依次填写每个数k:- 若
k - 1在第一行但不在最后一列,则将k填在最后一行,k - 1所在列的右一列。 - 若
k - 1在最后一列但不在第一行,则将k填在第一列,k - 1所在行的上一行。 - 若
k - 1在第一行最后一列,则将k填在k - 1的正下方。 - 若
k - 1既不在第一行,也不在最后一列,如果k - 1的右上方还未填数,则将k填在k - 1的右上方,否则将k填在k - 1的正下方。
保证
n <= 5000。 - 若
-
有限元法。定义一个大小为
n * n的二维浮点型数组T,并定义一个整型变量t表示时间。初始时间为t = 0,且满足T[0, 0] = C,其中C是一个常数;其余的T为0。根据下面的方程计算t0后的T数组:- 对任意
t,T[0, 0] = C。 - 若
[x, y]属于矩阵的四个顶点之一(除了[0, 0]),则令t时刻的T[x, y]为t - 1时刻的[x, y]周围的三个值取平均。 - 若
[x, y]在矩阵的边上,则令t时刻的T[x, y]为t - 1时刻的[x, y]周围的五个值取平均。 - 若
[x, y]在矩阵的内部,则令t时刻的T[x, y]为t - 1时刻的[x, y]周围的八个值取平均。
编写 C# 程序,输入三行,第一行是一个正整数
n,第二行是一个浮点数C,第三行是一个正整数t0。输出t0时刻的整个数组T。保证n <= 5000,n * n * t0 < 100000000。*使用数组的数组解决这个问题,并对比运行时间。
- 对任意
-
杨辉三角。定义一个二维数组
C,它满足:- 若任一下标为
0,则元素为0。 C[1, 1] = 1。C[x, y] = C[x - 1, y - 1] + C[x - 1, y](x >= y)。
编写 C# 程序,输入一行正整数
n,输出杨辉三角的前n个非零行。不要输出其中的0。例如,当n = 4时,输出:1 \1 1 \1 2 1 \1 3 3 1,其中的\表示换行。保证n <= 5000。*使用数组的数组解决这个问题,并对比内存空间占用情况。
- 若任一下标为
int an_array[114514]{ 1, 1, 4, 5, 1, 4 };
int main() {}
九、C# 对象模型(二)
窥豹一斑,具体而微——接上回
《抱朴子·正郭》道:
“夫所谓亚圣者,必具体而微,命世绝伦,与彼周孔其间无所复容之谓也。”
C# 之对象可谓亚圣乎?仔细想来,与圣者 C++ 期间,谓具体倒还欠缺三分:
- 第七节《C# 对象模型(一)》中有言:“形参和实参是不同的变量,在内存中由不同的单元存储。这意味着在方法内直接修改形参是无法实现修改实参的效果的。”但如果我真的想要修改形参该怎么办?
- 第八节《数组(一)》中有言:“数组里的每一个元素都被初始化为了一个特殊的对象
null,表示一个空的引用。”null到底是什么?我能利用它吗? - 第七节中又有言:“字面量显然不能被修改,那它作为对象还和以变量形式存在的对象一样吗?”我们需要回答与其相关的问题。
- 第二节《类与面向对象》中有言:“面向对象编程的精髓在于,你写程序的思路是‘让某个对象做某事’。”但我如何让对象被创建时就自动做某事?
- 第八节中又有言:“
System.Array是一个抽象基类,不能被直接创建。”何为基类?何为抽象?
人不行,别怪路不平,C# 当然可谓亚圣——谓圣者也不为过;不觉具体而微,只因窥豹一斑。本节中,我们将回答前三个问题,以逐步视对象之全貌。
Tip: 还记得以上原文吗?若不记得,请复习它们的上下文。
彼唱此和,此唱彼和——ref 关键字
《明史·刘世龙传》有载:
“天下风俗之不正,由于人心之坏。人心之坏,患得患失使然也。……仕者日坏于上,学者日坏于下,彼唱此和,靡然成风。”
C# 的引用类型有如彼唱此和的罪魁祸首。程序 43 展示了如何利用引用类型修改方法的参数并对方法外的变量造成影响。
using System;
class Program
{
static void 唱(int[] an_array)
{
an_array[0] = 1;
an_array[1] = 1;
an_array[2] = 4;
an_array[3] = 5;
an_array[4] = 1;
an_array[5] = 4;
}
static void Main()
{
var 和 = new int[6];
唱(和);
for (int i = 0; i < 和.Length; i++)
Console.WriteLine(和[i]);
}
}
运行结果:
1
1
4
5
1
4
程序 43 对方法 唱 的参数 an_array 中的元素进行了修改,我们惊奇地发现,Main 中的变量 和 也发生了改变!
Tip: 如果我们不希望像这样影响到外面的世界,应该怎么办?有两种解决方案,一是禁止方法的参数被修改,这将在本节的“动中有静,静中有动”小节中介绍;二是把参数所引用的内容复制一份,让参数指向专门复制出的数据,这将在下一节介绍。
事实上这也没什么好惊奇的,图 9-1 清晰地说明了其原理。

这真的一点也不新鲜,在第七节《C# 对象模型(一)》中我们已经讲过了!不过重要的内容再怎么强调也不为过,我们同时复习一下值类型的情况。程序 44 类似于程序 43,只是将方法参数的类型修改为了值类型。图 9-2 说明了其原理。
using System;
class Program
{
static void 唱(int a_number)
{
a_number = 114514;
}
static void Main()
{
var 不和 = new int();
唱(不和);
Console.WriteLine(不和);
}
}
运行结果:
0

Tip: 从以上论述可以看出,方法的参数也是变量,与普通的变量没有实质上的区别。
我们不愿“仕者日坏于上,学者日坏于下,彼唱此和”,但我们有时又希望可以“此唱彼和”,正如程序 45 的意图。
using System;
class Program
{
// 希望里面的交换对外面产生影响。
static void exchange(int[] a, int[] b)
{
var t = a;
a = b;
b = t;
}
static void Main()
{
int[] a = { 5, 1, 4 };
int[] b = { 1, 1, 4 };
exchange(a, b);
for (int i = 0; i < a.Length; i++)
Console.WriteLine(a[i]);
for (int i = 0; i < b.Length; i++)
Console.WriteLine(b[i]);
}
}
运行结果:
5
1
4
1
1
4
可惜,程序 45 是一个错误的程序,它并没有按我们的意愿“此唱彼和”,方法里对参数的操作并没有让外部的变量的得到响应。明明都是引用类型,为什么程序 45 不像程序 43 那样起作用?图 9-3 对比了程序 45 的内存模型与程序 43 的区别。
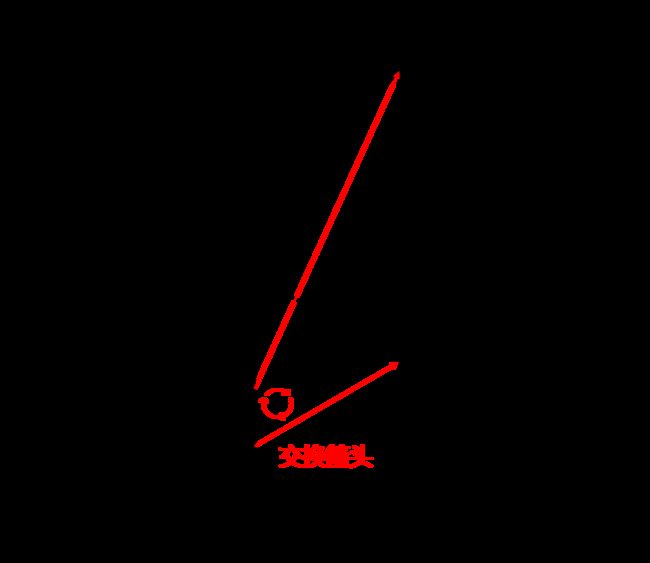
我们不可能为了交换两个变量而像程序 43 一样用到数组(对于程序 45 而言,我们需要的是数组的数组),这太不优美了!
Tip: Python 中真的只能用数组(Python 的数组叫作列表)实现程序 43 的等价程序,不过 Python 中交换变量可以直接写作
a, b = b, a。
为了达成修改外部变量的目的,C# 提供了 ref 关键字。程序 46 展示了程序 45 在使用 ref 后的正确版本。
using System;
class Program
{
// 希望里面的交换对外面产生影响。
static void exchange(ref int[] a, ref int[] b) // 指定参数为 ref 变量。
{
var t = a;
a = b;
b = t;
}
static void Main()
{
int[] A = { 5, 1, 4 };
int[] B = { 1, 1, 4 };
exchange(ref A, ref B); // 指定参数以 ref 变量的形式传入。
for (int i = 0; i < A.Length; i++)
Console.WriteLine(A[i]);
for (int i = 0; i < B.Length; i++)
Console.WriteLine(B[i]);
}
}
运行结果:
1
1
4
5
1
4
图 9-4 展示了程序 46 中此唱彼和的过程。

可以看到,程序 46 交换两个数组的本质只是使得两个引用类型的箭头发生了交换,数组数据本身并没有移动,这样的操作并不耗费太多时间。那如果 ref 关键字作用于值类型的变量又会如何?程序 47 展示了这一过程。
using System;
class Program
{
// 希望里面的交换对外面产生影响。
static void exchange(ref int a, ref int b) // 指定参数为 ref 变量。
{
var t = a;
a = b;
b = t;
}
static void Main()
{
int A = 514;
int B = 114;
exchange(ref A, ref B); // 指定参数以 ref 变量的形式传入。
Console.Write(A);
Console.Write(B);
}
}
Tip: 真正写程序时,记得给变量取个好名字!虽然程序 47 叫《磁场闭合》,但是里面的变量
B并不是磁感应强度,A也不是磁矢势。
纵观程序 46 与 47,我们可以总结出被 ref 关键字作用的变量与普通变量的关系,如图 9-5 所示。

Tip: 磁感应强度 B 和磁矢势 A 哪一个更基本?现代物理认为磁矢势 A 比磁感应强度 B 更基本。但在图 9-5 中,值类型的
ref(B)和引用类型的ref(A) 是并列关系,它们在本质上是一样的——把 C# 和电动力学区分开来!
最后,我们对 ref 关键字做一份小结:
- 被
ref关键字修饰的变量具有“此唱彼和”的效果——此处修改,彼处跟随。本质上是因为ref关键字是一种指针,指向了已存在的变量。 ref关键字不仅可以修饰方法的参数,还可以修饰局部变量。正如前面的 Tip 所述,方法的参数与局部变量本质上都是变量。但被ref关键字修饰的局部变量必须在定义的同时初始化。另外,ref关键字不能修饰类的数据。ref关键字不仅可以修饰方法参数,还可以修饰返回值。其本质是返回了一个指针。习题 9-1 讨论了这个问题。- 使用时,不仅变量类型需要被
ref修饰,变量前也需要加上ref关键字,表示获取这个变量的指针。
我们称被 ref 关键字修饰的参数为按引用传递的参数,与之前按值传递的参数相区分。再次看向图 9-5,有必要澄清:按引用传递与引用类型不是一个东西。本质上,按引用传递是一个指向值类型变量或引用类型变量的指针,而引用类型变量是一个指向真实数据所在位置的指针。如图 9-5 所示,可以认为按引用传递的引用类型变量是指针的指针,因为从它到真实数据经历了一蓝一红两个“箭头”。
Tip: 什么是指针?复习下,一个“箭头”就是一个指针。
**ref 关键字的 C++ 对应
可以认为 ref 关键字与 C++ 中的引用标志 & 比较类似。在本质上的确如此,它们都是指针,不同的只是它们的使用方法。C# 的 ref 关键字更像是 C++ 中的引用标志 & 和指针标志 * 的结合体:
- C# 中必须在变量前面加上
ref,类似于 C++ 中必须对变量取地址(&)才能将其传入指针类型(*)的参数。 - C# 中使用按引用传递的变量时不需要写额外的修饰,类似于 C++ 中引用类型的变量可以直接使用。
因为 C# 不需要引入指针的概念,所以只需要一个 ref 就能做到“此唱彼和”,这比 C++ 中的情况要简单。但若想要理解其本质,最好是从指针的角度看待它。
不过,C++ 中竟然也有 ref!
#include 从 set_an_int 函数的签名来看,我们希望它能达到修改外部变量的效果,但以上程序的运行结果却是 0!这是因为在 C++ 中,若要在绑定函数时以引用形式传入一个变量,就必须显式地用 std::ref 包装这个变量,否则这个变量总是先复制,然后再以值的形式传入。
#include Tip: 觉得自己会 C++,但从来没见过
std::ref?要小心了,这是 C++11 就有的东西。
深入浅出,浅入深出——out 关键字
《湖楼笔谈》六有言:
盖诗人用意之妙,在乎深入显出。入之不深,则有浅易之病;出之不显,则有艰涩之患。
那当然我是做不到深入浅出的!不过 out 关键字可以,因为它足够简单,它只是一个要求参数“浅入深出”的 ref 罢了。
using System;
class Program
{
static void set_an_int(out int a_number)
{
a_number = 114514; // 被 out 修饰的参数必须被赋值。
}
static void Main()
{
int A; // 未初始化。
set_an_int(out A); // 该方法起到初始化 A 的作用。
Console.WriteLine(A); // 输出 114514。
}
}
所谓“浅入深出”,不过是指将传入的未初始化的变量初始化——当然传入一个已初始化的变量也是可以的。
总结:
out关键字在原理上与ref关键字完全相同,都可被称为按引用传递参数。out关键字与ref关键字类似,除了要修饰参数,还需要在传入的变量前显式写出。out关键字在使用上与ref关键字的区别之一:out关键字只能用于修饰方法参数。out关键字在使用上与ref关键字的区别之二:被out关键字修饰的参数必须在方法内被赋值,或者按引用传递给一个可以给参数赋值的方法。
动中有静,静中有动——const 关键字、字面量、枚举,readonly 关键字
const 关键字、字面量、枚举
到目前为止,我们在 C# 中都使用变量存储数据。但事实上,并不是所有的数据都需要“变”:程序 49 中就用到了不少不需要变的量。
using System;
class Program
{
static void Main()
{
double pi = 3.14159265358979323846264; // 圆周率。
double h = 6.62607015e-34; // 普朗克常数。
double hbar = h / (2 * pi); // 约化普朗克常数。
double ground = (pi * pi * hbar * hbar) / 2; // 基态能量。
for (int n = 1; n <= 4; n++)
Console.WriteLine(n * n * ground);
}
}
程序 49 输出了质量为 1 的粒子在宽度为 1 的无限深势阱中的四个最低的定态能量。可以注意到,变化的不仅是定态下的波函数,程序 49 中的 pi、h、hbar、ground 也都是变量,虽然它们实际上应该是不变的量。这会给我们带来一些麻烦,因为指不准哪天一个倒霉蛋就在别处把你的 pi 给改成 3.0 了,但你却浑然不知。
Tip: 因为定态波函数有一个随时间变化的相位项,所以定态波函数会随时间而发生改变,但定态能量却不随时间发生改变。但在程序 49 中,可变的是
pi、h、hbar、ground这几个变量,不应该变的是它们的取值,这是 C# 中的动中有静——把 C# 和量子力学区分开来!
要避免这样的倒霉蛋,可以在变量前面加上 const 关键字,这会让变量成为一个常量(constant)。程序 50 是程序 49 的修改版,展示了使用常量正确定义 pi、h 等值的方法。
using System;
class Program
{
static void Main()
{
// 使用 const 关键字修饰变量类型。
const double pi = 3.14159265358979323846264; // 圆周率。
const double h = 6.62607015e-34; // 普朗克常数。
const double hbar = h / (2 * pi); // 约化普朗克常数。
const double ground = (pi * pi * hbar * hbar) / 2; // 基态能量。
for (int n = 1; n <= 4; n++)
Console.WriteLine(n * n * ground);
}
}
如果没有倒霉蛋,程序 49 与程序 50 有区别吗?我们说,有本质上的区别。图 9-6 对比了程序 49 和程序 50 在运行了 const pi = 3.14...; 这条语句后栈的情况。

程序 49 的栈空间并无特殊之处,而敏锐的读者可以察觉到程序 50 内存空间的异常:
pi、h、hbar、ground这些常量并没有存在栈空间中,而是被放在了其他地方。准确地说,这些常量与代码放在了同一片区域中。- 明明还没有“执行”
h、hbar、ground这三个常量的“赋值”,它们却已经有正确的值了。
要解释程序 50 的“异常”现象,需要明白 C# 编译器为我们做了什么。形象地说,可以如下划分编写、编译、运行程序 50 的过程:
- 我们编写程序告诉 C# 编译器
pi、h、hbar、ground是const常量。 - C# 编译器收到!因为常量不应被改变,索性在编译时就计算出来。
- C# 编译器发现确实可以计算出这四个常量的结果,它们分别是
pi = 3.14...,h = 6.62...e-34,hbar = 1.05…e-34,ground = 5.48…e-68。没有常量在计算过程中用到了无法在编译时确定其值的变量,(此处)编译通过。 - C# 编译器将计算出的常量结果放在了程序中。程序运行时其代码等内容被加载到内存中,这些常量也就一并被加载了。
所以,我们可以总结出被 const 修饰的常量的特点:
- 被
const修饰的常量在编译时就由编译器计算,最终程序中不包含计算它们的代码。 - 由上一点可知,被
const修饰的常量必须能够在编译时就完全确定下来。这也意味着被const修饰的常量必须在定义的同时“初始化”,用于“初始化”被const修饰的常量的表达式不能包含任何需要在运行时才可知的内容。 - 由上一点可知,若被
const修饰的常量的类型是引用类型,则其值只可能是null,因为引用类型涉及动态内存分配的,其“箭头”必须在程序运行时才能指向除null以外的内容。 - 事实上,被
const修饰的常量的类型只能是数字、字符串、布尔值、或被初始化为null的引用类型,即使是就地占用内存的结构体(除了数字和布尔值)也是不能由const修饰的。
Tip: 虽然我们已经提到了很多次
null,但我们在下一小节中才正式介绍它,所以实在感到难以理解读者可以提前阅读下一小节的部分内容。目前为止,仅从null的表现来看,可以简单地把它理解成一个编译时就可以确定的常量0。
Tip: 对常量的“初始化”打引号,是因为对于变量而言,其初始化发生在程序运行到形如
int a = 0;这样的语句处;而被const修饰的常量在编译时就已经初始化完成,实际上不会有任何代码对应程序中的const int a = 0;,所以运行时并没有初始化常量。“初始化常量”实际上的含义是“告诉编译器这个常量的值”。
英明神武的读者又可以察觉到以上总结中的异样了。const 关键字如此严格,连结构体这种就地占用内存的类型(除了数字和布尔值)都不能被它修饰,凭什么作为引用类型的字符串可以被 const 修饰?程序 51 展示了各种被 const 修饰的常量,读者不妨试试找到它们的共同特征。
using System;
class Program
{
class MyClass { }
static void Main()
{
const int n = 114514;
const float f = 114.514F; // 结尾的 F 是什么意思?
const double D = 1.145e14; // e 是什么意思?
const string s = "114514";
const bool b = true;
const MyClass cls = null;
}
}
Tip: 51 单片机上无法运行 C# 程序,所以程序 51 其实并不是为单片机编写的,而是为各位读者编写的。
程序 51 中各常量的共同特征是,它们都被初始化为了一个“可以写出来的量”,我们称这些可以写出来的量为字面量(literals)。字面量并不是变量,所以字面量不可能被修改,进而我们可以大胆猜测:所有可以被 const 修饰的类型一定能够用字面量表达。
程序 51 中,我们抛出了两个有关字面量的问题,这说明字面量的书写存在一些不能用常识去理解的规则。下面我们学习几条常见的规则,其他规则请在需要时上网搜索。
Tip: 上面“存在一些不能用常识去理解的规则”针对的是不会任何其他编程语言的读者。但你即使会 C++ 等编程语言也需要关注下面的内容,因为在 C# 中这些规则并不与其他编程语言的相同。
-
直接写出的整数字面量是 10 进制数。如果需要使用 16 进制数的字面量,请以
0x或0X开头。例如0x114514表示 10 进制数1131796。 -
整数字面量的类型由其值和后缀一起决定。后缀
L表示这个字面量一定是long或ulong类型中的一个。后缀u或者U表示这个字面量一定是uint或ulong中的一个,但如果其值为负数则会报错。L和U这两种后缀可以以任意顺序同时使用。整数字面量可以赋值给变量和被
const修饰的常量,如果不使用var关键字,则字面量本身的类型就不重要了。 -
浮点型字面量的类型默认是
double。后缀f或F表示这个字面量是float,后缀m或M表示这个字面量是decimal。这三个浮点类型之间不能够被隐式转换,必须适时加上后缀。 -
浮点型字面量可以用科学计数法,例如
1.145e14F表示float型的1.145 × 10^14。 -
布尔型字面量只包含
true和false。 -
字符串字面量使用
"包含住。有关字符串字面量的内容,我们将在介绍字符串时详细介绍。 -
不妨把
null也看作一个字面量。
程序 52 是对 const 关键字用法的一个补充。
using System;
struct Ternary
{
public const int H = 1;
public const int L = 0;
public const int Z = -1;
public int s;
}
class Program
{
static void Main()
{
Ternary ternary = new Ternary();
ternary.s = Ternary.H; // H 是静态的!
}
}
程序 52 说明,**若被 const 修饰的常量属于一个类,则它自动就是静态的。**更甚,你不能额外加上 static,否则将会出现编译错误。
程序 52 反映了另外一个问题:当我想使用结构体表示某个状态,而这个结构体仅仅储存了一个数时,这个结构体使用起来并不方便。例如,程序 52 中,我们无法在不添加其他代码的情况下方便地在定义的同时初始化 ternary 变量,不能写:
Ternary ternary = Ternary.H;
这是因为 Ternary.H 是一个 int,而 ternary 是一个结构体。**枚举(enumeration)**类型解决了该问题,程序 53 是程序 52 使用枚举后的等效代码。
using System;
enum Ternary : int // Ternary 是一个类型为 int 的整数。
{
Z = -1, // 所赋值必须是在编译时能确定的常量。
L = 0,
H, // 若不赋值,则默认是上一个值加一。
Low = High - 1, // 可以定义值相同的一系列常量。
High = H, // 只要不出现循环定义的情况,就可以使用后面的常量值。
}
class Program
{
static void Main()
{
Ternary ternary = Ternary.High;
Console.WriteLine(ternary); // 若不进行类型转换,会输出第一个等于该值的常量名字。
}
}
运行结果:
H
程序 53 中的注释中已经写出了枚举类型的所有要点,最后我们再给出其高屋建瓴的总结:
- 枚举类型本质上是一个整数,是值类型,定义时可以在其类型名后以形如
: int的格式指定具体的类型,也可以省略,默认就为int类型。 - 定义枚举类型包含指定一个整数类型和定义一系列常量两个方面,称这些常量为枚举字面量,作为字面量,它们也同样可以用于初始化被
const修饰的常量。为枚举字面量指定的值必须能在编译时确定。 - 使用枚举字面量时,必须加上枚举类型名。
- 虽然枚举类型在本质上是一个整数类型,但考虑到应用场景,C# 不允许将枚举类型隐式转换为整数。要将枚举转换为整数,必须写形如
(int)Ternary.High的代码。 - C# 为我们存储了枚举字面量的名字,使用形如
ternary.ToString()的代码即可获得该枚举类型变量所存储值对应的枚举字面量名,而WriteLine函数内部会自动调用ToString方法输出其名字。
readonly 关键字
请参见:https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/keywords/readonly
readonly 关键字的应用场景较多,从参考资料来看,我们目前还不能完全了解 readonly 的用法。现在我们只需要知道其基本的含义是只读,而非不变。下面我们只介绍 C# 7.2 引入的 ref readonly,其他内容将在以后学习。
ref readonly 与 ref 的作用基本一致,唯一的区别是,被 ref readonly 传递的引用是不能被修改的。程序 54 展示了 ref readonly 的使用方法。
using System;
class Program
{
static ref readonly int yourself(ref int a) => ref a;
static void Main()
{
int a = 0;
ref readonly int readonly_a = ref yourself(ref a); // 此处 ref 不能省略。
a = 114514;
// readonly_a = 0; // 不能赋值。
Console.WriteLine(readonly_a);
}
}
程序 54 中,变量 readonly_a 是只读的,本质上是一个指向 a 的指针。当 a 改变后,可通过输出 readonly_a 观察到修改结果,但不能透过 readonly_a 对 a 进行修改,此所谓“静中有动”——静不是常量,静是只读。
**const 关键字与 readonly 关键字的 C++ 对应
C# 中的 const 关键字对应 C++ 中的 constexpr 关键字,不同的是 C++ 中的类也可以被 constexpr 修饰。
C# 中的 ref readonly 对应 C++ 中的 const T&。
色即是空,空即是色——null 关键字与可空类型
“色即是空”,意思是有形的物质是虚空的。在 C# 中,null 关键字就是一种虚空。
class Program
{
static void Main()
{
string 未初始化;
string 空字符串 = "";
string 色 = null; // 色即是空。
}
}
程序 55 中,色 虽然是一个字符串,但它不指向任何“有形”的对象;它也与未初始化的变量不同,未初始化的引用类型变量指向的内容是不确定的,而 色 明确指向了 null。图 9-7 说明了程序 55 中的三个应用类型变量所指向的内容。

简而言之:
- 可以将
null理解为所有引用类型变量都可指向的一个特殊位置,这个特殊位置不包含任何数据,也可以将其理解为“明确地不指向任何对象实体”。 - 应当将未初始化的引用类型变量理解为“乱指向了一个位置”。
null的本质是0指针,所以null可以被视为一种字面量,值为0,但类型可以是任一引用类型。
null 是引用类型专属的。如果我们希望将一个引用类型暂时留白,我们可以将其赋值为 null。但如果我们希望将一个值类型的变量暂时留白该怎么办?程序 56 给出了一种解决思路:定义只包含一个整数变量的 class。
using System;
class nullable_int
{
int a;
public ref int value() => ref a;
}
class Program
{
static void Main()
{
nullable_int a = null;
if (a == null) // 判断 a 是否为 null。
{
a = new nullable_int();
Console.WriteLine(a.value()); // 复习:应当输出 0。
}
a.value() = 114514;
Console.WriteLine(a.value());
}
}
程序 56 的的确确解决了值类型变量不可为 null 的问题,但存在以下明显的问题:
- 我们想要存储的数据仅仅是一个整数,但我们被迫定义了一个引用类型,使用时必须在堆上分配内存,效率低下。
- 我们的写法太繁琐了。
C# 为我们准备了一套非常简洁的语法,称为可空类型(nullable type)。程序 57 展示了可空类型的使用方法。
using System;
class Program
{
static void Main()
{
int? a = null; // int? 是可空的整数类型。
if (a == null) // 判断 a 是否为 null。
{
a = 0;
Console.WriteLine(a.Value); // Value 是属性。
}
a = 114514;
Console.WriteLine(a); // 也可以直接传给 WriteLine。
}
}
C# 的可空类型解决了前面的两个问题。图 9-8 展示了可空类型的内存模型。

Tip: 可空类型只适用于值类型。因为引用类型本身就是可空的,所以不能用
?修饰引用类型。但自 C# 8.0 起,引用类型的可空也有了更多说法,我们稍后将会提到。
可空类型不过是一个结构体,我们只需要学习其相应的方法与 C# 提供的特殊语法。下面是一系列总结:
- 可空类型虽然是一个
struct,但不能再次被?修饰。这是由 C# 更多的语法决定的。 - 可空类型存在名为
Value的属性,当可空类型变量不空时,可以通过变量名.Value取得变量的值。但Value属性是只读的。 - 可空类型存在名为
HasValue的属性,表示变量是否有值。 - 必须直接对可空类型变量进行赋值。
- 可空类型可以使用双问号运算符(
??),含义是可空类型变量 ?? 默认值。 - 可空类型可以使用空条件操作符(
?.),将.后面方法的返回值转变为一个可空类型。当变量为空时,.后面的方法不会被调用,并将得到与返回值类型相同的空变量。
上节习题答案
上节习题答案将在之后单独发布。
习题
拖太久没更新了,已经想不出啥习题了。
第八章答案
1. 初始化数组的部分元素
因为 C# 中的数组一定是引用类型的变量,所以一定会涉及动态内存分配,因此在语法上不存在类似于习题程序 8-1 的写法:C++ 中使用 new 创建数组时也不能这样。所以仅有的办法是创建数组后将初始值拷贝进去。
class Program
{
static void Main()
{
var an_array = new int[114514];
{
int[] initializer = { 1, 1, 4, 5, 1, 4 };
for (int i = 0; i < initializer.Length; i++)
an_array[i] = initializer[i];
}
}
}
个人认为这个问题没有真正的应用场景,所以没有必要深究。
2. 模 2^64 剩余系
首先,虽然 long 是有符号数,但因为计算机采用补码的格式存储整数,故在运算时可以将 long 类型看作无符号数。
因为已知:
( − 80538738812075974 ) 3 + 8043575814581751 5 3 + 1260212329733563 1 3 = 42 (1) (-80538738812075974)^3 + 80435758145817515^3 + 12602123297335631^3 = 42 \tag{1} (−80538738812075974)3+804357581458175153+126021232973356313=42(1)
所以:
( − 80538738812075974 ) 3 + 8043575814581751 5 3 + 1260212329733563 1 3 ≡ 42 ( m o d 2 64 ) (2) (-80538738812075974)^3 + 80435758145817515^3 + 12602123297335631^3 \equiv 42 \pmod{2^{64}} \tag{2} (−80538738812075974)3+804357581458175153+126021232973356313≡42(mod264)(2)
但 ( 1 ) (1) (1) 式只是 ( 2 ) (2) (2) 式的充分条件,不是必要条件。在将 long 看作无符号数后,程序 42 只是证明了 ( 2 ) (2) (2) 式,所以不能说程序 42 证明了 ( 1 ) (1) (1) 式。
3. 丢番图难题
不能直接枚举 a, b, c,因为 a, b, c 的范围是无穷大的!正确的做法是上网搜索答案,然后把答案用数组的形式保存下来。
参见 https://www.sohu.com/a/339450566_642762
using System;
class Program
{
static void Main()
{
var a = new long[101] { 0, -1, 7, 1, 0, 0, -1, 104, -1, 217, 1, -2, 7, 0, 0, -1, -511, 1, -1, 19, 1, -11, 0, 0, -2901096694, -1, 297, -1, 14, 1, -283059965, 0, 0, 8866128975287528, -1, 14, 1, 50, 1, 117367, 0, 0, -80538738812075974, 2, -5, 2, -2, 6, -23, 0, 0, 602, 23961292454, -1, -7, 1, -11, 1, 0, 0, -1, 845, 3, 7, -1, 91, 1, 0, 0, 2, 11, -1, 7, 1, -284650292555885, 4381159, 0, 0, 26, -19, 69241, 10, -11, -2, -8241191, 0, 0, -1972, 3, 6, -1, 364, 1, -5, 0, 0, 10853, -1, 14, 2, 7 };
var b = new long[101] { 0, 1, -5, 1, 0, 0, -1, 32, 1, -52, 1, -2, 10, 0, 0, 2, -1609, 2, -2, -14, -2, -14, 0, 0, -15550555555, -1, 161, 1, 13, 1, -2218888517, 0, 0, -8778405442862239, 2, -8, 2, 37, -3, 134476, 0, 0, 80435758145817515, 2, -7, -3, 3, 7, -26, 0, 0, 659, 60702901317, 3, -11, 3, -21, -2, 0, 0, -4, 668, 3, -4, 1, 85, 1, 0, 0, -4, 20, 2, 9, 2, 66229832190556, 435203083, 0, 0, 53, -33, 103532, 17, -11, 3, -41531726, 0, 0, -4126, -4, 6, 3, 192, 3, -5, 0, 0, 13139, -3, 9, 3, -3 };
var c = new long[101] { 0, 1, -6, 1, 0, 0, 2, -105, 2, -216, 2, 3, -11, 0, 0, 2, 1626, 2, 3, -16, 3, 16, 0, 0, 15584139827, 3, -312, 3, -17, 3, 2220422932, 0, 0, -2736111468807040, 3, -13, 3, -56, 4, -159380, 0, 0, 12602123297335631, 3, 8, 4, 3, -8, 31, 0, 0, -796, -61922712865, 3, 12, 3, 22, 4, 0, 0, 5, -966, 2, -6, 4, -111, 4, 0, 0, 5, -21, 4, -10, 4, 283450105697727, -435203231, 0, 0, -55, 35, -112969, -18, 14, 4, 41639611, 0, 0, 4271, 5, -7, 4, -381, 4, 7, 0, 0, -15250, 5, -15, 4, -6 };
int n = int.Parse(Console.ReadLine());
if (n == 0)
{
Console.WriteLine("0 0 0");
}
else if (a[n] == 0)
{
Console.WriteLine("无解");
}
else
{
Console.WriteLine(a[n] + " " + b[n] + " " + c[n]);
}
}
}
注:其中的数组手写太累,写到六分之一我就放弃了,故写了个程序处理了参考网址附有的答案。
using System;
class Program
{
static void Main()
{
var a = new long[101];
var b = new long[101];
var c = new long[101];
for (int i = 1; i <= 100; i++)
{
var line = Console.ReadLine();
if (line.EndsWith("不可能"))
{
// a[i] = b[i] = c[i] = 0;
}
else
{
var triple = line.Split(" = ")[1].Split(" + ");
for (int j = 0; j < 3; j++)
triple[j] = triple[j].Trim('(', ')', '³');
a[i] = long.Parse(triple[0]);
b[i] = long.Parse(triple[1]);
c[i] = long.Parse(triple[2]);
}
}
// 检查是否正确。
for (int i = 0; i <= 100; i++)
{
if (a[i] != 0 && a[i] * a[i] * a[i] + b[i] * b[i] * b[i] + c[i] * c[i] * c[i] != i)
{
Console.WriteLine(i + " 错误");
return;
}
}
Console.Write("var a = new long[101] { ");
Console.Write(string.Join(", ", a));
Console.Write(" };\n");
Console.Write("var b = new long[101] { ");
Console.Write(string.Join(", ", b));
Console.Write(" };\n");
Console.Write("var c = new long[101] { ");
Console.Write(string.Join(", ", c));
Console.Write(" };\n");
}
}
4. 逆序数
枚举 i 和 j 即可。
using System;
class Program
{
static void Main()
{
int n = int.Parse(Console.ReadLine());
var a = new int[n];
for (int i = 0; i < n; i++)
a[i] = int.Parse(Console.ReadLine());
int count = 0;
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
if (a[i] > a[j])
count++;
Console.WriteLine(count);
}
}
n 的范围不应上万,否则需要改进算法。
5. 约瑟夫问题
使用数组记录哪些人已经退出了。
using System;
class Program
{
static void step_crt_person(int n, ref int crt_person)
{
crt_person++;
if (crt_person >= n)
crt_person = 0;
}
static void next_person(ref bool[] is_out, ref int crt_person)
{
step_crt_person(is_out.Length, ref crt_person);
while (is_out[crt_person])
step_crt_person(is_out.Length, ref crt_person);
}
static void Main()
{
int n = int.Parse(Console.ReadLine());
int m = int.Parse(Console.ReadLine());
var is_out = new bool[n];
int crt_person = 0;
for (int round = 1; round < n; round++)
{
for (int i = 1; i < m; i++)
next_person(ref is_out, ref crt_person);
is_out[crt_person] = true;
next_person(ref is_out, ref crt_person);
}
Console.WriteLine($"铁轨总得创死一个人,要不然就把第 {crt_person} 号人创死吧。");
}
}
注意,这个算法的效率实际上是很低的,因为已经退出的人仍然需要通过调用 step_crt_person 方法跳过,但对于题目所给的数据范围,仍然能在较短的时间内得出解。
6. 幻方问题
使用二维数组保存填入的数,使用两个整数保存当前的位置。题目怎么说就怎么写。
using System;
class Program
{
static void Main()
{
var n = int.Parse(Console.ReadLine());
var rect = new int[n, n];
int crt_x = 0;
int crt_y = n / 2;
int crt_num = 0;
rect[crt_x, crt_y] = ++crt_num;
while (crt_num < n * n)
{
if (crt_x == 0 && crt_y != n - 1)
{
crt_x = n - 1;
crt_y = crt_y + 1;
}
else if (crt_y == n - 1 && crt_x != 0)
{
crt_x = crt_x - 1;
crt_y = 0;
}
else if (crt_x == 0 && crt_y == n - 1)
{
crt_x++;
}
else if (rect[crt_x - 1, crt_y + 1] == 0)
{
crt_x = crt_x - 1;
crt_y = crt_y + 1;
}
else
{
crt_x = crt_x + 1;
}
rect[crt_x, crt_y] = ++crt_num;
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
Console.Write(rect[i, j] + " ");
Console.Write("\n");
}
}
}
7. 有限元法
逐字逐句翻译编写程序即可。
using System;
class Program
{
static void Main()
{
var n = int.Parse(Console.ReadLine());
var C = float.Parse(Console.ReadLine());
var t0 = int.Parse(Console.ReadLine());
var T = new float[n, n];
T[0, 0] = C;
while ((t0--) != 0)
{
var newT = new float[n, n];
newT[0, 0] = C;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i == 0 && j == 0)
continue;
else
{
float sum = 0;
int count = 0;
for (int delta_i = -1; delta_i <= 1; delta_i++)
for (int delta_j = -1; delta_j <= 1; delta_j++)
{
int new_i = i + delta_i;
int new_j = j + delta_j;
if (new_i == i && new_j == j)
continue;
if (0 <= new_i && new_i < n && 0 <= new_j && new_j < n)
{
sum += T[new_i, new_j];
count++;
}
}
newT[i, j] = sum / count;
}
}
T = newT;
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
Console.Write(T[i, j] + " ");
Console.Write("\n");
}
}
}
仅仅将二维数组改变为数组的数组,程序如下所示。
using System;
class Program
{
static void Main()
{
var n = int.Parse(Console.ReadLine());
var C = float.Parse(Console.ReadLine());
var t0 = int.Parse(Console.ReadLine());
var T = new float[n][];
for (int i = 0; i < n; i++)
T[i] = new float[n];
T[0][0] = C;
while ((t0--) != 0)
{
var newT = new float[n][];
for (int i = 0; i < n; i++)
newT[i] = new float[n];
newT[0][0] = C;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i == 0 && j == 0)
continue;
else
{
float sum = 0;
int count = 0;
for (int delta_i = -1; delta_i <= 1; delta_i++)
for (int delta_j = -1; delta_j <= 1; delta_j++)
{
int new_i = i + delta_i;
int new_j = j + delta_j;
if (new_i == i && new_j == j)
continue;
if (0 <= new_i && new_i < n && 0 <= new_j && new_j < n)
{
sum += T[new_i][new_j];
count++;
}
}
newT[i][j] = sum / count;
}
}
T = newT;
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
Console.Write(T[i][j] + " ");
Console.Write("\n");
}
}
}
输入 n = 1000,C = 1,t0 = 100,在 Release 配置下对程序进行计时(不含输入输出部分),运行时间分别为:
- 二维数组:1.340 秒。
- 数组的数组:1.339 秒。
输入 n = 1000,C = 1,t0 = 10,在 Debug 配置下计时:
- 二维数组:0.524 秒。
- 数组的数组:0.444 秒。
Release 配置下无显著差别。Debug 配置下二维数组反而更慢,原因暂时未知。
8. 杨辉三角
逐字逐句翻译编写程序即可。题目有纰漏,应该要求不考虑整数溢出。
using System;
class Program
{
static void Main()
{
var n = int.Parse(Console.ReadLine());
var C = new int[n + 1][];
for (int i = 0; i <= n; i++)
C[i] = new int[i + 2];
C[1][1] = 1;
for (var i = 2; i <= n; i++)
for (var j = 1; j <= i; j++)
C[i][j] = C[i - 1][j - 1] + C[i - 1][j];
for (var i = 1; i <= n; i++)
{
for (var j = 1; j <= i; j++)
Console.Write(C[i][j] + " ");
Console.Write("\n");
}
}
}
空间使用情况分析略。
https://lunyu.5000yan.com/2-12.html ↩︎
https://baike.baidu.com/item/%E5%90%9B%E5%AD%90%E4%B8%8D%E5%99%A8/3647847 ↩︎