NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
目录
- 5.5 实践:基于ResNet18网络完成图像分类任务
-
- 5.5.1 数据处理
-
- 5.5.1.1 数据集介绍
- 5.5.1.2 数据读取
- 5.5.1.3 构造Dataset类
- 5.5.2 模型构建
- 5.5.3 模型训练
- 5.5.4 模型评价
- 1.什么是“预训练模型”?什么是“迁移学习”?
-
- (1)、什么是迁移学习
- (2)、预训练模型
- 2.比较“使用预训练模型”和“不使用预训练模型”的效果。
- 思考题
-
- 1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。
- 参考文献
- 心得体会
5.5 实践:基于ResNet18网络完成图像分类任务
在本实践中,我们实践一个更通用的图像分类任务。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
- 数据集:CIFAR-10数据集
- 网络:ResNet18模型
- 损失函数:交叉熵损失函数
- 优化器:Adam优化器
- 评价指标:准确率
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×32像素。CIFAR-10数据集的示例如 图5.15 所示。
5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_' + str(batch_id))
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding='latin1')
imgs = batch['data'].reshape((len(batch['data']), 3, 32, 32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(
folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py',
batch_id=1, mode='train')
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
查看数据的维度:
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
运行结果

可视化观察其中的一张样本图像和对应的标签,代码如下所示:
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn-car.pdf')
运行结果:

5.5.1.3 构造Dataset类
构造一个CIFAR10Dataset类,其将继承自torch.io.DataSet类,可以逐个数据进行处理。代码实现如下:
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
class CIFAR10Dataset(Dataset):
def __init__(self,
folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py',
mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
torch.manual_seed(100)
train_dataset = CIFAR10Dataset(folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py',
mode='train')
dev_dataset = CIFAR10Dataset(folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py',
mode='dev')
test_dataset = CIFAR10Dataset(folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py',
mode='test')
5.5.2 模型构建
使用torchvision.modelsAPI中的resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18()
5.5.3 模型训练
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
class Accuracy:
def __init__(self, is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, dim=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(preds == labels).clone().detach().numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
self.dev_scores = []
self.train_epoch_losses = []
self.train_step_losses = []
self.dev_losses = []
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
self.model.train()
num_epochs = kwargs.get("num_epochs", 0)
log_steps = kwargs.get("log_steps", 100)
eval_steps = kwargs.get("eval_steps", 0)
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
global_step = 0
for epoch in range(num_epochs):
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
y = y.to(dtype=torch.int64)
loss = self.loss_fn(logits, y)
total_loss += loss
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
loss.backward()
if custom_print_log:
custom_print_log(self)
self.optimizer.step()
optimizer.zero_grad()
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
self.model.train()
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
trn_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
self.model.eval()
global_step = kwargs.get("global_step", -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
X, y = data
y = y.to(torch.int64)
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
loss = self.loss_fn(logits, y).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
@torch.no_grad()
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
import torch
def accuracy(preds, labels):
print(preds)
if preds.shape[1] == 1:
preds = torch.can_cast((preds >= 0.5).dtype, to=torch.float32)
else:
preds = torch.argmax(preds, dim=1)
torch.can_cast(preds.dtype, torch.int32)
return torch.mean(torch.tensor((preds == labels), dtype=torch.float32))
class Accuracy():
def __init__(self):
self.num_correct = 0
self.num_count = 0
self.is_logist = True
def update(self, outputs, labels):
if outputs.shape[1] == 1:
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
preds = torch.can_cast((outputs >= 0), dtype=torch.float32)
else:
preds = torch.can_cast((outputs >= 0.5), dtype=torch.float32)
else:
preds = torch.argmax(outputs, dim=1).int()
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
import torch.nn.functional as F
import torch.optim as opt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
运行结果:
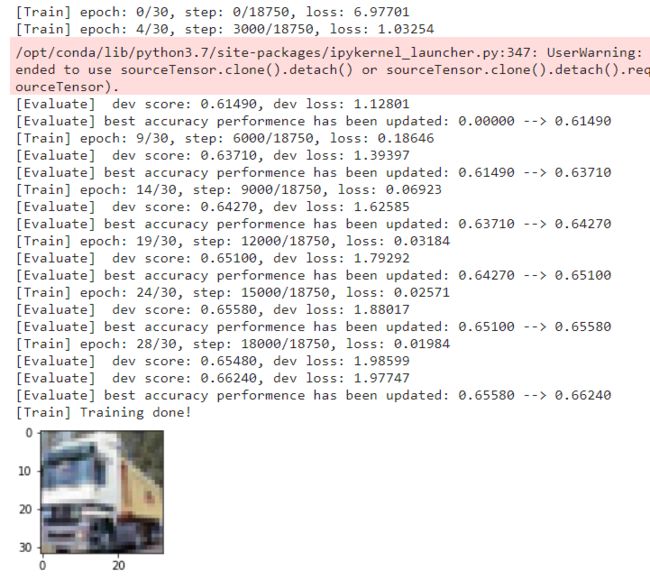
5.5.4 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(iter(test_loader))
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果如下:
![]()
输入一张图片进行测试:
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
X = X.cuda()
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).cpu().numpy()
print(label[2].numpy())
label = label[2].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='C:/Users/努力画图QaQ/Desktop/cifar-10-python/cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')
运行结果如下:
![]()

1.什么是“预训练模型”?什么是“迁移学习”?
(1)、什么是迁移学习
迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。
迁移学习的定义:迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
(2)、预训练模型
预训练模型可以把迁移学习很好地用起来。这和小孩读书一样,一开始语文、数学、化学都学,读书、网上游戏等,在脑子里积攒了很多。当他学习计算机时,实际上把他以前学到的所有知识都带进去了。如果他以前没上过中学,没上过小学,突然学计算机就不懂这里有什么道理。这和我们预训练模型一样,预训练模型就意味着把人类的语言知识,先学了一个东西,然后再代入到某个具体任务,就顺手了,就是这么一个简单的道理。
4、迁移学习和预训练模型
2.比较“使用预训练模型”和“不使用预训练模型”的效果。
上面那个运行结果就是不使用预训练模型的效果。
将resnet = models.resnet18()改为resnet = models.resnet18(pretrained=True)再跑一遍。
运行结果如下:
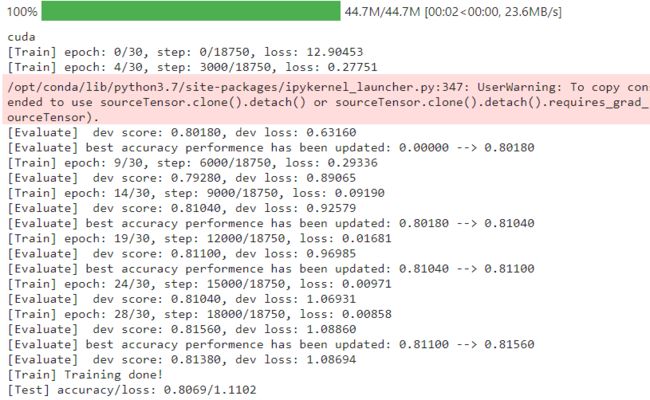
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。
本文章提出了残差学习网络ResNet,很好地解决了在线性的卷积神经网络中仅仅增加网络的深度,会出现的网络退化问题,使得网络的学习能力能够随着网络深度的增加而增加。其大幅度提高了深度卷积网络提取特征的能力,并使得计算机的在视觉方面的识别能力达到并超过了人类的水平。
本文通过引入残差学习(residual learning)来解决退化问题,即 ⊕ ⊕ ⊕上方学习的为 H ( x ) − x H(x)-x H(x)−x,这也正是要学习的残差 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x,希望通过 H ( x ) = F ( x ) ⊕ x H(x)=F(x)⊕x H(x)=F(x)⊕x拟合x,这里引入了x,把恒等映射作为网络H(x)的一部分。而原本是H(x)拟合x。
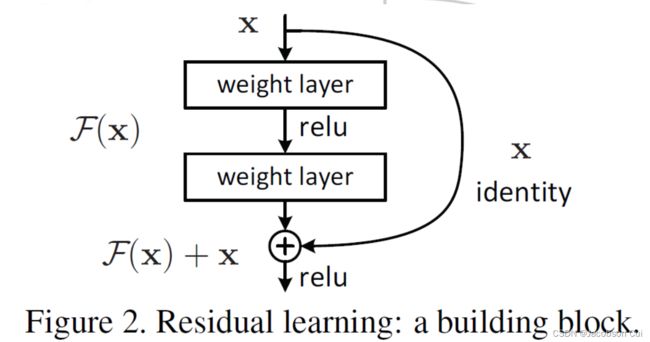
深度学习经典论文分析(六)-Deep Residual Learning for Image Recognition
参考文献
NNDL 实验5(下)
NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
【深度学习】使用预训练模型
pytorch学习笔记之加载预训练模型
心得体会
cpu跑得太慢,cuda用不了,经同学推荐使用了一个很好用的网站来运行这些代码。五分钟就跑完了。不知道为什么正确率增长很慢,运行了即便都是这样,只好作罢。