三十九.卷积神经网络实现cifar10分类
目录
- 1.数据预处理
-
- (1)导入数据
- (2)数据预览
- (3)数据标准化
- (4)样本展示
- 2.预测
-
- (1)搭建模型
- (2)配置网络
- (3)断点存续
- (4)训练网络
- 3.ACC曲线图与Loss曲线图
1.数据预处理
(1)导入数据
from tensorflow.keras import datasets
cifar10 = datasets.cifar10
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
(2)数据预览
from collections import Counter
import numpy as np
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
print(x_train.max(),x_train.min())
print(Counter(np.squeeze(y_train)))
输出:
(50000, 32, 32, 3) (50000, 1)
(10000, 32, 32, 3) (10000, 1)
255 0
Counter({6: 5000, 9: 5000, 4: 5000, 1: 5000, 2: 5000, 7: 5000, 8: 5000, 3: 5000, 5: 5000, 0: 5000})
训练集50000个样本,测试集10000个样本,图片是32*32的3通道RGB图片,类别一共有10种,样本特征的范围为0-255,样本特征的值范围为0-255。
(3)数据标准化
x_train,x_test=x_train/255.,x_test/255.
print(x_train.max(),x_train.min())
输出:
1.0 0.0
(4)样本展示
#样本图片展示
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(20,2))
for i in range(0,10):
plt.subplot(1,10,i+1)
plt.imshow(x_train[i])
plt.show()

2.预测
(1)搭建模型
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense
class BaseLine(Model):
def __init__(self):
super(BaseLine,self).__init__()
#6个卷积核,每个尺寸为5*5,全零填充,步长为1
self.c1 = Conv2D(filters=6,kernel_size=(5,5),strides=1,padding='same')
#批标准化
self.b1 = BatchNormalization()
#relu激活
self.a1 = Activation('relu')
#最大池化,池化核尺寸为2*2,步长为2,使用全零填充
self.p1 = MaxPooling2D(pool_size=(2,2),strides=2,padding='same')
#随机丢弃20%神经元
self.d1 = Dropout(0.2)
#在保留第0轴的情况下对输入的张量进行Flatten(扁平化)
self.flatten = Flatten()
self.f1 = Dense(128,activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10,activation='softmax')
def call(self,x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = BaseLine()
(2)配置网络
import tensorflow as tf
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])
(3)断点存续
import os
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
(4)训练网络
history = model.fit(x_train, y_train, batch_size=32, epochs=20, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
输出:
Epoch 1/20
1563/1563 [==============================] - 7s 5ms/step - loss: 1.6487 - sparse_categorical_accuracy: 0.4042 - val_loss: 1.7451 - val_sparse_categorical_accuracy: 0.3984
Epoch 2/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.4173 - sparse_categorical_accuracy: 0.4892 - val_loss: 1.3221 - val_sparse_categorical_accuracy: 0.5205
Epoch 3/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.3347 - sparse_categorical_accuracy: 0.5230 - val_loss: 1.2711 - val_sparse_categorical_accuracy: 0.5420
Epoch 4/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.2860 - sparse_categorical_accuracy: 0.5405 - val_loss: 1.3197 - val_sparse_categorical_accuracy: 0.5516
Epoch 5/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.2528 - sparse_categorical_accuracy: 0.5514 - val_loss: 1.2001 - val_sparse_categorical_accuracy: 0.5818
Epoch 6/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.2304 - sparse_categorical_accuracy: 0.5614 - val_loss: 1.2040 - val_sparse_categorical_accuracy: 0.5823
Epoch 7/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.2050 - sparse_categorical_accuracy: 0.5707 - val_loss: 1.1599 - val_sparse_categorical_accuracy: 0.5891
Epoch 8/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1855 - sparse_categorical_accuracy: 0.5770 - val_loss: 1.1734 - val_sparse_categorical_accuracy: 0.5864
Epoch 9/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1655 - sparse_categorical_accuracy: 0.5846 - val_loss: 1.1258 - val_sparse_categorical_accuracy: 0.6042
Epoch 10/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1455 - sparse_categorical_accuracy: 0.5928 - val_loss: 1.1898 - val_sparse_categorical_accuracy: 0.5833
Epoch 11/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1310 - sparse_categorical_accuracy: 0.5963 - val_loss: 1.1060 - val_sparse_categorical_accuracy: 0.6095
Epoch 12/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1092 - sparse_categorical_accuracy: 0.6066 - val_loss: 1.1497 - val_sparse_categorical_accuracy: 0.6022
Epoch 13/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0889 - sparse_categorical_accuracy: 0.6142 - val_loss: 1.2842 - val_sparse_categorical_accuracy: 0.5481
Epoch 14/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0734 - sparse_categorical_accuracy: 0.6182 - val_loss: 1.1409 - val_sparse_categorical_accuracy: 0.5986
Epoch 15/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0594 - sparse_categorical_accuracy: 0.6235 - val_loss: 1.1815 - val_sparse_categorical_accuracy: 0.5951
Epoch 16/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0422 - sparse_categorical_accuracy: 0.6308 - val_loss: 1.1000 - val_sparse_categorical_accuracy: 0.6201
Epoch 17/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0275 - sparse_categorical_accuracy: 0.6334 - val_loss: 1.1381 - val_sparse_categorical_accuracy: 0.5969
Epoch 18/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0174 - sparse_categorical_accuracy: 0.6412 - val_loss: 1.1092 - val_sparse_categorical_accuracy: 0.6125
Epoch 19/20
1563/1563 [==============================] - 6s 4ms/step - loss: 1.0030 - sparse_categorical_accuracy: 0.6451 - val_loss: 1.1112 - val_sparse_categorical_accuracy: 0.6149
Epoch 20/20
1563/1563 [==============================] - 6s 4ms/step - loss: 0.9925 - sparse_categorical_accuracy: 0.6489 - val_loss: 1.1262 - val_sparse_categorical_accuracy: 0.6024
#网络信息展示
model.summary()
输出:
Model: "base_line_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) multiple 456
_________________________________________________________________
batch_normalization_2 (Batch multiple 24
_________________________________________________________________
activation_2 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_4 (Dropout) multiple 0
_________________________________________________________________
flatten_2 (Flatten) multiple 0
_________________________________________________________________
dense_4 (Dense) multiple 196736
_________________________________________________________________
dropout_5 (Dropout) multiple 0
_________________________________________________________________
dense_5 (Dense) multiple 1290
=================================================================
Total params: 198,506
Trainable params: 198,494
Non-trainable params: 12
_________________________________________________________________
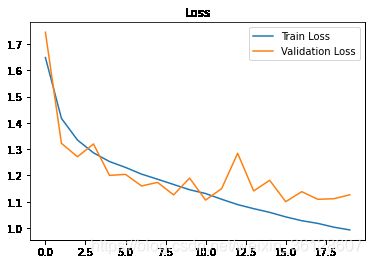
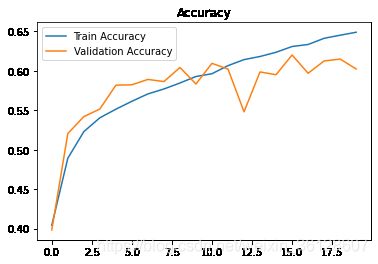
3.ACC曲线图与Loss曲线图
#提取数据
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
#精度曲线
plt.plot(acc,label='Train Accuracy')
plt.plot(val_acc,label='Validation Accuracy')
plt.title('Accuracy')
plt.legend()
plt.show()
#loss曲线
plt.plot(loss,label='Train Loss')
plt.plot(val_loss,label='Validation Loss')
plt.title('Loss')
plt.legend()
plt.show()