DeepLabv2 网络记录
目录
DeepLabv2
一、和DeepLabV1的区别
二、面临的挑战
三、ASPP模块
四、DeepLabV2网络结构
相关博文:
DeepLabv3
DeepLabv1
DeepLabv2网络理解
一、和DeepLabV1的区别
1、V2发表于16年CVPR,2016年目标识别性能最好的网络是Resnet,所以V2用了resnet网络代替VGG16进行特征提取,取得了更好的分割效果。
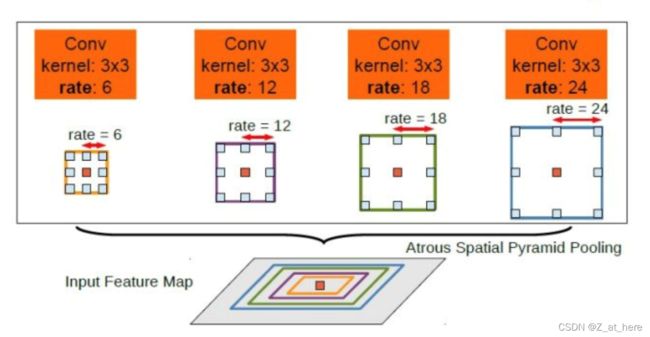
2、引入了新的结构ASPP:空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP))对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
3、fully connected CRF改进成了fully connected pairwise CRF。
该结构在DeepLabv3中被去除掉了。
二、面临的挑战
文中提到了三个挑战,介绍如下:
- 分辨率下降的问题,文中提到主要是重复maxpooling和downsample(主要是DCNNs中stride大于1的卷积层)。
解决方法:例如将maxpool层的stride设置为1,配合空洞卷积一起使用。
使用“空洞卷积”,atrous convolution,即dilated convtion。通过设置不同的扩张率dilation rate,在不增加计算量的情况下,保持输出的分辨率。

- 一张图片中存在不同尺度的目标
解决方法:空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP))。使用不用采样率的空洞卷积进行并行采样,最后将多个并行分支上的结果进行融合。如下图示

- 针对DCNNs平移不变性导致定位精度降低的问题
解决方法:和DeepLabv1差不多还是通过CRF(条件随机场)解决,不过这里用的是改进版的fully connected pairwise CRF,相对于DeepLabv1里面的fully connected CRF要高效点。通过增加fully connected CRF,提升了模型抓取精细的细节的能力。
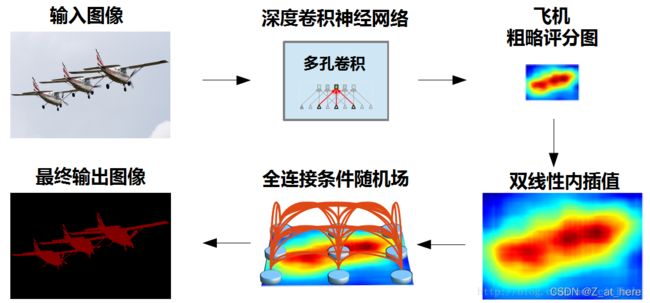
如上图所示,通过级联fully connected CRF的图片细节更加精细。
三、ASPP模块
1、为了对中心像素(橙色)进行分类,ASPP通过使用多个不同速率的并行滤波器来利用多尺度特征。
从resnet输出的featuremap 通过AASPP模块之后,不同rate的空洞卷积输出不同的featuremap,将各个分支的featuremap进行叠加,得到featuremap。每一分支都使用膨胀卷积,每一分支的膨胀系数不同,通过不同的膨胀系数(不同感受野)对不同尺度的目标提取能力不同解决多尺度的问题。


2、论文中有给出两个ASPP的配置,ASPP-S(四个分支膨胀系数分别为2,4,8,12)和ASPP-L(四个分支膨胀系数分别为6,12,18,24),下表是对比LargeFOV、ASPP-S以及ASPP-L的效果。这里只看CRF之前的(before CRF)对比,ASPP-L优于ASPP-S优于LargeFOV。

四、DeepLabV2网络结构
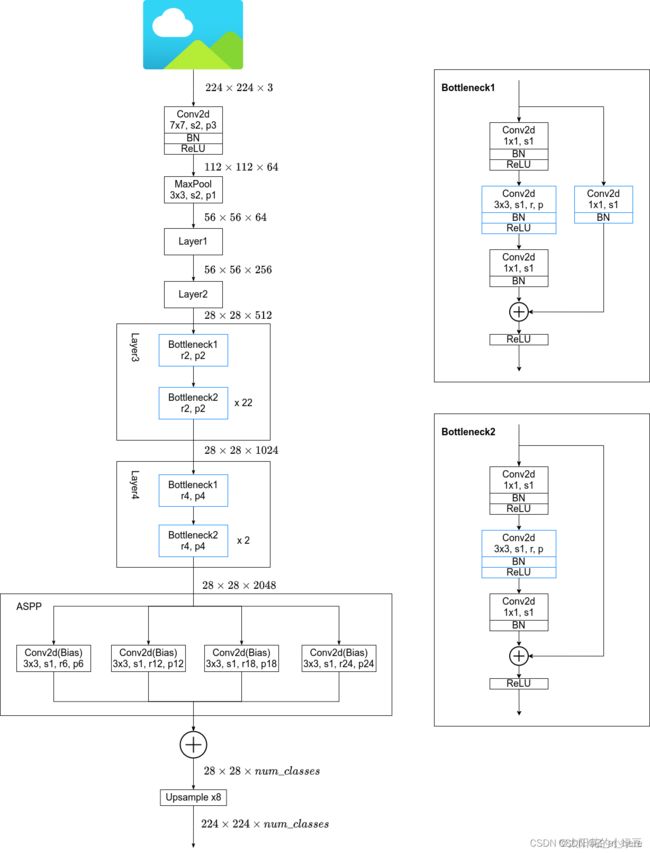
这里以ResNet101作为backbone为例,下图是根据官方源码绘制的网络结构(这里不考虑MSC即多尺度)。在ResNet的Layer3中的Bottleneck1中原本是需要下采样的(3x3的卷积层stride=2),但在DeepLab V2中将stride设置为1,即不在进行下采样。而且3x3卷积层全部采用膨胀卷积膨胀系数为2。在Layer4中也是一样,取消了下采样,所有的3x3卷积层全部采用膨胀卷积膨胀系数为4。最后需要注意的是ASPP模块,在以ResNet101做为Backbone时,每个分支只有一个3x3的膨胀卷积层,且卷积核的个数都等于num_classes。
原文链接:https://blog.csdn.net/qq_37541097/article/details/121752679
Reference:
原文链接:论文阅读 || 语义分割系列 —— deeplabv3详解_magic_ll的博客-CSDN博客_deeplabv3
原文链接:
【语义分割系列:五】DeepLab v3 / v3+ 论文阅读翻译笔记_鹿鹿的博客-CSDN博客_deeplabv3+论文翻译
原文链接:
Semantic Segmentation -- (DeepLabv3)Rethinking Atrous Convolution for Semantic Image Segmentation论文解_DFan的NoteBook-CSDN博客
原文链接:
【语义分割系列:一】DeepLab v1 / v2 论文阅读翻译笔记_鹿鹿的博客-CSDN博客_deeplab翻译
特别:
CSDN博主「太阳花的小绿豆」的原创文章:(本人多次参考该博主的视频和文章)
原文链接:DeepLabV3网络简析_霹雳吧啦Wz-CSDN博客_deeplabv3