NNDL 实验五 前馈神经网络(3)鸢尾花分类
深入研究鸢尾花数据集
画出数据集中150个数据的前两个特征的散点分布图:
【统计学习方法】感知机对鸢尾花(iris)数据集进行二分类

4.5 实践:基于前馈神经网络完成鸢尾花分类
继续使用第三章中的鸢尾花分类任务,将Softmax分类器替换为前馈神经网络。
损失函数:交叉熵损失;
优化器:随机梯度下降法;
评价指标:准确率。
4.5.1 小批量梯度下降法
为了减少每次迭代的计算复杂度,我们可以在每次迭代时只采集一小部分样本,计算在这组样本上损失函数的梯度并更新参数,这种优化方式称为小批量梯度下降法(Mini-Batch Gradient Descent,Mini-Batch GD)。
为了小批量梯度下降法,我们需要对数据进行随机分组。
目前,机器学习中通常做法是构建一个数据迭代器,每个迭代过程中从全部数据集中获取一批指定数量的数据。
4.5.2 数据处理
import numpy as np
import torch
class IrisDataset(torch.utils.data.Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
# 调用第三章中的数据读取函数,其中不需要将标签转成one-hot类型
X, y = load_data(shuffle=True)
if mode == 'train':
self.X, self.y = X[:num_train], y[:num_train]
elif mode == 'dev':
self.X, self.y = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.X, self.y = X[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
def __len__(self):
return len(self.y)
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
# 打印数据集长度
print ("length of train set: ", len(train_dataset))
print ("length of dev set: ", len(dev_dataset))
print ("length of test set: ", len(test_dataset))
# 批量大小
batch_size = 16
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = torch.utils.data.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
4.5.3 模型构建
from torch import nn
# 定义前馈神经网络
class Model_MLP_L2_V3(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Model_MLP_L2_V3, self).__init__()
# 构建第一个全连接层
self.fc1 = nn.Linear(input_size,hidden_size)
nn.init.normal_(tensor=self.fc1.weight,mean=0.0, std=0.01)
nn.init.constant_(tensor=self.fc1.bias,val=1.0)
# 构建第二全连接层
self.fc2 = nn.Linear(hidden_size,output_size)
nn.init.normal_(tensor=self.fc2.weight,mean=0.0, std=0.01)
nn.init.constant_(tensor=self.fc2.bias,val=1.0)
# 定义网络使用的激活函数
self.act = nn.Sigmoid()
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
return outputs
fnn_model = Model_MLP_L2_V3(input_size=4, output_size=3, hidden_size=6)
输入层神经元个数为4,输出层神经元个数为3,隐含层神经元个数为6。

4.5.4 完善Runner类
import torchmetrics
class Accuracy():
def __init__(self, is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.cast((outputs>=0), dtype='float32')
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.cast((outputs>=0.5), dtype='float32')
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, axis=1, dtype='int64')
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, axis=-1)
batch_correct = torch.sum(torch.cast(preds==labels, dtype="float32")).numpy()[0]
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
import torch.nn.functional as F
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step,loss.item()))
if log_steps and global_step%log_steps==0:
print(f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.clear_grad()
# 判断是否需要评价
if eval_steps>0 and global_step>0 and \
(global_step%eval_steps == 0 or global_step==(num_training_steps-1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss/len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step!=-1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
paddle.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
model_state_dict = paddle.load(model_path)
self.model.set_state_dict(model_state_dict)
4.5.5 模型训练
import torch.optim as opt
import torch.nn.functional as F
lr = 0.2
# 定义网络
model = fnn_model
# 定义优化器
optimizer = opt.SGD(lr=lr, params=model.parameters())
# 定义损失函数。softmax+交叉熵
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 100
eval_steps = 50
runner.train(train_loader, dev_loader,
num_epochs=150, log_steps=log_steps, eval_steps = eval_steps,
save_path="best_model.pdparams")
4.5.6 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# a
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
4.5.7 模型预测
test_loader = iter(test_loader)
# 获取测试集中第一条数据
(X, label) = next(test_loader)
logits = runner.predict(X)
pred_class = torch.argmax(logits[0]).numpy()
label = label.numpy()[0]
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
思考题
1. 对比Softmax分类和前馈神经网络分类。(必做)
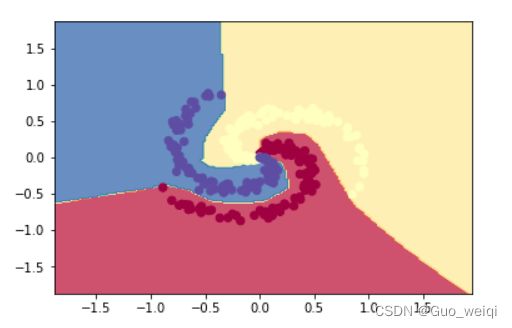
#Train a Linear Classifier
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D))
y = np.zeros(N*K, dtype='uint8')
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(1000):
#print X.shape
# evaluate class scores, [N x K]
scores = np.dot(X, W) + b #x:300*2 scores:300*3
#print scores.shape
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] probs:300*3
#print(probs.shape)
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y]) #corect_logprobs:300*1
#print(corect_logprobs.shape)
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 100 == 0:
print("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update
W += -step_size * dW
b += -step_size * db
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()#Train a Linear Classifier
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D))
y = np.zeros(N*K, dtype='uint8')
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(1000):
#print X.shape
# evaluate class scores, [N x K]
scores = np.dot(X, W) + b #x:300*2 scores:300*3
#print scores.shape
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] probs:300*3
#print(probs.shape)
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y]) #corect_logprobs:300*1
#print(corect_logprobs.shape)
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 100 == 0:
print("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update
W += -step_size * dW
b += -step_size * db
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()