NNDL 实验七 循环神经网络(1)RNN记忆能力实验
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络.
在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构.
和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构.
目前,循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上.
简单循环网络在参数学习时存在长程依赖问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。
为了测试简单循环网络的记忆能力,本节构建一个【数字求和任务】进行实验。
数字求和任务的输入是一串数字,前两个位置的数字为0-9,其余数字随机生成(主要为0),预测目标是输入序列中前两个数字的加和。图6.3展示了长度为10的数字序列.
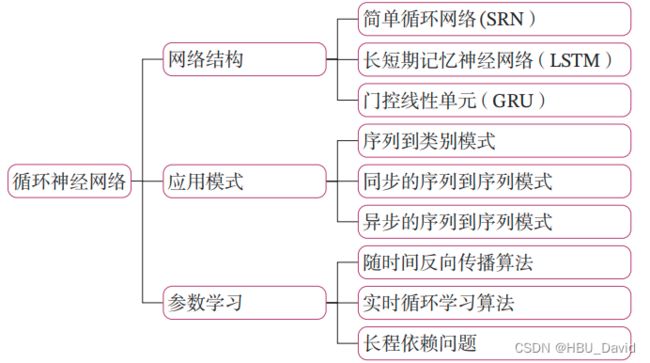
6.1 循环神经网络的记忆能力实验
循环神经网络的一种简单实现是简单循环网络(Simple Recurrent Network,SRN)

简单循环网络在参数学习时存在长程依赖问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。为了测试简单循环网络的记忆能力,本节构建一个数字求和任务进行实验。
数字求和任务的输入是一串数字,前两个位置的数字为0-9,其余数字随机生成(主要为0),预测目标是输入序列中前两个数字的加和。图6.3展示了长度为10的数字序列.
如果序列长度越长,准确率越高,则说明网络的记忆能力越好.因此,我们可以构建不同长度的数据集,通过验证简单循环网络在不同长度的数据集上的表现,从而测试简单循环网络的长程依赖能力.
6.1.1 数据集构建
构建不同长度的数字预测数据集DigitSum
6.1.1.1 数据集的构建函数
import os
import torch
import random
import numpy as np
import torch.nn as nn
# 固定随机种子
random.seed(0)
np.random.seed(0)
def generate_data(length, k, save_path):
if length < 3:
raise ValueError("The length of data should be greater than 2.")
if k == 0:
raise ValueError("k should be greater than 0.")
# 生成100条长度为length的数字序列,除前两个字符外,序列其余数字暂用0填充
base_examples = []
for n1 in range(0, 10):
for n2 in range(0, 10):
seq = [n1, n2] + [0] * (length - 2)
label = n1 + n2
base_examples.append((seq, label))
examples = []
# 数据增强:对base_examples中的每条数据,默认生成k条数据,放入examples
for base_example in base_examples:
for _ in range(k):
# 随机生成替换的元素位置和元素
idx = np.random.randint(2, length)
val = np.random.randint(0, 10)
# 对序列中的对应零元素进行替换
seq = base_example[0].copy()
label = base_example[1]
seq[idx] = val
examples.append((seq, label))
# 保存增强后的数据
with open(save_path, "w", encoding="utf-8") as f:
for example in examples:
# 将数据转为字符串类型,方便保存
seq = [str(e) for e in example[0]]
label = str(example[1])
line = " ".join(seq) + "\t" + label + "\n"
f.write(line)
print(f"generate data to: {save_path}.")
# 定义生成的数字序列长度
lengths = [5, 10, 15, 20, 25, 30, 35]
for length in lengths:
# 首先判断是否存在这样的数据文件,不存在就建立一个
if not os.path.exists(f"./datasets/{length}/"):
os.makedirs(f"./datasets/{length}")
# 生成长度为length的训练数据
save_path = f"./datasets/{length}/train.txt"
k = 3
generate_data(length, k, save_path)
# 生成长度为length的验证数据
save_path = f"./datasets/{length}/dev.txt"
k = 1
generate_data(length, k, save_path)
# 生成长度为length的测试数据
save_path = f"./datasets/{length}/test.txt"
k = 1
generate_data(length, k, save_path)6.1.1.2 加载数据并进行数据划分
# 加载数据
def load_data(data_path):
# 加载训练集
train_examples = []
train_path = os.path.join(data_path, "train.txt")
with open(train_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
train_examples.append((seq, label))
# 加载验证集
dev_examples = []
dev_path = os.path.join(data_path, "dev.txt")
with open(dev_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
dev_examples.append((seq, label))
# 加载测试集
test_examples = []
test_path = os.path.join(data_path, "test.txt")
with open(test_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
test_examples.append((seq, label))
return train_examples, dev_examples, test_examples
# 设定加载的数据集的长度
length = 5
# 该长度的数据集的存放目录
data_path = f"./datasets/{length}"
# 加载该数据集
train_examples, dev_examples, test_examples = load_data(data_path)
print("dev example:", dev_examples[:2])
print("训练集数量:", len(train_examples))
print("验证集数量:", len(dev_examples))
print("测试集数量:", len(test_examples))
6.1.1.3 构造Dataset类
class DigitSumDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
example = self.data[idx]
seq = torch.tensor(example[0], dtype=torch.int64)
label = torch.tensor(example[1], dtype=torch.int64)
return seq, label
def __len__(self):
return len(self.data)6.1.2 模型构建
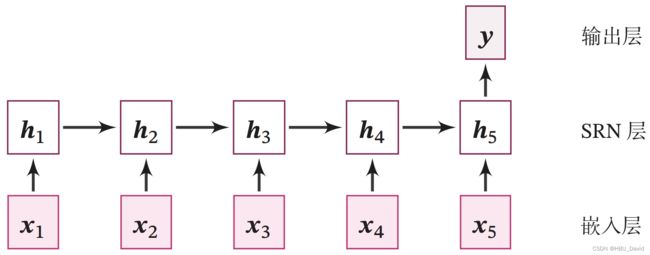
6.1.2.1 嵌入层
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(Embedding, self).__init__()
# 定义嵌入矩阵
self.W = torch.nn.Parameter(torch.Tensor(num_embeddings, embedding_dim))
def forward(self, inputs):
# 根据索引获取对应词向量
embs = self.W[inputs]
return embs
emb_layer = Embedding(10, 5)
inputs = torch.tensor([0, 1, 2, 3])
emb_layer(inputs)
print(emb_layer(inputs))6.1.2.2 SRN层
自定义简单循环网络
飞桨框架内置了SRN的API paddle.nn.SimpleRNN
将自己实现的SRN和Paddle框架内置的SRN返回的结果进行打印展示
import torch.nn.functional as F
torch.manual_seed(0)
# SRN模型
class SRN(nn.Module):
def __init__(self, input_size, hidden_size, W_attr=None, U_attr=None, b_attr=None):
super(SRN, self).__init__()
# 嵌入向量的维度
self.input_size = input_size
# 隐状态的维度
self.hidden_size = hidden_size
# 定义模型参数W,其shape为 input_size x hidden_size
self.W = torch.nn.Parameter(torch.Tensor(input_size, hidden_size), torch.float32, attr=W_attr)
# 定义模型参数U,其shape为hidden_size x hidden_size
self.U = torch.nn.Parameter(torch.Tensor(hidden_size, hidden_size), torch.float32, attr=U_attr)
# 定义模型参数b,其shape为 1 x hidden_size
self.b = torch.nn.Parameter(torch.Tensor(1, hidden_size), torch.float32, attr=b_attr)
# 初始化向量
def init_state(self, batch_size):
hidden_state = torch.zeros([batch_size, self.hidden_size], dtype=torch.float32)
return hidden_state
# 定义前向计算
def forward(self, inputs, hidden_state=None):
# inputs: 输入数据, 其shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = inputs.shape
# 初始化起始状态的隐向量, 其shape为 batch_size x hidden_size
if hidden_state is None:
hidden_state = self.init_state(batch_size)
# 循环执行RNN计算
for step in range(seq_len):
# 获取当前时刻的输入数据step_input, 其shape为 batch_size x input_size
step_input = inputs[:, step, :]
# 获取当前时刻的隐状态向量hidden_state, 其shape为 batch_size x hidden_size
hidden_state = F.tanh(torch.matmul(step_input, self.W) + torch.matmul(hidden_state, self.U) + self.b)
return hidden_state# 初始化参数并运行
from torch.nn.parameter import Parameter
m = torch.nn.Linear(2, 2)
W_attr = torch.normal([[0.1, 0.2], [0.1, 0.2]], size=(2, 2), requires_grad=True)
U_attr = torch.normal([[0.0, 0.1], [0.1, 0.0]], size=(2, 2), requires_grad=True)
b_attr = torch.normal([[0.1, 0.1]], size=(2, 2), requires_grad=True)
m.W_attr = Parameter(W_attr)
m.U_attr = Parameter(U_attr)
m.b_attr = Parameter(b_attr)
srn = SRN(2, 2, W_attr=m.W_attr, U_attr=m.U_attr, b_attr=m.b_attr)
inputs = torch.tensor([[[1, 0], [0, 2]]], dtype=torch.float32)
hidden_state = srn(inputs)
print("hidden_state", hidden_state)hidden_state Tensor(shape=[1, 2], dtype=float32, place=Place(gpu:0),stop_gradient=False, [[0.34261486, 0.4845248]])
将自己实现的SRN与Paddle内置的SRN在输出值的精度上进行对比
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = 8, 20, 32
inputs = torch.randn([batch_size, seq_len, input_size])
# 设置模型的hidden_size
hidden_size = 32
paddle_srn = nn.SimpleRNN(input_size, hidden_size)
self_srn = SRN(input_size, hidden_size)
self_hidden_state = self_srn(inputs)
paddle_outputs, paddle_hidden_state = paddle_srn(inputs)
print("self_srn hidden_state: ", self_hidden_state.shape)
print("torch_srn outpus:", paddle_outputs.shape)
print("torch_srn hidden_state:", paddle_hidden_state.shape)self_srn hidden_state: [8, 32]
torch_srn outpus: [8, 20, 32]
torch_srn hidden_state: [1, 8, 32]
在进行实验时,首先定义输入数据inputs,然后将该数据分别传入Paddle内置的SRN与自己实现的SRN模型中,最后通过对比两者的隐状态输出向量。
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size, hidden_size = 2, 5, 10, 10
inputs = torch.randn([batch_size, seq_len, input_size])
# 设置模型的hidden_size
torch_srn = nn.RNN(input_size, hidden_size, bias=False)
# 获取torch_srn中的参数,并设置相应的paramAttr,用于初始化SRN
W_attr = torch_srn.weight_ih_l0.T
U_attr = torch_srn.weight_hh_l0.T
self_srn = SRN(input_size, hidden_size, W_attr=W_attr, U_attr=U_attr)
# 进行前向计算,获取隐状态向量,并打印展示
self_hidden_state = self_srn(inputs)
torch_outputs, torch_hidden_state = torch_srn(inputs)
print("torch SRN:\n", torch_hidden_state.detach().numpy().squeeze(0))
print("self SRN:\n", self_hidden_state.detach().numpy())paddle SRN:
[[ 0.3246606 -0.05465741 -0.3090897 -0.51604617 -0.11149617 0.4267313
0.47200006 -0.06585315 0.85319966 0.18898569]
[-0.4299355 -0.6067489 -0.59150505 0.30245274 -0.03939498 0.61462754
0.4030218 0.49883503 0.02484456 -0.38516262]]
self SRN:
[[ 0.32466057 -0.05465744 -0.3090897 -0.51604617 -0.11149605 0.4267313
0.47200006 -0.06585318 0.85319966 0.18898569]
[-0.42993543 -0.6067488 -0.59150493 0.3024528 -0.03939501 0.61462754
0.40302184 0.49883503 0.02484456 -0.38516262]]
import time
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size, hidden_size = 2, 5, 10, 10
inputs = torch.randn([batch_size, seq_len, input_size])
# 实例化模型
self_srn = SRN(input_size, hidden_size)
paddle_srn = nn.SimpleRNN(input_size, hidden_size)
# 计算自己实现的SRN运算速度
model_time = 0
for i in range(100):
strat_time = time.time()
out = self_srn(inputs)
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
end_time = time.time()
model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('self_srn speed:', avg_model_time, 's')
# 计算Paddle内置的SRN运算速度
model_time = 0
for i in range(100):
strat_time = time.time()
out = paddle_srn(inputs)
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
end_time = time.time()
model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('paddle_srn speed:', avg_model_time, 's')self_srn speed: 0.0016264581504632564 s
paddle_srn speed: 0.0004503216208923415 s
6.1.2.3 线性层
线性层直接使用paddle.nn.Linear算子。
6.1.2.4 模型汇总
在定义了每一层的算子之后,我们定义一个数字求和模型Model_RNN4SeqClass,该模型会将嵌入层、SRN层和线性层进行组合,以实现数字求和的功能.
# 基于RNN实现数字预测的模型
class Model_RNN4SeqClass(nn.Module):
def __init__(self, model, num_digits, input_size, hidden_size, num_classes):
super(Model_RNN4SeqClass, self).__init__()
# 传入实例化的RNN层,例如SRN
self.rnn_model = model
# 词典大小
self.num_digits = num_digits
# 嵌入向量的维度
self.input_size = input_size
# 定义Embedding层
self.embedding = Embedding(num_digits, input_size)
# 定义线性层
self.linear = nn.Linear(hidden_size, num_classes)
def forward(self, inputs):
# 将数字序列映射为相应向量
inputs_emb = self.embedding(inputs)
# 调用RNN模型
hidden_state = self.rnn_model(inputs_emb)
# 使用最后一个时刻的状态进行数字预测
logits = self.linear(hidden_state)
return logits
# 实例化一个input_size为4, hidden_size为5的SRN
srn = SRN(4, 5)
# 基于srn实例化一个数字预测模型实例
model = Model_RNN4SeqClass(srn, 10, 4, 5, 19)
# 生成一个shape为 2 x 3 的批次数据
inputs = torch.tensor([[1, 2, 3], [2, 3, 4]])
# 进行模型前向预测
logits = model(inputs)
print(logits)6.1.3 模型训练
6.1.3.1 训练指定长度的数字预测模型
import os
import random
import numpy as np
# 训练轮次
num_epochs = 500
# 学习率
lr = 0.001
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 8
# 模型保存目录
save_dir = "./checkpoints"
# 通过指定length进行不同长度数据的实验
def train(length):
print(f"\n====> Training SRN with data of length {length}.")
# 固定随机种子
np.random.seed(0)
random.seed(0)
torch.manual_seed(0)
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples), DigitSumDataset(test_examples)
train_loader = torch.io.DataLoader(train_set, batch_size=batch_size)
dev_loader = torch.io.DataLoader(dev_set, batch_size=batch_size)
test_loader = torch.io.DataLoader(test_set, batch_size=batch_size)
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.Adam(lr, parameters=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 基于以上组件,实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 进行模型训练
model_save_path = os.path.join(save_dir, f"best_srn_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=100, save_path=model_save_path)
return runnerimport torch
# 新增准确率计算函数
def accuracy(preds, labels):
"""
输入:
- preds:预测值,二分类时,shape=[N, 1],N为样本数量,多分类时,shape=[N, C],C为类别数量
- labels:真实标签,shape=[N, 1]
输出:
- 准确率:shape=[1]
"""
print(preds)
# 判断是二分类任务还是多分类任务,preds.shape[1]=1时为二分类任务,preds.shape[1]>1时为多分类任务
if preds.shape[1] == 1:
# 二分类时,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
# 使用'torch.can_cast'将preds的数据类型转换为float32类型
preds = torch.can_cast((preds>=0.5).dtype,to=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(preds,dim=1)
torch.can_cast(preds.dtype,torch.int32)
return torch.mean(torch.tensor((preds == labels), dtype=torch.float32))
class Accuracy():
def __init__(self):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = True
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.can_cast((outputs>=0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.can_cast((outputs>=0.5), dtype=torch.float32)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).int()
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
y = y.cuda()
# 获取模型预测
logits = self.model(X)
logits = logits.cuda()
y = y.to(dtype=torch.int64)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
X = X.cuda()
y = y.cuda()
# 计算模型输出
logits = self.model(X)
logits = logits.cuda()
# 计算损失函数
y=y.to(dtype=torch.int64)
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)6.1.3.2 多组训练
srn_runners = {}
lengths = [10, 15, 20, 25, 30, 35]
for length in lengths:
runner = train(length)
srn_runners[length] = runner6.1.3.3 损失曲线展示
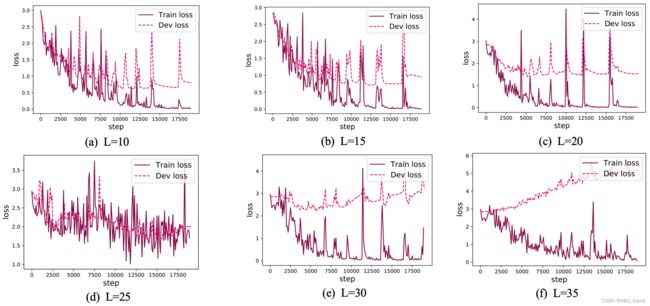
图6.6展示了在6个数据集上的损失变化情况,数据集的长度分别为10、15、20、25、30和35. 从输出结果看,随着数据序列长度的增加,虽然训练集损失逐渐逼近于0,但是验证集损失整体趋向越来越大,这表明当序列变长时,SRN模型保持序列长期依赖能力在逐渐变弱,越来越无法学习到有用的知识.
import matplotlib.pyplot as plt
def plot_training_loss(runner, fig_name, sample_step):
plt.figure()
train_items = runner.train_step_losses[::sample_step]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#e4007f', label="Train loss")
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#f19ec2', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("step", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()# 画出训练过程中的损失图
for length in lengths:
runner = srn_runners[length]
fig_name = f"./images/6.6_{length}.pdf"
plot_training_loss(runner, fig_name, sample_step=100)6.1.4 模型评价

srn_dev_scores = []
srn_test_scores = []
for length in lengths:
print(f"Evaluate SRN with data length {length}.")
runner = srn_runners[length]
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"best_srn_model_{length}.pdparams")
runner.load_model(model_path)
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
test_set = DigitSumDataset(test_examples)
test_loader = torch.io.DataLoader(test_set, batch_size=batch_size)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
srn_test_scores.append(score)
srn_dev_scores.append(max(runner.dev_scores))
for length, dev_score, test_score in zip(lengths, srn_dev_scores, srn_test_scores):
print(f"[SRN] length:{length}, dev_score: {dev_score}, test_score: {test_score: .5f}")import matplotlib.pyplot as plt
plt.plot(lengths, srn_dev_scores, '-o', color='#e4007f', label="Dev Accuracy")
plt.plot(lengths, srn_test_scores,'-o', color='#f19ec2', label="Test Accuracy")
#绘制坐标轴和图例
plt.ylabel("accuracy", fontsize='large')
plt.xlabel("sequence length", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
fig_name = "./images/6.7.pdf"
plt.savefig(fig_name)
plt.show()总结:通过这次实验,对循环神经网络更加了解,熟悉。