论文笔记——《Rich feature hierarchies for accurate object detection and semantic segmentation》
标题:用于精确的对象检测和语义分割的丰富特征层级结构
(待补充)
(这是一篇介绍R-CNN模型的论文,发表于2014年的CVPR)
abstact:
1、使用R-CNN使mAP提高至53.3%
2、本文的方法的关键主要有两点:
i>结合大容量的卷积神经网络(CNN)和自下而上的候选框(region proposals),即R-CNN,用于对象的定位和切割;
ii>当已标记的训练数据缺失时,CNN网络可以通过有监督的预训练和针对特定领域的微调(fine-tuning)来提高性能。
iii>源码地址: https://cs.berkeley.edu/ ~rbg/rcnn
1.Introduction
i>传统CV算法(SIFT和HOG)在最近几年进展缓慢,CNNs在2012年ILSVRC大赛上的高图像分类精度使得其重新受人关 注,CNNS的成功得益于大量的训练图像数据和一些方法(例如max(x,0)处理非线性,“dropout”正则化);
ii>由此引出问题:是否能将CNN图像分类的结果推广到目标检测中来?
iii>本文专注两个问题:用深层网络定位目标,以及使用少量的标注检测数据训练出一个高容量的模型。
iv>对于第一个问题:目标检测需要在图像中检测出多个目标。一种方案是将定位看成是回归问题,但是实践起来效果不好, mAP过低;另一种替代方案是使用滑动窗口扫描图像,但是由于网络较深,输入较大,存在许多技术难题,最后决定使用“recognition using region”。对每一个样本图像,先生成2000个独立的region proposals,然后对每一个region proposals用CNN提取出固定长度的特征向量,最后用线性SVM(每个类别对应一个SVM)对其分类。
v>对于第二个问题:使用之前在ILSVRC中为了给图像分类有监督训练出来的CNN运用到PASCAL的目标检测中,并进行一定的fine-tuning,能提高8%的mAP。同时,文中作者还发现Krizhevsky的CNN能作为黑盒特征提取器。
vi>同时文中的系统的计算方法更有效率,文中列出了数据对比。
vii>除此之外,了解该方法的失效模式有助于提高自己的模型。所以文中会给出应用Hoiem等人的检测分析工具的结果。结果证明简单的边界框回归方法能减少错误定位。
viii>最后会将R-CNN应用于语义分割,实验显示在VOC 2011测试集上的平均分割准确度为47.9%。
2.Object detection with R-CNN
① 用于目标的R-CNN分为三个模块。第一部分是包含与类别无关的region proposals,这些region proposals作为每个图像的候选检测数据集;第二部分是一个大型CNN,用于在每个region proposals中提取固定长度的特征向量;第三部分是一系列的不同类别的线性SVM分类器。
②模块设计:
- Region proposals:使用selective search来生成与类别无关的候选框,从而能与先前的检测工作作可控的比较。
- 特征提取:使用Caffe框架生成Krizhevsky设计的CNN(包含5个卷积层和2个全连接层),从227 X 227的RGB图像(区域)
中提取出4096维特征向量。(CNN的结构细节可以参考22,23参考文献) 。同时,为了匹配CNN的固定输入(227 X 227 的像素大小) ,需要将region proposals图像warp成227 X 227的大小,为此需要在原始边界框上扩充一定像素p(这里p = 16)。
3.Visualization, ablation, and modes of error
① 特征可视化
② 减少参数的研究
1、Performance layer-by-layer, without fine-tuning
CNN的检测能力主要来自卷积层(参数总量只占了6%左右),而且实验表明使用最后一层的输出特征进行检测的结果差于前一层FC的结果,这意味着删除最后一层不会降低mAp(参数总量占29%,约16.8 million的参数)。
2、Performance layer-by-layer, with fine-tuning
fine-tuning后mAP有一定的提升,且FC层的提升更显著,表明卷积层学习到的特征是general的,FT的提升主要来自具体领域的非线性分类器。
3、Comparion to recent feature learning methods
明显优于过去的方法。
③ 检测错误的原因分析和边界框回归的应用
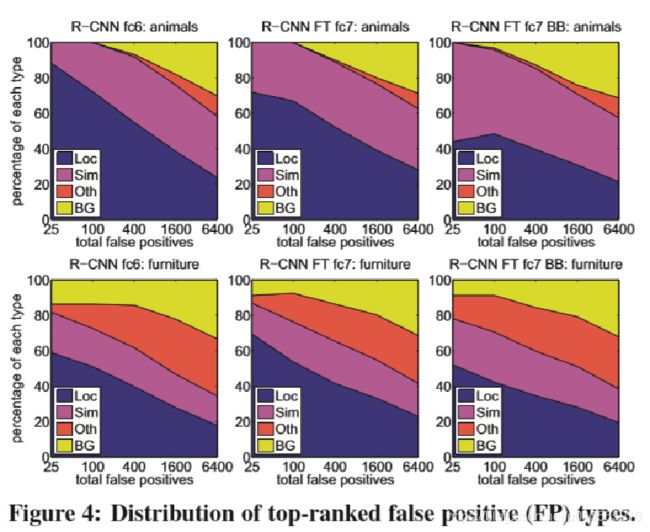
根据错误检测分析的结果,如图前两列,可以看出主要的错来自Loc(错误定位,正例的IoU在0.1到0.5之间或者duplicate)。表明CNN的特征比HOG等传统算法的特征更有辨识力。
解决方法:针对Loc,提出了边界框回归(Bound box regression),训练一个线性回归模型,给每一个region proposal预测一个新的边界,从而精细修正候选框位置。
4.Semantic segmentation
过去的语义切割的主要算法是O2P(二阶池化,second-order pooling)。
CNN features for segmentation
- strategy1(full):忽略region的形状,直接在warped region上计算CNN的特征
- strategy2(fg):“this strategy computes CNN features only on a region’s foreground mask. We replace the background with the mean input so that background regions are zero after mean subtraction.”
- strategy3(full+fg):strategy1和strategy2结合

i> fc6的结果略好于fc7,策略3的mean accuracy更高且略高于O2P。
ii> R-CNN相比于O2P速度更快。
iii> fine-tuning后结果可能更好。
5.Conclusion