【论文解读】CIKM20-MiNet:阿里|跨域点击率预估混合兴趣模型
“ 本文介绍了阿里提出的一种利用跨域信息的CTR预估模型,基于UC头条的应用场景,将新闻feed流作为源域,广告作为目标域。跨域点击率预估的最大优势在于通过使用跨域数据,目标域中的数据稀疏和冷启动问题都能得到缓解,这也是为什么能提高推荐性能的原因。”
本文要介绍的论文是《MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction》
论文下载地址为:https://arxiv.org/abs/2008.02974,公众号后台回复【minet】可下载
1.前言
1.1 跨域推荐(cross-domain recommendation)的概念
在读这篇论文之前,其实我对跨域推荐是毫无概念的,而偏偏这篇论文又把related work放到了最后,导致刚开始看的时候一直是迷迷糊糊,所以先详细的把跨域推荐的概念做个记录。
为了读懂论文,首先要引入”跨域推荐“的概念。什么是”域“呢?简单的来说,可以把它看做是通过某种方式聚集在一起的集合。比如可以把新闻app中的某一个板块当做一个域,也可以是b站的鬼畜区,舞蹈区等等。当然我们也可以扩大域的概念,把短视频整体当成一个域,把pgc当成一个域。这些定义应该都是可以的,域的概念其实可大可小。
那什么叫”跨域“呢?可能常见的推荐场景都是单域推荐比较多,也就是”游戏“只推荐”游戏“类的东西,它基于的数据也都是游戏用户本身的东西。但什么是”跨域推荐“呢?比如,我要给“鬼畜区”推荐东西,但是使用的数据不只是鬼畜区自己的,它还包括了”舞蹈区“,”数码区“,”游戏区“等其他域产生的数据。
对于此,我们要定义两个”域“的概念:”源域“和”目标域“,我们要优化、提升的目标叫做”目标域“,比如我们要优化”鬼畜区“的ctr,那么“鬼畜区”就是“目标域”。而”源域“相当于是辅助的部分,我们会把“舞蹈区”,“数码区”等看做是“源域”。
总结一下:
”域“指的是通过某种方式聚集在一起的集合。”域“的定义可大可小。
只要是两个不一样的集合之间互相使用数据都可以称之为”跨域“
1.2 跨域推荐的细节
跨域推荐实际是有一种前提的,就是基于重叠(overlap)。为什么会有跨域?那是因为有一部分的特征也好、用户也好、物品也好,能够有一些重叠,通过重叠的部分找到两个域之间的一些关联。
从下图我们可以看到,横坐标代表了物品的整个空间,纵坐标代表了用户的整个空间:
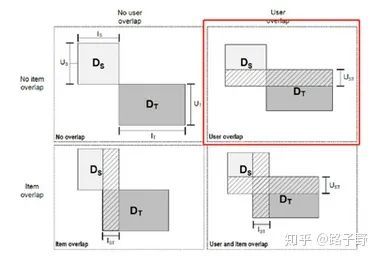
第一张图(左上图),用户与物品之间没有都没有交集
第二张图(右上图),两个域的用户有部分交集,但是物品没有交集。这种情况可以理解成鬼畜用户和舞蹈用户会有部分交集,这部分用户他们既访问了鬼畜区的视频又去舞蹈区看了小姐姐。
第三张图(左下图),是两个域的用户没有交集,但是物品有部分重合。一种可能的情况:youtube和b站的用户在法定情况下是不一样的,但是b站的部分内容又是从youtube上搬运过来的,这就满足了第三种情况。
第四张图(右下图),这个场景的重合度就比较高了,不论是用户还是物品都有一定程度上的重叠,这在b站上也是很常见的,比如自制区的视频同时也是数码区的视频。
1.3 跨域推荐的优劣
那么到底为什么要用跨域推荐呢?它的优劣有哪些呢?
优势:
首先,它可以用来解决一部分冷启动的问题,从上图可以看到,目标域的新用户很可能是源域的旧用户,那么将源域的信息拿过来辅助提升推荐的效果,能一定程度上解决冷启动
第二点就是提升目标域的推荐效果,这个也是跨域推荐的主要目的。
第三个优势是多样性。因为跨域推荐同时参考了多个域的特征,自然而然会对推荐结果的多样性进行一定的优化。最终,它还会反作用于源域,能够实现源域的推荐与目标的域推荐效果的共同提升。
劣势:
跨域推荐还需要考虑一定的权衡,因为跨域必然会导致数据的稀疏,处理不当可能会有反作用。我们从前一幅图可以看到:用户空间与物品空间为例,一旦涉及到跨域上下两个方块必然会引入空白,空白的稠密度相当于0,所以跨域推荐必然会导致数据更加稀疏。所以我们要处理这种数据稀疏,避免产生反作用。
2.背景
目前的CTR模型主要都是解决单域推荐的问题,比如做广告的ctr预估,就只使用广告的user behacior history来训练模型。然而,广告通常是和一些自然内容一起展示出来的,比如视频,音乐,资讯等,尽管广告的内容和自然内容差异较大,但是用户在自然内容上的浏览行为也可能会对广告点击率预估提供有用的信息,比如一个用户浏览了一些娱乐方面的资讯,那他点击游戏广告的概率就会更高。因此,这就提供了一个使用跨域推荐的机会。
本文基于UC头条的应用场景,将新闻feed流作为源域,广告作为目标域。跨域点击率预估的最大优势在于通过使用跨域数据,目标域中的数据稀疏和冷启动问题都能得到缓解,这也是为什么能提高推荐性能的原因。

3.模型设计
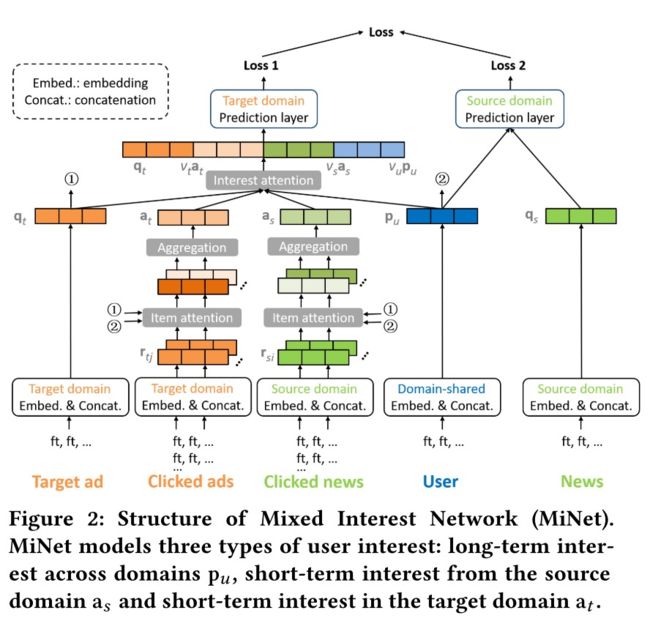
为了更好的利用好跨域数据,文中建模了三种不同的user interest:
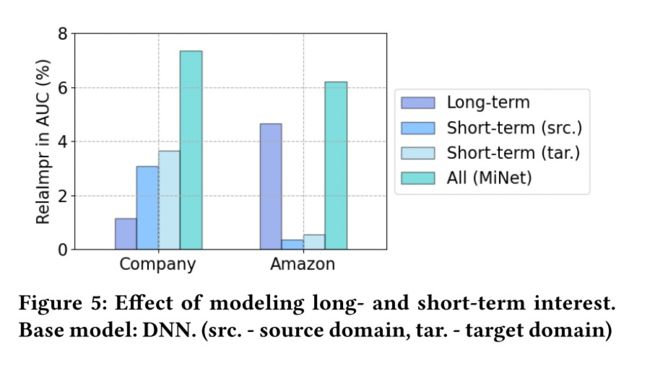
跨域长期兴趣(Long-term interest across domains).用户的profile feature能反映出他长期的、固有的兴趣。通过跨域数据(用户交互过得所有的新闻和广告记录)可以学习出一个包含更多语义信息和可信度更高的user embedding。简单来说,就是通过用户的基本信息建模用户的内在长期兴趣
源域短期兴趣(Short-term interest from the source domain).对于每个待预估的广告,都会有一个源域的短期用户兴趣与之关联。尽管广告和新闻的内容可能是完全不同,但其中很可能会存在一个确定的相关性比,如看了娱乐新闻后的用户可能会去点击游戏广告。基于这种相关性,我们能把源域的有用信息迁移到目标域来。简单来说就是对用户在源域的短期行为进行建模
目标域短期兴趣(Short-term interest from the target domain).这个不言而喻了,就不多阐述了,简单来说就是对用户在目标域的短期行为进行建模
尽管上面的三种user interest看起来可行性很高,但依然存在几个问题:
不是所有交互过的新闻都和目标广告有关系
同样,也不是所有交互过的广告都和目标广告有关系
模型必须能把信息从源域迁移到目标域
对于每个目标广告,三种用户兴趣的重要性是不一样的
用户兴趣向量的维度可能不一样
为了解决这些问题,模型的结构如下:
3.1 跨域长期兴趣建模
这里主要是通过用户的基本属性信息来表示⽤户内在的⻓期兴趣,⽐如20岁左右的男性⽤户可能对体育赛事或者游戏类的资讯或者⼴告⽐较感兴趣。这⾥主要做法是将⽤户ID、⽤户性别、⽤户所在地域、⽤户的⼿机设备等embedding向量进⾏拼接,输出为pu。例如⽤户ID为123,城市为北京,男性⽤户,使⽤苹果⼿机,得到的⻓期兴趣表示为:
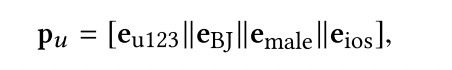
3.2 源域短期兴趣建模
给定一个用户,在每个待预估广告展示之前,用户通常都会与源域的新闻有交互记录。用户交互过得新闻的内容与待预估广告之间有关联关系,则建模用户在源域中的兴趣是很有意义的。在对序列数据进行建模时,文中的item- level attention的方法如下:

其中,rsi是⽤户点击的第i个新闻的embedding,qt代表⽬标⼴告,pu代表⽤户的⻓期兴趣向量,M代表transfer矩阵,将source domain的向量空间映射到target domain的向量空间。Mrsi = rsi*M
3.3 目标域短期兴趣建模
这⾥主要是对⽤户浏览过的⼴告结果进⾏建模,抽取⽤户在target domain中的兴趣,建模⽅式同在源域相同,只不过不需要对向量进⾏映射:

到目前为止,都是一些基本的处理序列数据的操作,只不过有些细节需要注意,比如transfer矩阵,目的在于讲源域的信息迁移到目标域,而且在实现时还需要注意简化复杂度的问题,这些都在原文中有介绍。
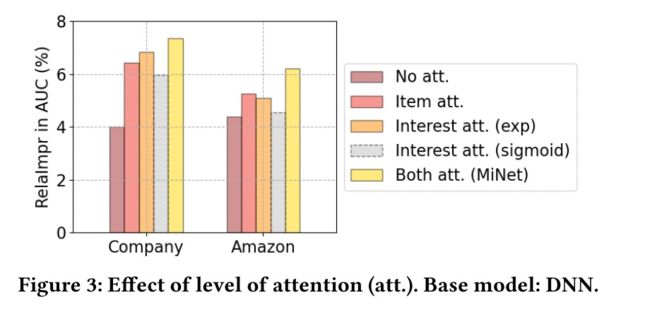
3.4 Interest-Level Attention
刚刚提到了,在处理用户的历史行为序列时,用到的是叫item-level attention,主要用来解决之前提到的五个问题中的1和2,transfer矩阵用来解决的是问题3。
而interest-level attention要解决的就是问题4:对于每个目标广告,三种用户兴趣的重要性是不一样的。如果⽬标⼴告和⽤户最近点击的⼴告相似,那么⽤户在⽬标域的短期兴趣则会起到更重要的作⽤,如果⽬标⼴告和⽤户点击过的⾃然结果和⼴告都不相似,则⻓期兴趣则会起到更重要的作⽤。
每个兴趣的权重计算公式为:
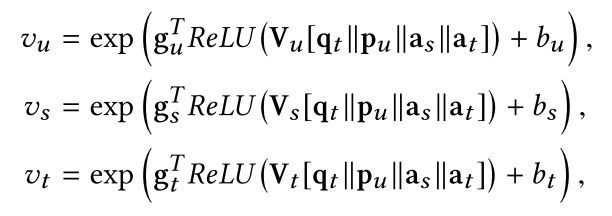
最后将三个带权重向量和待预估广告拼接起来,输入到一个全连接,得到最后的点击率预估值:

3.5 辅助任务
模型还进⼀步加⼊了辅助任务,来辅助⽤户⻓期兴趣的学习,辅助任务也是点击率预估任务,主要通过⽤户的⻓期兴趣来预测⽤户对源域中⾃然结果的点击概率,该部分示意图如下:

模型的两个任务均使用交叉熵损失函数,通过加权的方式得到最终的损失:
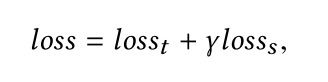
4. 实验细节
4.1 数据预处理
论文用了俩数据集。一个是uc头条的数据集,数据来自新闻和广告曝光和点击日志的随机采样。用2019年中的连续6天作为训练集,第七天作为验证集,第八天作为测试集。在验证集上找到最优超参数后,会把训练集和验证集合并成最终的训练集,然后使用最优超参数进行训练。
第二个数据集是亚马逊的评分数据集,用了book数据集做源域,movie做目标域。在数据预处理时,只保留评分记录大于5次的用户,将4-5分认为是正样本,其余分数认为是负样本。为了不造成特征穿越,会按时间戳对样本进行排序,将每个用户的最后一次评分记录放入测试集中,倒数第二次评分记录放入验证集中,其余的作为训练集。
4.2 实验结果
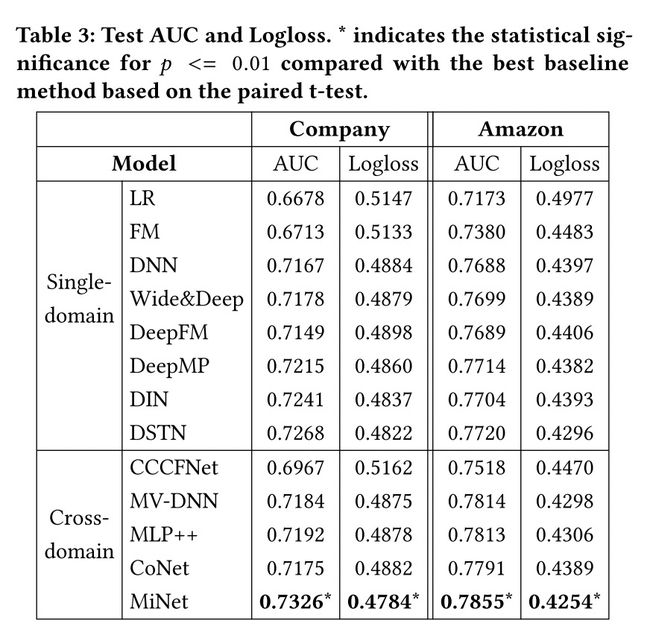

5. 总结
本⽂提出了Mixed Interest Network (MiNet)来进⾏跨域的点击率预估,并取得了不错的实验效果。跨域预估的主要优势是能够对冷启动问题起到⼀定的帮助,如果⽤户在⽬标域中的⾏为⽐较少的话,可以通过在源域中的⾏为来进⾏辅助的预估,提升冷启动的效果。
作者建模了三种不同的用户兴趣,使用了两层注意力,还用了辅助任务来帮助学习。
参考文献
MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction(https://arxiv.org/abs/2008.02974)
跨域推荐技术在58部落内容社区的实践((https://baijiahao.baidu.com/s?id=1672246490825129479&wfr=spider&for=pc))

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/662nyZF本站qq群1003271085。加入微信群请扫码进群(如果是博士或者准备读博士请说明):