pandas索引操作、赋值操作、排序以及Series排序和DataFrame排序
一、pandas索引操作
索引操作,使用索引选取序列和切片选择数据,也可以直接使用列名、行名称,或组合使用
- 直接使用行列索引:行列索引名顺序为先列再行,使用指定行列索引名,不能使用下标
- loc[行索引名,列索引名]:先行再列,只能使用指定的行列索引名,不能使用下标
- iloc[行,列]:先行再列,只能使用索引下标获取数据,不能使用指定行列索引名
- 下标索引与指定行列索引相结合:使用index或columns.get_indexer,见案例
代码如下
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
num
# 传入标签索引
column = ['第一列', '第二列', '第三列', '第四列', '第五列'] # 列标签索引
# ind = ['第一行', '第二行', '第三行'] # 行标签索引
ind = ['第_' + str(i) + '_行' for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
data = pd.DataFrame(num, columns=column, index=ind)
data
-------------------------------------------------------------------
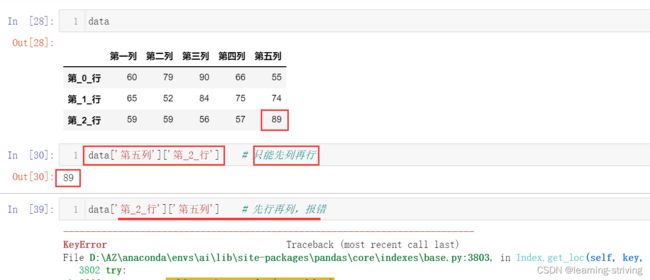
data['第五列']['第_2_行'] # 只能先列再行
data['第_2_行']['第五列'] # 先行再列,报错
data.loc['第_0_行':'第_2_行', '第三列'] # 先行再列,loc只能使用指定行列索引,切取第三列中[0,2]行中的数据
data.loc[:'第_2_行', '第三列':] # loc只能使用指定行列索引,切取[0,2]行,3-最后一列的数据
data.iloc[:2, 2:] # iloc只能使用下标索引,切取[0,2)行,3-最后一列的数据数据生成
 操作如下
操作如下

下标索引与指定行列索引相结合
data.loc[data.index[0:2], ['第二列', '第三列', '第五列']] # 下标索引与指定行列索引相结合
data.iloc[0:2, data.columns.get_indexer(['第二列', '第三列', '第五列'])] # 下标索引与指定行列索引相结合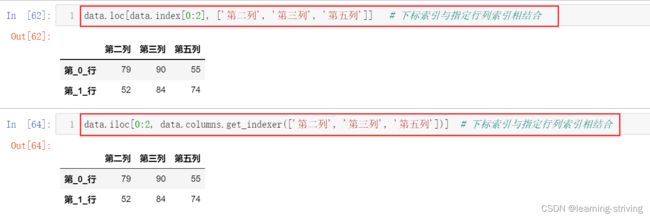
二、pandas赋值操作
只能对某一列赋值,不能对一行赋值,有两种方式,直接使用索引或用点.索引名,具体如下
代码如下
import pandas as pd
import numpy as np
# 数据生成代码
num = np.random.randint(50, 100, (3, 5))
# 传入标签索引
column = ['第一列', '第二列', '第三列', '第四列', '第五列'] # 列标签索引
# ind = ['第一行', '第二行', '第三行'] # 行标签索引
ind = ['第_' + str(i) + '_行' for i in range(num.shape[0])] # 行标签索引,num.shape[0]即获取num数组的行号,此处为3
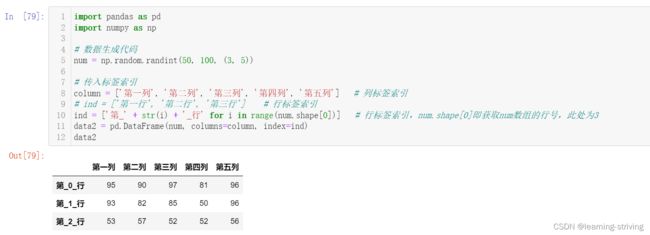
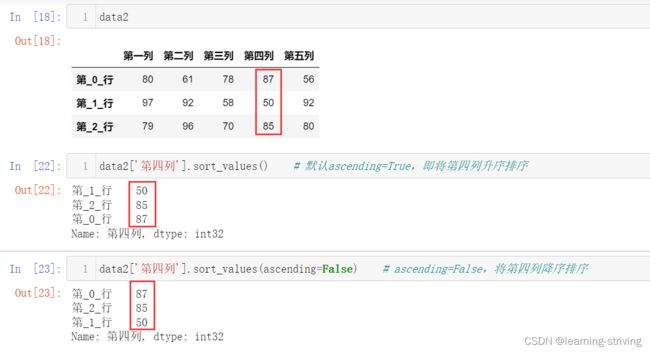
data2 = pd.DataFrame(num, columns=column, index=ind)
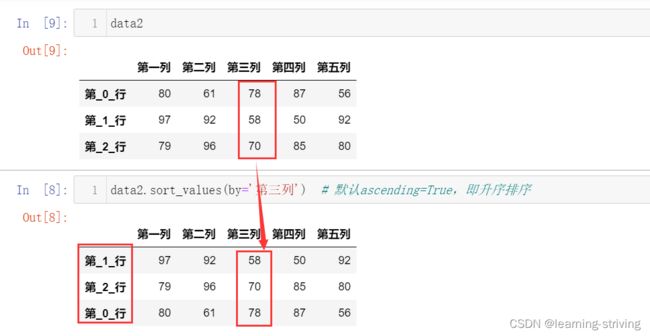
data2
------------------------------------------------------------
data2['第四列'] = 88 # 值可为字符串或汉字
data2
data2.第一列 = 99 # 方式二
data2生成数据
 操作如下
操作如下

三、pandas排序
pandas排序有两种方式,一种是对索引进行排序,另一种是对内容进行排序
3.1 DataFrame排序
- df.sort_values(by=, ascending=):单个键(列名)或多个键进行排序
- by:指定排序参考的键
- ascending:指定升序或降序
- ascending=True:默认升序
- ascending=False:降序
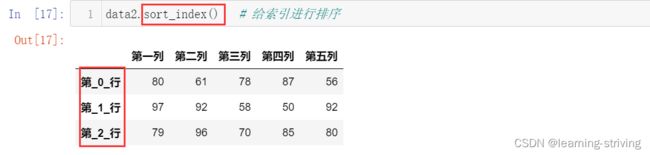
- df.sort_index():给索引进行排序
代码如下
data2.sort_values(by='第三列') # 默认ascending=True,即升序排序
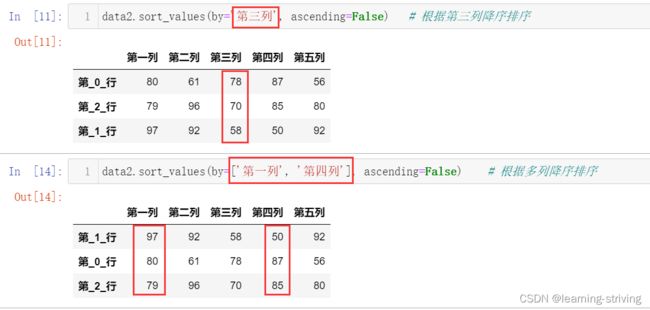
data2.sort_values(by='第三列', ascending=False) # 根据第三列降序排序
data2.sort_values(by=['第一列', '第四列'], ascending=False) # 根据多列降序排序
data2.sort_index() # 给索引进行排序操作演示
3.2 Series排序
- series.sort_values(ascending=True):series排序时,只有一列,不需要参数
- series.sort_index(ascending=):根据索引排序,ascending指定升序或降序,默认升序
代码如下
data2['第四列'].sort_values() # 默认ascending=True,即将第四列升序排序
data2['第四列'].sort_values(ascending=False) # ascending=False,将第四列降序排序
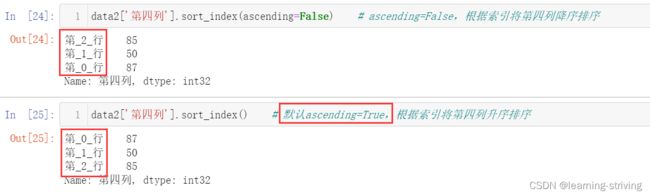
data2['第四列'].sort_index(ascending=False) # ascending=False,根据索引将第四列降序排序
data2['第四列'].sort_index() # 默认ascending=True,根据索引将第四列升序排序操作演示
学习导航:http://xqnav.top/