Facebook_scraper:Python获取FB用户的公开发帖【FaceBook系列 一】
说到Facebook,就不得不先提一嘴扎克伯格。
扎克伯格最让人熟悉的梗和外号就是【蜥蜴人,机器人】:

我一看你就不是人,大威天龙!
但是小扎成立的Facebook俨然成为了规模不小的照片分享网站和知名广告商之一。
当然,如此体量网站必然会产生不少的数据,Facebook也曾被窃取过不少的用户信息。虽说如此,但是这次我们获取的数据是公开的哦。
一、Facebook_scraper及其简单的使用方式
Facebook_scraper是脸书的一个专门的爬取库,可以不通过FB的api获取公开的内容。

详情链接:facebook-scraper · PyPI
看一下人家给的使用方法:
>>> from facebook_scraper import get_posts
>>> for post in get_posts('nintendo', pages=1):
... print(post['text'][:50])
...
The final step on the road to the Super Smash Bros
We’re headed to PAX East 3/28-3/31 with new games他这里获取的是Facebook中任天堂发布的公开帖子。
其中Facebook_scraper的get_posts方法,传入了一个'nintendo'的参数,在get_post方法中,就把'nintendo'凑成了链接:https://www.facebook.com/Nintendo/,get_posts就请求的这个链接获取的数据。
人家例子返回的内容还是任天堂明星大乱斗,现在都是星之卡比了
第二个page参数则是设置了最大的返回数据条数,看看源码:
# TODO: Deprecate `pages` in favor of `page_limit` since it is less confusing
if 'pages' in kwargs:
kwargs['page_limit'] = kwargs.pop('pages')
在执行的时候,page数过少的话会不返回数据的哦。(打码的是打印出来的cookie,详见下文)
返回的数据格式:
{'available': True,
'comments': 459,
'comments_full': None,
'factcheck': None,
'fetched_time': datetime.datetime(2021, 4, 20, 13, 39, 53, 651417),
'image': 'https://scontent.fhlz2-1.fna.fbcdn.net/v/t1.6435-9/fr/cp0/e15/q65/58745049_2257182057699568_1761478225390731264_n.jpg?_nc_cat=111&ccb=1-3&_nc_sid=8024bb&_nc_ohc=ygH2fPmfQpAAX92ABYY&_nc_ht=scontent.fhlz2-1.fna&tp=14&oh=7a8a7b4904deb55ec696ae255fff97dd&oe=60A36717',
'images': ['https://scontent.fhlz2-1.fna.fbcdn.net/v/t1.6435-9/fr/cp0/e15/q65/58745049_2257182057699568_1761478225390731264_n.jpg?_nc_cat=111&ccb=1-3&_nc_sid=8024bb&_nc_ohc=ygH2fPmfQpAAX92ABYY&_nc_ht=scontent.fhlz2-1.fna&tp=14&oh=7a8a7b4904deb55ec696ae255fff97dd&oe=60A36717'],
'is_live': False,
'likes': 3509,
'link': 'https://www.nintendo.com/amiibo/line-up/',
'post_id': '2257188721032235',
'post_text': 'Don’t let this diminutive version of the Hero of Time fool you, '
'Young Link is just as heroic as his fully grown version! Young '
'Link joins the Super Smash Bros. series of amiibo figures!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'post_url': 'https://facebook.com/story.php?story_fbid=2257188721032235&id=119240841493711',
'reactions': {'haha': 22, 'like': 2657, 'love': 706, 'sorry': 1, 'wow': 123}, # if `extra_info` was set
'reactors': None,
'shared_post_id': None,
'shared_post_url': None,
'shared_text': '',
'shared_time': None,
'shared_user_id': None,
'shared_username': None,
'shares': 441,
'text': 'Don’t let this diminutive version of the Hero of Time fool you, '
'Young Link is just as heroic as his fully grown version! Young Link '
'joins the Super Smash Bros. series of amiibo figures!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'time': datetime.datetime(2019, 4, 30, 5, 0, 1),
'user_id': '119240841493711',
'username': 'Nintendo',
'video': None,
'video_id': None,
'video_thumbnail': None,
'w3_fb_url': 'https://www.facebook.com/Nintendo/posts/2257188721032235'}案例中打印的是返回数据中"text"字段中前50个字符。
当然,这个库不仅仅就这一个方法。浏览了下源码,发现了里面有封装好多的对应的方法,比如爬取群众group,图片数据等等,后续的话会持续更新的,敬请期待。
二、设置Cookie
因为Facebook有着比较严格的登录规定,所以的话你得需要获取到登陆的cookie再能更方便的获取数据。(亲测这个好像不需要cookie也能获取)
但是话都说到这个份上了我还是要把cookie这个东西讲一讲!

关于cookie的问题,文档中也有所提及,我这就按官方和我自己的步骤综合的讲一下:
2.1、获取cookie
文档第一条说获取cookie的方式是使用浏览器的插件,chrome用Get cookies.txt插件,火狐用Cookie Quick Manager。因为我是chrome,就着重说一下Get cookies.txt:

安装好插件之后,你的浏览器的右上角会有这个东西:

没有的自己调啊,浏览器自己设置嗷
这是你再去访问你的Facebook,插件图标的下标会显示数字,这就说明插件已经获取到你的访问Facebook的cookie了。
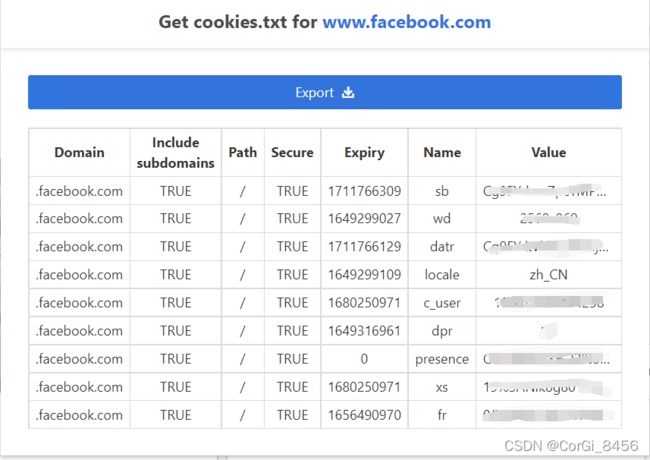
点开插件之后,点击Export导出,会下载一个txt文件,这就是你的cookie导入本地的文件了。
2.2、读取cookie文件并使用
获取到cookie之后呢,开始在方法里面调用了。
首先将cookie文件通过cookiejar里面的MozillaCookieJar方法将cookie文件转成cookiejar类型,之后使用requests中的dict_from_cookiejar方法将cookiejar转成cookiedict。
import requests
from http import cookiejar
file = "cookies.txt"
cookie = cookiejar.MozillaCookieJar()
cookie.load(file)
cookies = requests.utils.dict_from_cookiejar(cookie)
print(cookies)![]()
到这呢,基本上cookie已经处理完了。在Facebook_scraper里面有个set_cookies()方法,直接将cookiedict传进去就完事儿了(附上源码):
def set_cookies(cookies):
if isinstance(cookies, str):
if cookies == "from_browser":
try:
import browser_cookie3
cookies = browser_cookie3.load(domain_name='.facebook.com')
except:
raise ModuleNotFoundError(
"browser_cookie3 must be installed to use browser cookies"
)
else:
try:
cookies = parse_cookie_file(cookies)
except ValueError as e:
raise exceptions.InvalidCookies(f"Cookies are in an invalid format: {e}")
elif isinstance(cookies, dict):
cookies = cookiejar_from_dict(cookies)
if cookies is not None:
cookie_names = [c.name for c in cookies]
missing_cookies = [c for c in ['c_user', 'xs'] if c not in cookie_names]
if missing_cookies:
raise exceptions.InvalidCookies(f"Missing cookies with name(s): {missing_cookies}")
_scraper.session.cookies.update(cookies)
if not _scraper.is_logged_in():
raise exceptions.InvalidCookies(f"Cookies are not valid")附上整体的cookie整合代码:
import requests
from http import cookiejar
import facebook_scraper as fb
file = "cookies.txt"
cookie = cookiejar.MozillaCookieJar()
cookie.load(file)
cookies = requests.utils.dict_from_cookiejar(cookie)
print(cookies)
fb.set_cookies(cookies)三、代理设置
当然,在国内是没法正常访问的。
所以能获取数据的方法有两个:1,用海外的服务器部署服务,但是不保证你的IP连带着你的账户被ban掉的风险。2,使用代理。
总之使用代理是比较安稳的方式。
我这边使用的ipidea的代理,在写这篇文章之间就试过了,很稳定(要不然这文章就没法往下写了)。新用户可以白嫖流量哦,往期的文章有很详细的使用教程!
地址:http://www.ipidea.net/?utm-source=csdn&utm-keyword=?wb
Facebook_scraper里面有个方法,叫set_proxy()
def set_proxy(self, proxy):
self.requests_kwargs.update({'proxies': {'http': proxy, 'https': proxy}})
ip = self.get(
"http://lumtest.com/myip.json", headers={"Accept": "application/json"}
).json()
logger.debug(f"Proxy details: {ip}")可以发现,里面的代理格式已经写好了,仅仅需要把代理设置成“http://域名:端口”这个样式传进去就可以了。带账号密码的代理也是可以这么传进去的。
传入代理之后,会发现里面走了一个get请求,获取你代理所在的IP地址便于之后的请求
附上整合的代码:
import requests
from http import cookiejar
import facebook_scraper as fb
file = "cookies.txt"
cookie = cookiejar.MozillaCookieJar()
cookie.load(file)
cookies = requests.utils.dict_from_cookiejar(cookie)
print(cookies)
proxy = getApiIp()#获取代理的方法
fb.set_proxy(proxy)
fb.set_cookies(cookies)四、总结
经过上述步骤之后,代理和cookie设置完毕后,就可以正常的去请求。附上总的整合代码:
import requests
from http import cookiejar
import facebook_scraper as fb
# api获取ip
def getApiIp():
# 获取且仅获取一个ip
api_url = '获取代理的地址'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = f'http://{api_data["ip"]}:{api_data["port"]}'
print(proxies)
return proxies
else:
print('获取失败')
except:
print('获取失败')
def get_start():
file = "cookies.txt"
cookie = cookiejar.MozillaCookieJar()
cookie.load(file)
cookies = requests.utils.dict_from_cookiejar(cookie)
print(cookies)
proxy = getApiIp()
fb.set_proxy(proxy)
fb.set_cookies(cookies)
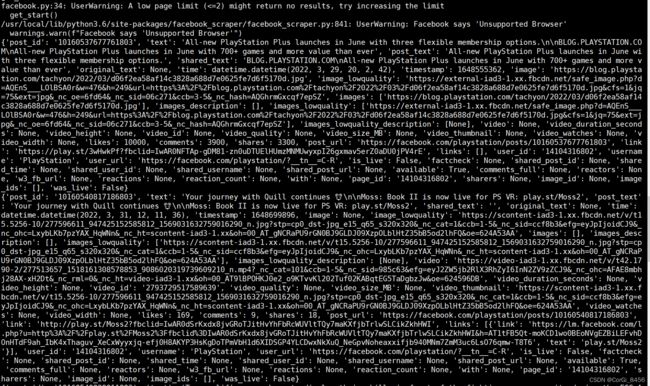
for post in fb.get_posts('nintendo', pages=1,):
print(post['text'])
#
if __name__ == '__main__':
get_start()
本期分享了Facebook_scraper这个下载库,因为这个库的教程真的是很少,于是写下来分享一下。
最后说一句,Facebook内容虽然精彩,但是必须要擦亮眼睛,明辨是非。身处在信息茧房,也不能迷失自我。