【机器学习】判别模型vs生成模型、概率模型vs非概率模型
参考:生成模型 VS 判别模型 (含义、区别、对应经典算法)
机器学习“判定模型”和“生成模型”有什么区别?
判别模型与生成模型,概率模型与非概率模型、参数模型与非参数模型总结
将判别模型vs生成模型、概率模型vs非概率模型放在一起讲解,是因为两者具有一定的联系,放在一起更有助于理解。
注意一下所有内容都是基于监督学习的!!!!
监督学习的任务就是学习一个模型,对于给定的输入预测相应的输出,这个模型的一般形式为决策函数:
![]()
或者条件概率分布:
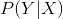
这里称为条件概率,是指在给定样本特征X得条件下,去求样本得类别Y。更准确的说是后验概率,具体将在后面阐述。
判别模型vs生成模型
-
生成模型
学习到联合概率分布P(X,Y),即特征x和标记y共同出现的概率,然后求条件概率分布P(Y|X),之后P(Y|X)最大的类别就是最终预测的类别。生成模型能够学习到数据生成的机制。公式如下:

![]()
生成式模型对于一个样本的特征X,要求出X与不同标记Y之间的联合概率分布P(Y,X),然后大的获胜,如下图右边所示,没有什么边界存在。对于未见示例(红三角),求两个联合概率分布(有两个类),比较一下,取那个大的作为最终类别。
机器学习中朴素贝叶斯模型、隐马尔可夫模型HMM、混合高斯模型等都是生成式模型,熟悉Naive Bayes的都知道,对于输入X,需要求出好几个联合概率,然后较大的那个就是预测结果~(根本原因个人认为是对于某示例X_1,对正例和反例的标记的联合概率不等于1,即P(Y_1,X_1)+P(Y_2,X_1)<1,要遍历所有的X和Y的联合概率求和,即sum(P(X,Y))=1,
-
判别模型
直接学习到决策函数f(x),即对输入空间到输出空间的映射进行建模;或者直接对分布P(Y|X)建模,即在特征X出现的情况下标记Y出现的概率,是后验概率。公式为:
决策函数: ![]()
后验概率:
这里需要特别阐述一下
后验概率的定义是执果索因,就是已知结果去求为什么。而对于上式子,很多人认为这是执因索果:因为我们我们已知样本的特征X,然后根据这些特征来求得样本的类别Y,认为样本的类别是果。
这样理解实际上是搞错了X,Y的因果关系。因为样本是客观存在的,它不会因为我们的观测方式(特征提取的方法)而改变,各类算法提取出的特征只是样本本质Y的体现。
因此实际上,Y是样本的类别,是本质,是因,正因为有了这样的因,我们通过不同的观测(特征提取算法)才会得到不同的特征,即特征X只是样本Y的在不同维度下体现,是果。
判别法关心的是对于给定输入特征X,应该预测什么样的输出Y,即直接判别出来样本的类别,如下图的左边所示,实际是就是直接得到了判别边界。
所以传统的、耳熟能详的机器学习算法如:线性回归模型、逻辑回归、支持向量机、感知机、K近邻、决策树等都是判别式模型,这些模型的特点都是输入属性(特征)X可以直接得到Y(对于二分类任务来说,实际得到一个score,当score大于threshold时则为正类,否则为反类)

从本质上来说,判别模型之所以称为“判别”模型,是因为其根据X“判别”Y;
而生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为“生成”(X,Y)样本的概率分布(或称为 依据);具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),实际数据是如何“生成”的依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧~
-
总结
通过上面的阐述,可以看到无论是判别模型还是生成模型,都是求这个后验概率,但是前者是采用的是极大似然的方法,而后者通过贝叶斯定理将其转化为求联合概率分布P(X,Y)。
判别模型的优点就是生成模型的缺点,反之亦然
| 生成模型 | 判别模型 | |
| 优点 | ① 可以还原出联合概率分布P(X,Y); ② 收敛速度更快,当样本容量增加的时候,学到的模型可以更快地收敛于真实模型; ③可以训练包含隐变量的模型 |
①直接学习决策函数和条件概率来预测类别,准确率更高; ②由于直接学习Y=f(X)或P(Y|X),可对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习过程。 |
| 缺点 | ① 需要更多的样本,计算量较大 ② 更多情况下分类性能不如判别模型 |
①不能还原联合概率分布P(X,Y) ② 收敛速度较慢 ③ 不能训练包含隐变量的模型 |
概率模型vs非概率模型
-
概率模型
先假定模型
![]()
计算P(Y|X)有两种方式:
(1)直接对P(Y|X)建模。逻辑回归就是采用的就是这样的方式;
(2)对联合概率分布P(X,Y)进行建模,公式如下。对比一下就会发现,这种方法与生成模型一样,都是学习联合概率分布P(X,Y)。
由于一般情况下P(X,Y)无法直接获得,会通过贝叶斯公式将其拆解为类先验概率P(Y)和类条件概率P(X|Y)来计算:


-
非概率模型
非概率模型指的是直接学习输入空间到输出空间的映射h,学习的过程中基本不涉及概率密度的估计,概率密度的积分等操作,问题的关键在于最优化问题的求解。通常,为了学习假设h(x),我们会先根据一些先验知识(prior knowledge) 来选择一个特定的假设空间H(函数空间),例如一个由所有线性函数构成的空间,然后在这个空间中找出泛化误差最小的假设出来,
![]()
其中l(h(x),y)是我们选取的损失函数,选择不同的损失函数,得到假设的泛化误差就会不一样。由于我们并不知道P(x,y),所以即使我们选好了损失函数,也无法计算出假设的泛化误差,更别提找到那个给出最小泛化误差的假设。于是,我们转而去找那个使得经验误差最小的假设,
![]()
这种学习的策略叫经验误差最小化(ERM),理论依据是大数定律:当训练样例无穷多的时候,假设的经验误差会依概率收敛到假设的泛化误差。要想成功地学习一个问题,必须在学习的过程中注入先验知识[3]。前面,我们根据先验知识来选择假设空间,其实,在选定了假设空间后,先验知识还可以继续发挥作用,这一点体现在为我们的优化问题(IV)加上正则化项上,例如常用的L1正则化,L2正则化等。
![]()
正则化项一般是对模型的复杂度进行惩罚,例如我们的先验知识告诉我们模型应当是稀疏的,这时我们会选择L1范数。当然,加正则化项的另一种解释是为了防止对有限样例的过拟合,但这种解释本质上还是根据先验知识认为模型本身不会太复杂。在经验误差的基础上加上正则化项,同时最小化这两者,这种学习的策略叫做结构风险最小化(SRM)。最后,学习算法A根据训练数据集D,从假设空间中挑出一个假设g,作为我们将来做预测的时候可以用。具体来说,学习算法A其实是一个映射,对于每一个给定的数据集D,对于选定的学习策略(ERM or SRM),都有确定的假设与D对应
![]()
感知机、支持向量机、神经网络、k近邻都属于非概率模型。线性支持向量机可以显式地写出损失函数——hinge损失。神经网络也可以显式地写出损失函数——平方损失。
时下流行的迁移学习,其中有一种迁移方式是基于样本的迁移。这种方式最后要解决的问题就是求解一个加权的经验误差最小化问题,而权重就是目标域与源域的边际密度之比。所以,线性支持向量机在迁移学习的环境下可以进行直接的推广。
总结
| 判别模型 |
① 学习到决策函数y = f(x) ② 直接对P(Y|X)建模,即计算后验概率。 |
SVM(学习决策函数) 感知机(学习决策函数) 逻辑回归(对P(Y|X)建模) |
| 生成模型 |
对P(X,Y)建模获得X,Y的联合概率分布,之后计算 |
贝叶斯分类器 |
| 非概率模型 |
直接学习输入空间到输出空间的映射,学习的过程中基本不涉及概率密度的估计,概率密度的积分等操作,问题的关键在于最优化问题的求解: ①经验风险最小化 ②结构风险最小化 |
SVM 感知机 神经网络 |
| 概率模型 |
追根究底就是计算P(Y|X),有两种方法: ① 直接对P(Y|X)建模,即计算后验概率;(部分判别模型) ②对P(X,Y)建模之后通过 计算P(Y|X)后, |
逻辑回归(直接对P(Y|X)建模) (朴素)贝叶斯分类器(通过贝叶斯公式计算) |