论文笔记|A Joint Learning Approach based on Self-Distillation for Keyphrase Extraction from Scientific..
导读
《A Joint Learning Approach based on Self-Distillation for Keyphrase Extraction from Scientific Documents》是一篇发表在COLING2020上的论文,作者来自University of Illinois at Urbana-Champaign和Adobe研究团队。本研究主要是受到自蒸馏算法的启发,将自蒸馏算法应用到科技文档的关键词提取任务中。研究的主要贡献在于,将自蒸馏的思想应用到关键词抽取任务中,在多个数据集的实验上达到了SOTA水平。论文链接
一、研究背景
关键词抽取是自动从文本中抽取出一组具有代表性的关键词,形成对文本的一种描述。关键词提取任务能够为NLP中很多的下游任务搭建基础。在近些年的研究中,关键词抽取主要可以分为两种类别:基于监督学习的关键词抽取和基于无监督学习的关键词抽取。在深度学习发展迅速的现在,基于有关键词标注的数据,建立监督学习模型所得到的性能往往比无监督学习模型的性能更好。
目前,深度学习方法在许多的自然语言处理任务中都取得了令人满意的成绩。但在许多关键词抽取的基准数据集中,没有足够数量的对文档的关键词标注,使得深度学习方法在这一具体任务中受到限制。在目前学者发表的论文在是否提供关键词方面主要可以分成两种:一种是在电子图书馆中,出版商要求论文的作者提供一系列的关键词,这些关键词可以作为关键词抽取任务的标注数据;另外一种是例如ACL、EMNLP等会议不要求作者提供关键词,而这一类的论文很难被监督学习的模型使用起来。
作者基于2018年提出的自蒸馏(self-distillation)的概念方法,设计了一种联合学习方法,能够最大限度地使用已经标注的数据和没有关键词标注的数据。作者在多个公开数据集上做了实验,其提出地模型性能均能达到SOTA水平。
二、模型与方法
2.1 问题建模
与一些基于监督学习的关键词抽取任务类似,本文将关键词抽取任务定义为序列标注任务,即对于文档 包含
包含 个单词
个单词![]() ,任务建模为对个单词进行类别预测
,任务建模为对个单词进行类别预测![]() ,其中
,其中![]() 。B代表这个单词是关键词的第一个单词,I代表是关键词的后续单词,O代表这个单词不是关键词的一部分。使用传统无监督学习的方法的关键词抽取很大的任务在于对候选关键词的排序,从而从很多的候选关键词中抽取前k个短语作为抽取的关键词,而基于这种序列标注的方法避免了排序的任务,直接从标注好的文本序列中提取出短语作为模型的输出。
。B代表这个单词是关键词的第一个单词,I代表是关键词的后续单词,O代表这个单词不是关键词的一部分。使用传统无监督学习的方法的关键词抽取很大的任务在于对候选关键词的排序,从而从很多的候选关键词中抽取前k个短语作为抽取的关键词,而基于这种序列标注的方法避免了排序的任务,直接从标注好的文本序列中提取出短语作为模型的输出。
2.2 基线模型
在本文中,对于自蒸馏的方法,需要先有一个基线模型,本文使用的是双向长短时记忆网络+条件随机场(BiLSTM-CRF),作为关键词抽取的模型。在以往的其他研究中,不同作者使用BiLSTM-CRF完成了关键词抽取的任务。本模型中,首先使用例如BERT的基于transformer的encoder获取本文的词向量嵌入表示,并将向量输入BiLSTM中,后通过CRF将模型的中间权重映射到三个目标输出标记上,从而完成序列标注任务。
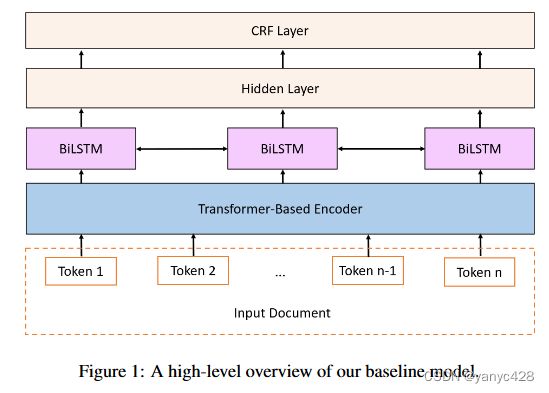
2.3 基于自蒸馏的联合学习方法
自蒸馏的主要思想如下:将总的分为老师模型和学生模型,使用标记数据对老师模型进行训练,并对未标记的数据进行预测,将标记数据和从老师模型中得到预测标记的未标记数据汇总,作为学生模型的训练数据,如果学生模型的性能表现比老师模型更好,则将老师模型的参数设置为学生模型的参数,重新对未标记数据进行预测、并重新训练学生模型,如此迭代,最终得到最优的模型。
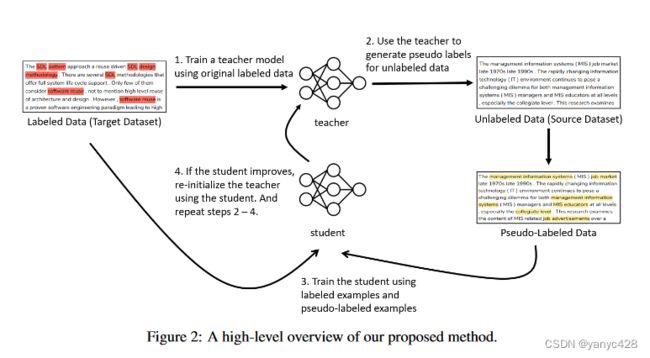
下面详细介绍模型的实现细节,对于标记数据集![]() 和未标记的数据集
和未标记的数据集![]() :
:
- 使用有标记的数据集对老师模型进行训练;
- 使用老师模型的参数来初始化学生模型;
- 从有标记的数据集中随机挑选一批次数据记作
 ;
; - 从无标记的数据集中随机挑选数量为
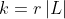 的一批数据记为
的一批数据记为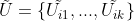 ,其中
,其中 为超参数,控制每一次循环中有多少无标记数据被使用到学生模型的训练中;
为超参数,控制每一次循环中有多少无标记数据被使用到学生模型的训练中; - 使用老师模型对无标记的数据
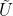 进行预测,得到有标记的数据
进行预测,得到有标记的数据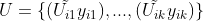 ;
; - 使用数据
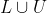 来更新学生模型的参数;
来更新学生模型的参数; - 如果学生模型的性能表现超过老师模型,将老师模型的参数初始化为当前学生模型的参数;
- 将步骤3-8循环
 次,其中为人为设置的循环次数。
次,其中为人为设置的循环次数。

三、实验
3.1 数据集、预训练模型、超参数
在实验环节中,作者使用了KP20K作为训练数据,Inspec和SemEval-2017作为模型的测试数据,其中KP20K含有50万数量的论文,Inspec包含1000条训练数据、500条验证数据、500条测试数据,SemEval-2017包含350篇训练数据、50篇验证数据和100篇测试数据。
对于预训练模型,作者使用了两种不同的基于Transformer的预训练模型,分别为BERT(base-cased)和SciBERT(scivocab-cased)。
对于超参数,批处理规模(batch_size)作者尝试了4、8和16,最低学习率作者尝试了2e-5,3e-5,4e-5,5e-5和最高学习率1e-4, 2e-4, 5e-4, 1e-3, 5e-3,对于迭代次数,作者尝试了25, 50, 75, 100, 125,而对于每次选取的无标记数据规,作者尝试了0.25, 0.5, 1, 1.5, 2, 4。
3.2 对比实验
(1) 与以往的监督学习方法比较,本文所提出的方法在使用SciBERT时结合自蒸馏方法在多个数据集上达到了SOTA。
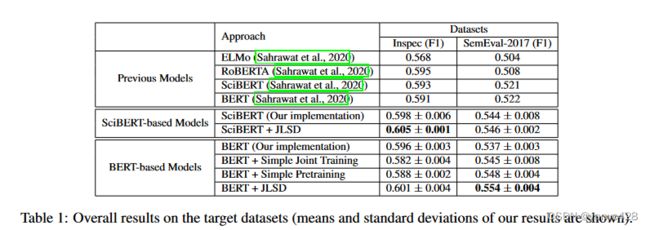
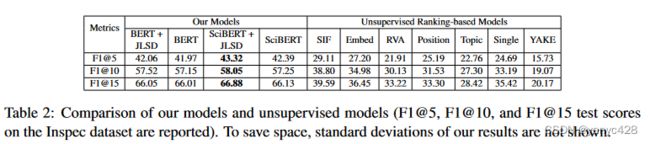
(2)与以往的无监督学习比较,本文所提出的方法在F1@5、F1@10,F1@15等指标上大大超过了无监督学习的关键词抽取方法。
四、总结和想法
本文基于自蒸馏的思想提出了一种全新的联合学习的关键词抽取方法,在多个数据集上达到了SOTA的性能,自蒸馏是一种很好的将标记数据和无标记数据同时使用到模型训练过程的方法。我认为日后可以将自蒸馏的思想应用到更多的此类数据情况的任务中。