论文笔记|Deep Keyphrase Generation
导读
这是一篇发表在ACL2017的论文,作者来自匹兹堡大学何大庆老师组。这篇论文可以说是生成式方法完成关键词预测的开山/典范之作。以往的论文多是在文本中抽取短语作为文档的关键词,本篇论文是使用生成式的方法,去预测一些可能没有存在与文本中的关键词。论文链接
一、论文背景
关键词是一段能够描述文本主要语义信息的文本片段。关键词比较常见的地方就是论文中,作者或者出版方会提供一些能够概括论文核心信息的短文本。高质量的关键词有助于理解、组织和访问文档的内容。因此,有很多学者在研究关键词的自动抽取,并在许多可访问的科技论文数据集上应用提出的抽取模型。
以往的关键词预测任务多是基于抽取式的,即通过抽取文本中的短语作为文本的关键词。关键词抽取的任务可以运用于很多NLP的下游任务,例如文本摘要、文本聚类等任务。目前的关键词抽取任务一般都是分为两个步骤,首先是通过n-grams或者POS标注等方式提取候选的关键词集合,其次设计一个排序算法对候选的关键词进行排序,最终提取出前k个关键词作为抽取的结果。
作者认为,这种抽取式的关键词预测有两个缺点:(1)这种方法只能抽取出现在文本中的短语作为关键词,而不能预测出那些没有出现在文本中的短语,而这些没出现的短语有可能是文中某些短语的同义词或者调整了字的顺序;(2)在做候选关键词排序的时候,一般是基于一些统计特征在做,例如词语的共现关系等,而没有考虑到全文的语义信息(2017年的时候BERT还没有面世,那个时候还没有大规模的预训练模型用于提取语义特征)。
因此,为了解决上述的问题,作者重新审视了人类对文档做关键词预测的流程。对于一个给定的文档,人类首先会通读全文从而对文档内容有一个基本的认识,然后基于文档的内容理解去生成关键词,但有时候他们生成的关键词可能在原文中并没有出现。例如,人类在文档中看到了使用LDA的方法,可能会写下“主题模型”或“主题挖掘”作为文档可能的关键词。另外,人类还有可能会判断哪些句子是重要的,从而从这些重要的部分中提取关键词。因此,一个好的关键词预测模型需要满足两点特征:(1)其需要理解文档内容的语义信息(语义特征);(2)其需要捕捉上下文的特征(句法特征)。
为了能够更好地捕捉语义和句法上的特征,在语义特征上,作者使用了循环神经网络(RNN)将文本映射到语义空间中;在句法特征上,作者提出了拷贝机制来识别文档中重要的部分。因此,作者提出的模型可以根据文本中的重要信息提出在文档中和不在文档中的短语,作为文档的关键词。
本文的贡献主要有三点:(1)作者提出了一种基于RNN的生成式模型,作者在RNN模型中添加了一个拷贝机制,帮助模型识别出那些不常出现的关键词;(2)这是首个研究没有出现在文档中关键词的预测的任务;(3)本文提出的模型与多个监督和无监督模型对比,取得了SOTA的水平。
二、模型与方法
2.1 问题定义
本文要解决的问题定义如下:对于包含 个数据样本的数据集,第
个数据样本的数据集,第 个数据样本可表示为
个数据样本可表示为![]() ,其中
,其中![]() 表示文档的文本,而
表示文档的文本,而![]() 表示
表示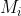 个关键词,即
个关键词,即![]() ,文本和关键词都由token序列组成,即:
,文本和关键词都由token序列组成,即:
![]()
![]()
其中![]() 和
和![]() 表示
表示![]() 和
和![]() 的序列长度。
的序列长度。
由于在数据集中,一篇文档对应着多个关键词,因此,作者在问题中将数据拆分成多个pairs,即把![]() 分割为
分割为![]() ,而后使用Encoder-Decoder模型将原始的文本序列映射到最终的关键词对应的文本序列。
,而后使用Encoder-Decoder模型将原始的文本序列映射到最终的关键词对应的文本序列。
2.2 Encoder-Decoder模型
本文所提出的关键词生成模型的基本思想是使用encoder将文本映射到语义空间中,获取模型的深度表示,再基于以上的表示使用decoder来生成相关的关键词。模型中使用的encoder和decoder都是基于RNN实现的。
在本文的模型中,Encoder的作用是将文本的序列![]() 映射到隐藏的向量表示
映射到隐藏的向量表示![]() ,
, 的计算方式是基于循环神经网络的:
的计算方式是基于循环神经网络的:
![]()
这里的 是一个非线性的函数。另外作者提出了一个上下文向量
是一个非线性的函数。另外作者提出了一个上下文向量 来作为整个文章的表示,这个向量是由所有token的向量表示来计算的。
来作为整个文章的表示,这个向量是由所有token的向量表示来计算的。
![]()
其中 也是一个非线性的函数。
也是一个非线性的函数。
本文模型的Decoder是另一个RNN的模型,其对上下文向量进行处理,并使用一个基于条件概率的语言模型逐词生成特定长度的序列![]() :
:
![]()
![]()
其中, 是Decoder中RNN的隐藏状态。非线性函数
是Decoder中RNN的隐藏状态。非线性函数 是一个softmax函数,用来输出词汇表中所有词语的概率。其中
是一个softmax函数,用来输出词汇表中所有词语的概率。其中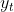 是时间
是时间 通过softmax函数后最大概率值所对应的词。
通过softmax函数后最大概率值所对应的词。
Encoder和Decoder的网络是共同训练的,用来最大化某源序列对应的目标序列的条件概率。再训练时候,使用束搜索(beam search)来生成短语,此外,作者使用了最大堆来预测具有最大概率的单词序列。
2.3 Encoder和Decoder的细节
在Encoder部分,作者使用了GRU来替换基本的RNN,从而完成更好的语言建模。同样的,在非线性的函数部分,也使用了GRU的函数。
在Decoder部分,作者同样使用了另一个GRU,但有所不同的是,Decoder部分添加了注意力机制,来改善模型的性能,其中,上下文向量是隐藏状态的加权和。
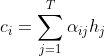
![]()
其中,![]() 是一个用来衡量
是一个用来衡量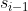 和
和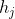 的相似度的函数,用来衡量输入的j位置和输出的i位置的匹配程度。
的相似度的函数,用来衡量输入的j位置和输出的i位置的匹配程度。
2.4 拷贝机制
为了保证学习到的表示的质量,并降低词汇表比较的次数,RNN模型只考虑了一部分常用的词语,而忽略那些长尾分布中那些出现的比较少的词语。因此,RNN不能预测出那些词汇表之外的关键词。事实上,在不知道重要短语的确切含义的时候,也可以通过上下文中的位置和句法信息来识别。拷贝机制是一种能够从源文本中预测词汇表外的关键词的可行的办法。
通过结合拷贝机制,对于词语的概率预测可以分为两个部分:(1)生成词语的概率;(2)从原文本中拷贝的概率:
![]()
与注意力机制类似,拷贝机制通过位置上注意力的衡量来判断源文本中每个词语的重要性。但与生成模型的RNN不同的是,生成式的RNN从词汇表中预测关键词,而拷贝机制考虑源文本中词语。因此,一方面具有拷贝机制的RNN能够预测那些不在词汇表但源文本中出现的词语;另一方面,该模型偏好那些出现在源文本中的词语,这迎合了大多数关键词出现在源文本中的事实。
![]()
![]()
其中, 是源文本
是源文本 中的词语集合,
中的词语集合, 是一个非线性的函数,
是一个非线性的函数,![]() 是可学习的参数矩阵,
是可学习的参数矩阵, 是所有score的和,用于数据标准化。
是所有score的和,用于数据标准化。
三、实验
3.1 训练数据集
本文从在线的网站中,收取了一些包含作者关键词的文章。作者收集了大量的高质量的科技论文源数据,本文收集的是计算机科学领域的论文,来源涵盖多个在线电子图书馆,包括ACM Digital Library、ScienceDirect、Wiley和Web of Science等。总体上,在去重、去掉测试数据集中论文的数据后,作者一共收集了567830篇论文。其中,作者随机地挑选出了40000篇论文,其中20000作为验证集,另外20000作为测试集,而这个20000的测试集,就是大名鼎鼎的KP20K。
3.2 测试数据集
为了表现本文所提出的模型的效果,除了提出的KP20K作为测试集以为,本文还使用了Inspec、Krapivin、NUS、SemEval-2010作为测试数据集,本文将标题和摘要作为论文的源文本。
3.3 实现的细节
总体上,训练数据包含2780316个 ,梯度裁剪的参数为0.1,dropout参数设置为0.5。束搜索的最大深度设置为6,束的数量设置为200。本文使用的loss是交叉熵损失,并使用验证数据集实施early-stopping。
,梯度裁剪的参数为0.1,dropout参数设置为0.5。束搜索的最大深度设置为6,束的数量设置为200。本文使用的loss是交叉熵损失,并使用验证数据集实施early-stopping。
在关键词生成的时候,作者发现模型多会生成很多较短的词语,而在现实生活中,关键词通常会比较长,因此,作者只保留最大概率一个单词的关键词,而剩余的单字关键词被忽略。
3.4 基线模型
本文使用了4个无监督的方法(TF-IDF、TextRank、SingleRank和ExpandRank)和2个监督的方法(KEA、Maui)作为对比实验。
3.5 评价指标
本文使用了3个评价指标,macro-averaged 的precision、recall和F1值。
3.6 测试结果
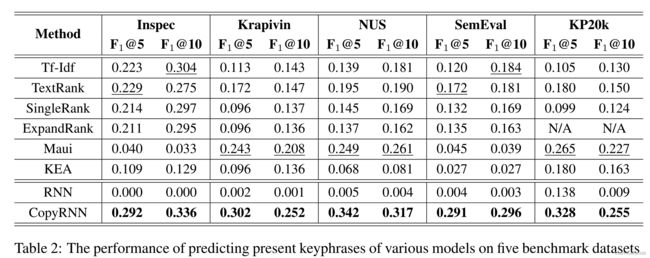
(1)出现在文章中的关键词的对比实验:
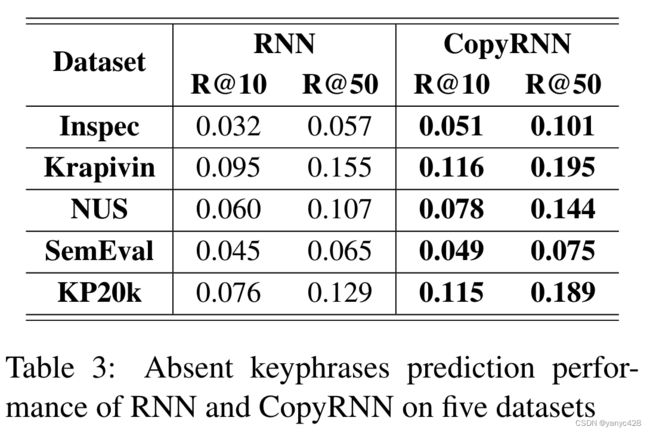
(2)未出现在文章中的关键词的实验:
(3)例子
四、总结
本文首创性地提出了未出现在文档中的关键词的生成工作,并在多个公开数据集上取得了较好的性能改进,但本文的工作还可以在多个方面加以改进,由于本文发表时间较早,如今的学者在这方面也有了不错的改进,起到了一定的性能提升。