我们该如何设计数据库(三)
首先是一些废话:
前文链接:
在《我们该如何设计数据库(二)》中,园友Jacklondon Chen提出了一些问题,大致如下:
“man/woman应该设计在同一张表中。 用户表大多都设计成一个表。连分 administrator 和 user 都不应该。”
我想还是因为我举例太随意,因为博文中Man和Woman只有4个差异属性:HasCar\HasHouse\HasMoney,以及IsBeauty
其实对于这个问题我无力吐槽什么,简单的说说吧:假设为Man用户实现的是一个征婚系统,而Woman用户实现的是一个选美系统。这么说应该能理解Man和Woman的不能并同一张表的原因了吧
废话说完,正文开始
/*=============================================================*/
现在有一个系统,我们暂时假设为学校选课系统。有两类用户Teacher和Student,还有一张Curriculum表是课程总表,来储存学校一共有哪些课程,每门课的学分什么的。然后一个老师,一门课程和多名学生,就可以开始上课了
表结构如下图:
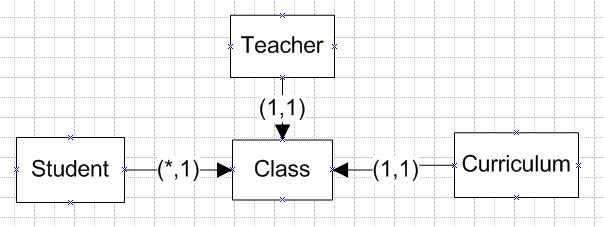
逻辑很简单,一目了然
但是问题在于,我们的系统要按学校来卖。每个学校的选课逻辑都是一样的,而表中的数据有共性,但是也有差异性。比如说基本的Teacher表结构是这样的:

现在把系统卖给A学校。A学校除了的Teacher表除了用户名和密码之外,还要储存老师的FirstName和LastName,那么表结构变化如下:
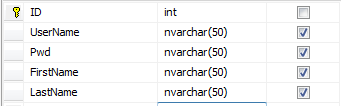
现在B学校也买了我们的系统。他们的Teacher表不要FirstName和LastName,但是要储存教师的工号“Number”,表结构如下:

好,现在我们的问题出来了:怎么去解决这种差异性
最简单的思路莫过于表中加冗余字段。比如说将表设计成这样:
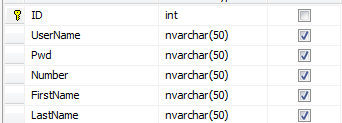
如果我们的系统只卖两三个学校,这样是可行的。但是打个比方,我们的系统卖了30所学校,每个学校有一个自己的差异字段,那么这个表就要有30个冗余字段来应对这种差异性。且不说每次加冗余都要改动系统,且不说冗余多了浪费空间降低传输效率,光说怎么维护这些冗余,我就已经觉得是灾难了:Teacher表有差异字段,其他表也会有。假设一个中型系统,60张表,其中30张实体表30张关系表不算过分吧。那么总共要维护 30(表数量)*30(冗余数量) = 900 个差异字段
第二个想法是建立一张冗余表来储存差异。这种其实和表中加冗余异曲同工,就不多加分析了,留给大家自己思考
第三个想法是建立不同的数据库。其实本来每个学校的数据库就是不同的,唔……怎么说呢,A学校自己的数据库中的表,存的是A学校自己的特有字段,B学校存B学校的特有字段。两者之间并无关系,然后Model用l继承的思路来设计(详见上一篇文章),通过配置文件来选择恰当的数据库和其对应的Model
是的,这种方法挺好的,唯一的不足可能就是比较依赖于ORM——使用ORM来生成数据库,以及T-SQL语句
如果您是一个关系型数据库的重度爱好者,那么这篇文章到这就结束了,下面的东西不会对您胃口的
/*=============================================================*/
众所周知,因为大量使用了反射,ORM的效率不是那么的高,而且本身关系型数据库的可拓展性也不是那么的好
作为一个激进的开发者,我一直希望在项目中尝试NoSql
下面的一篇文章我会讲解如何用MongoDB来解决前文描述的差异性问题,敬请期待
关于MongoDB的入门,推荐两篇文章:
MongoDB实战开发 【零基础学习,附完整Asp.net示例】
顺便附上一个小测试:在.net 4环境下分别插入5W条数据,分别是EF5、Nhibernate、ADO.Net向Sql server 2008插入,以及MongoDB官方驱动向MongoDB插入
EF耗时:00:00:25.4972758
ADO.NET耗时:00:00:23.8307860
NHibernate耗时:00:00:26.0199898
MongoDB耗时:00:00:01.9474134
在这里,EF每次插入1000条数据(批量插入),其他方式都是单条插入;NHibernate关闭了一级缓存;
MongoDB使用的是“离弦之箭”的插入方式
MongoDB使用的是安全的插入模式(不会丢失数据)
/*=============================================================*/
PS:在闪存里面说在博文中自曝照片的,不过因为这篇文章是在公司写的,就等下一篇再说吧
再PS:马上10·1了哟吼吼吼