机器学习-Sklearn-07(无监督学习聚类算法KMeans)
机器学习-Sklearn-07(无监督学习聚类算法KMeans)
学习07
1 概述
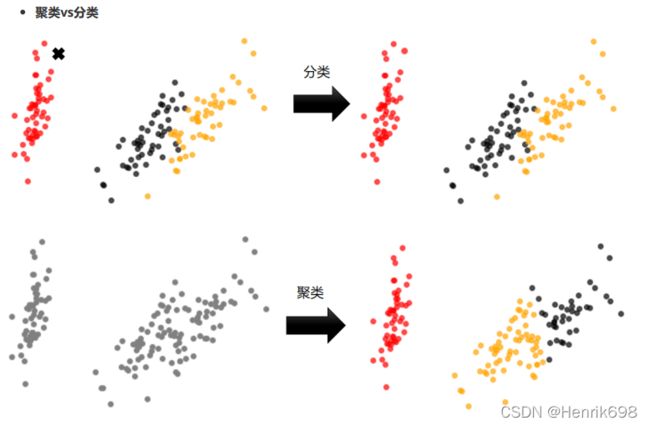
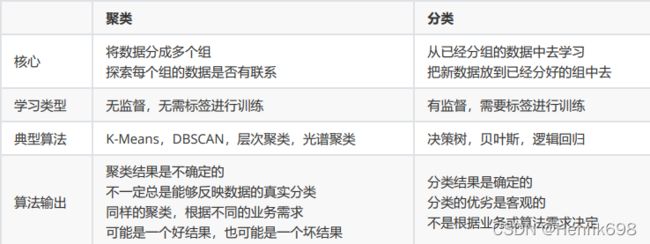
1.1 无监督学习与聚类算法
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客户价值判断模型RFM,就常常和聚类分析共同使用。再比如,聚类可以用于降维和矢量量化(vector quantization),可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
1.2 sklearn中的聚类算法
聚类算法在sklearn中有两种表现形式,一种是类(和我们目前为止学过的分类算法以及数据预处理方法们都一样),需要实例化,训练并使用接口和属性来调用结果。另一种是函数(function),只需要输入特征矩阵和超参数,即可返回聚类的结果和各种指标。

输入数据
需要注意的一件重要事情是,该模块中实现的算法可以采用不同类型的矩阵作为输入。 所有方法都接受形状[n_samples,n_features]的标准特征矩阵,这些可以从sklearn.feature_extraction模块中的类中获得。
对于亲和力传播,光谱聚类和DBSCAN,还可以输入形状[n_samples,n_samples]的相似性矩阵,我们可以使用sklearn.metrics.pairwise模块中的函数来获取相似性矩阵。
2 KMeans
2.1 KMeans是如何工作的
作为聚类算法的典型代表,KMeans可以说是最简单的聚类算法没有之一,那它是怎么完成聚类的呢?
关键概念:簇与质心
KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的数据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
簇中所有数据的均值 通常被称为这个簇的“质心”(centroids)。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
在KMeans算法中,簇的个数K是一个超参数,需要我们人为输入来确定。KMeans的核心任务就是根据我们设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下:

那什么情况下,质心的位置会不再变化呢?当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了。
这个过程在可以由下图来显示,我们规定,将数据分为4簇(K=4),其中白色X代表质心的位置:

可以看见,第六次迭代之后,基本上质心的位置就不再改变了,生成的簇也变得稳定。此时我们的聚类就完成了,我们可以明显看出,KMeans按照数据的分布,将数据聚集成了我们规定的4类,接下来我们就可以按照我们的业务需求或者算法需求,对这四类数据进行不同的处理。
2.2 簇内误差平方和的定义和解惑
聚类算法聚出的类有什么含义呢?这些类有什么样的性质?我们认为,被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的。
这个听上去和我们在上周的评分卡案例中讲解的“分箱”概念有些类似,即我们分箱的目的是希望,一个箱内的人有着相似的信用风险,而不同箱的人的信用风险差异巨大,以此来区别不同信用度的人,因此我们追求“组内差异小,组间差异大”。
聚类算法也是同样的目的,我们追求“簇内差异小,簇外差异大”。而这个“差异“,由样本点到其所在簇的质心的距离来衡量。

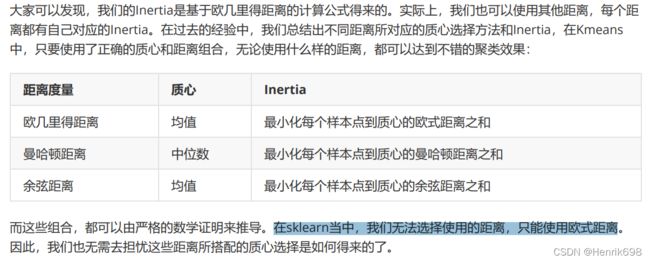
如我们采用欧几里得距离,则一个簇中所有样本点到质心的距离的平方和为:

其中,m为一个簇中样本的个数,j是每个样本的编号。这个公式被称为簇内平方和(cluster Sum of Square),又叫做Inertia。而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum of Square),又叫做total inertia。Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。**因此KMeans追求的是,求解能够让Inertia最小化的质心。**实际上,在质心不断变化不断迭代的过程中,总体平方和是越来越小的。我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化了。如此,K-Means的求解过程,就变成了一个最优化问题。
Kmeans有损失函数吗?
K-Means不存在什么损失函数,Inertia更像是Kmeans的模型评估指标,而非损失函数。但我们类比过了Kmeans中的Inertia和逻辑回归中的损失函数的功能,我们发现它们确实非常相似。所以,从“求解模型中的某种信息,用于后续模型的使用“这样的功能来看,我们可以认为Inertia是Kmeans中的损失函数,虽然这种说法并不严谨。
对比来看,在决策树中,我们有衡量分类效果的指标准确度accuracy,准确度所对应的损失叫做泛化误差,但我们不能通过最小化泛化误差来求解某个模型中需要的信息,我们只是希望模型的效果上表现出来的泛化误差很小。因此决策树,KNN等算法,是绝对没有损失函数的。
2.3 KMeans算法的时间复杂度
除了模型本身的效果之外,我们还使用另一种角度来度量算法:算法复杂度。算法的复杂度分为时间复杂度和空间复杂度,时间复杂度是指执行算法所需要的计算工作量,常用大O符号表述;而空间复杂度是指执行这个算法所需要的内存空间。
和KNN一样,KMeans算法是一个计算成本很大的算法。在这里,我们介绍KMeans算法的时间和空间复杂度来加深对KMeans的理解。

在实践中,比起其他聚类算法,k-means算法已经快了,但它一般找到Inertia的局部最小值。 这就是为什么多次重启它会很有用。
3 sklearn.cluster.KMeans

3.1 重要参数n_clusters
n_clusters是KMeans中的k,表示着我们告诉模型我们要分几类。这是KMeans当中唯一一个必填的参数,默认为8类,但通常我们的聚类结果会是一个小于8的结果。通常,在开始聚类之前,我们并不知道n_clusters究竟是多少,因此我们要对它进行探索。
3.1.1 先进行一次聚类看看吧
当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这个数据集的数据分布,以此来为我们聚类时输入的n_clusters做一个参考。首先,我们来自己创建一个数据集。这样的数据集是我们自己创建,所以是有标签的。
from sklearn.datasets import make_blobs #导入用来制作簇数据的类
import matplotlib.pyplot as plt
#自己创建数据集
#参数centers表示数据生成几个簇,这里分了4个簇。
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
X.shape
![]()
y.shape
![]()
fig, ax1 = plt.subplots(1) #括号内的参数表示生成子图的个数。
fig #fig表示画布

ax1 #ax1表示画布对象
![]()
fig, ax1 = plt.subplots(1) #括号内的参数表示生成子图的个数。
ax1.scatter(X[:, 0], X[:, 1]
,marker=‘o’ #点的形状
,s=8 #点的大小
)
plt.show()
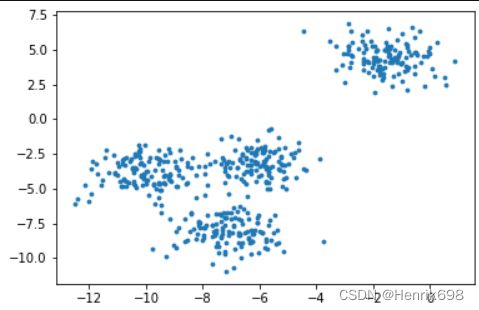
#如果我们想要看见这个点的分布,怎么办?
color = [“red”,“pink”,“orange”,“gray”]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[yi, 0], X[yi, 1]
,marker=‘o’ #点的形状
,s=8 #点的大小
,c=color[i] #绘制不同颜色
)
plt.show()
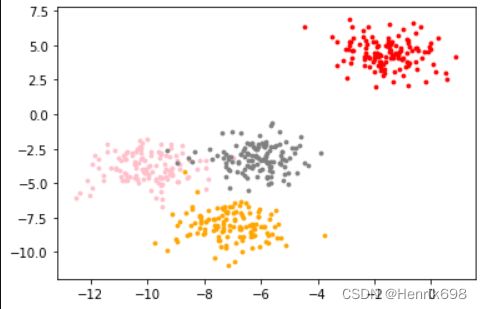
#基于这个分布,我们来使用Kmeans进行聚类。首先,我们要猜测一下,这个数据中有几簇?
from sklearn.cluster import KMeans
n_clusters = 3
#实例化,并fit训练
#参数random_state为例让模型稳定
#完成了聚类,不需要调用接口,求出了质心,数据中所有x都按照质心已经分好,聚类已经完成了。
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
#重要属性labels_,查看聚类的类别,每个样本所对应的类。
y_pred = cluster.labels_
y_pred #预测出来的结果。

#KMeans因为并不需要建立模型或者预测结果,因此我们只需要fit就能够得到聚类结果了
#KMeans也有接口predict和fit——predict,表示学习数据X并不对X的类进行预测。
#但所有得到的结果和我们不调用predict,直接fit之后调用属性labels一模一样。
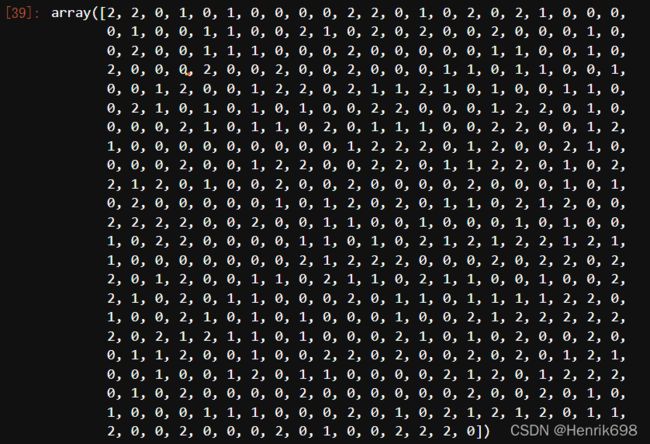
pre = cluster.fit_predict(X)
pre
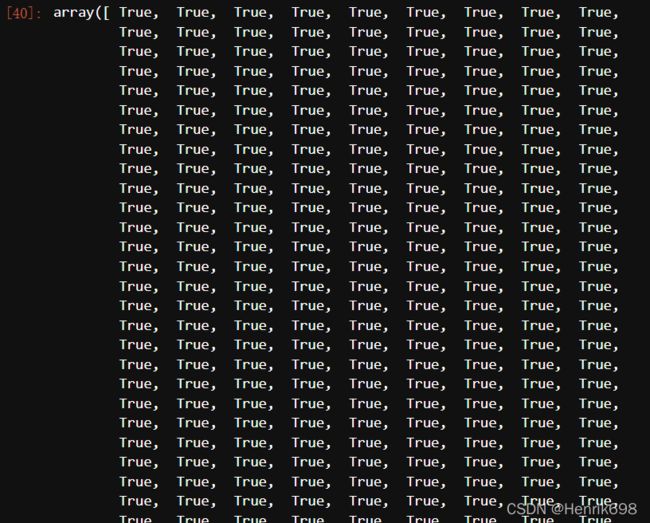
pre == y_pred #判断这两个是否相同(相同)
#我们什么时候需要predict呢?当数据量太大的时候!
#其实我们不必使用所有的数据来寻找质心,少量的数据就可以帮助我们确定质心了
#当我们数据量非常大的时候,我们可以使用部分数据来帮助我们确认质心。
#剩下的数据的聚类结果,使用predict来调用。
#数据有500行,现在取出250行进行fit
cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:250])
#以200行数据训练后,以此来预测其他数据的分类结果
y_pred_ = cluster_smallsub.predict(X)
y_pred_
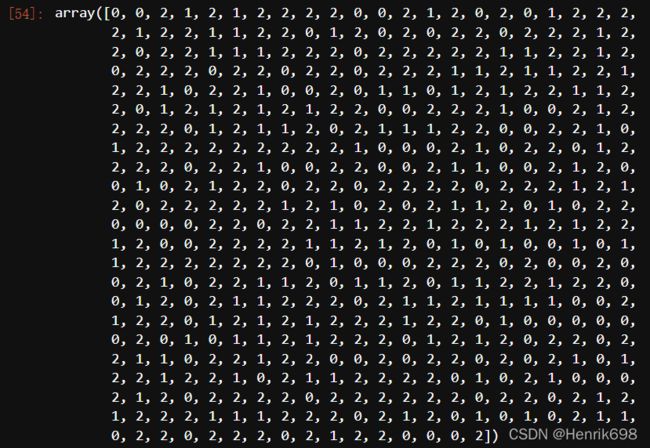
y_pred
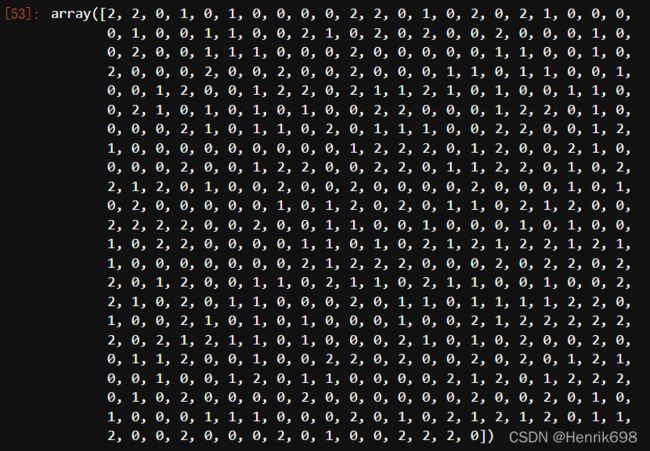
#以200行数据训练后预测的结果,与全部500行数据进行训练的结果是否一致呢?
y_pred == y_pred_ #发现数据不完全相似
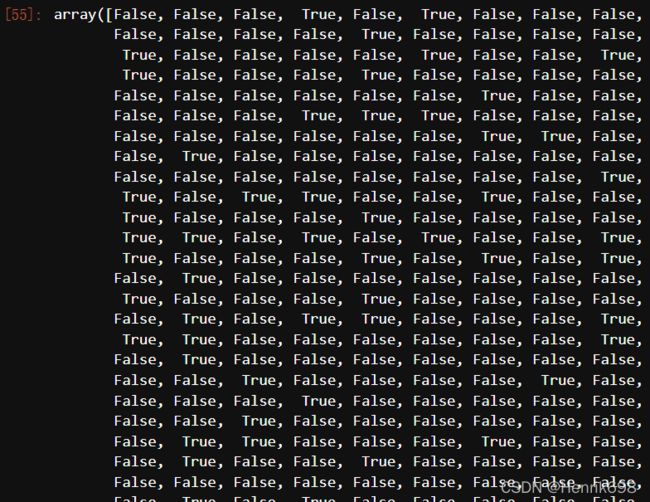
#再运行一下,之前收到了一些影响
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
#质心
centroid = cluster.cluster_centers_
centroid
#质心的数量受到参数n_clusters影响

centroid.shape
![]()
fig, ax1 = plt.subplots(1)
ax1.scatter(centroid[:,0],centroid[:,1]
,marker=“x”
,s=15
,c=“black”)
plt.show()
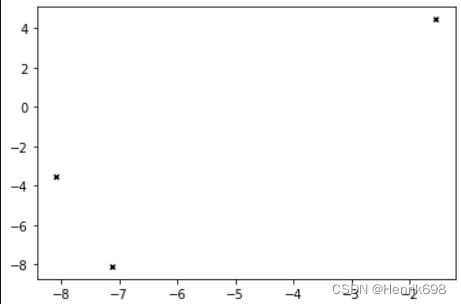
#返回总距离的平方和
inertia = cluster.inertia_
inertia
#在所有其他聚类算法来说,这个值较大
#inertia越小越好
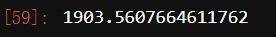
color = [“red”,“pink”,“orange”,“gray”]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_predi, 0], X[y_predi, 1]
,marker=‘o’
,s=8
,c=color[i]
)
ax1.scatter(centroid[:,0],centroid[:,1]
,marker=“x”
,s=15
,c=“black”)
plt.show()
#调整n_clusters,查看inertia_的结果
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
n_clusters = 5
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
n_clusters = 6
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
n_clusters = 500
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
#随着n_clusters越来越大,inertia_降维0,所以n_clusters会影响inertia_,但是不能说调整n_clusters会让inertia_越来越好。
#只有在n_clusters固定不变的情况下,使得inertia_越小才能说越好。
#所以inertia_不是一个有效的模型评估指标。
3.1.2 聚类算法的模型评估指标
不同于分类模型和回归,聚类算法的模型评估不是一件简单的事。在分类中,有直接结果(标签)的输出,并且分类的结果有正误之分,所以我们使用预测的准确度,混淆矩阵,ROC曲线等等指标来进行评估,但无论如何评估,都是在”模型找到正确答案“的能力。而回归中,由于要拟合数据,我们有SSE均方误差,有损失函数来衡量模型的拟合程度。但这些衡量指标都不能够使用于聚类。
面试高危问题:如何衡量聚类算法的效果?
聚类模型的结果不是某种标签输出,并且聚类的结果是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。那我们如何衡量聚类的效果呢?
记得我们说过,KMeans的目标是确保“簇内差异小,簇外差异大”,我们就可以通过衡量簇内差异来衡量聚类的效果。
我们刚才说过,Inertia是用距离来衡量簇内差异的指标,因此,我们是否可以使用Inertia来作为聚类的衡量指标呢?Inertia越小模型越好嘛。

那我们可以使用什么指标呢?分两种情况来看。
3.1.2.1 当真实标签已知的时候
虽然我们在聚类中不输入真实标签,但这不代表我们拥有的数据中一定不具有真实标签,或者一定没有任何参考信息。当然,在现实中,拥有真实标签的情况非常少见(几乎是不可能的)。如果拥有真实标签,我们更倾向于使用分类算法。但不排除我们依然可能使用聚类算法的可能性。如果我们有样本真实聚类情况的数据,我们可以对于聚类算法的结果和真实结果来衡量聚类的效果。常用的有以下三种方法:

3.1.2.2 当真实标签未知的时候:轮廓系数
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚类,是完全依赖于评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。其中轮廓系数是最常用的聚类算法的评价指标。它是对每个样本来定义的,它能够同时衡量:
1)样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离
2)样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中的所有点之间的平均距离
根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。

很容易理解轮廓系数范围是(-1,1),其中值越接近1表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。当轮廓系数为0时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。可以总结为轮廓系数越接近于1越好,负数则表示聚类效果非常差。
如果一个簇中的大多数样本具有比较高的轮廓系数,则簇会有较高的总轮廓系数,则整个数据集的平均轮廓系数越高,则聚类是合适的。如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的,聚类的超参数K可能设定得太大或者太小。
在sklearn中,我们使用模块metrics中的类silhouette_score来计算轮廓系数,它返回的是一个数据集中,所有样本的轮廓系数的均值。但我们还有同在metrics模块中的silhouette_sample,它的参数与轮廓系数一致,但返回的是数据集中每个样本自己的轮廓系数。
我们来看看轮廓系数在我们自建的数据集上表现如何:
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
from sklearn.cluster import KMeans
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
n_clusters = 3
#实例化,并fit训练
#参数random_state为例让模型稳定
#完成了聚类,不需要调用接口,求出了质心,数据中所有x都按照质心已经分好,聚类已经完成了。
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
#重要属性labels_,查看聚类的类别,每个样本所对应的类。
y_pred = cluster.labels_ #预测出来的结果。
X.shape
![]()
y_pred.shape
![]()
#第一个参数为特征矩阵,第二个参数为模型的聚类结果
silhouette_score(X,y_pred) #这里是n_clusters为3的情况下的轮廓系数均值
![]()
#调整n_clusters,查看inertia_的结果和轮廓系数均值的结果
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
silhouette_score(X,cluster_.labels_) #轮廓系数均值升高了,分4簇的确比分3簇效果要好
![]()
n_clusters = 5
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
silhouette_score(X,cluster_.labels_) #分5簇比分4簇轮廓系数均值降低了
![]()
n_clusters = 6
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
![]()
silhouette_score(X,cluster_.labels_) #分6簇比分5簇轮廓系数降低了
![]()
#查看数据集中每个样本自己的轮廓系数
silhouette_samples(X,y_pred)
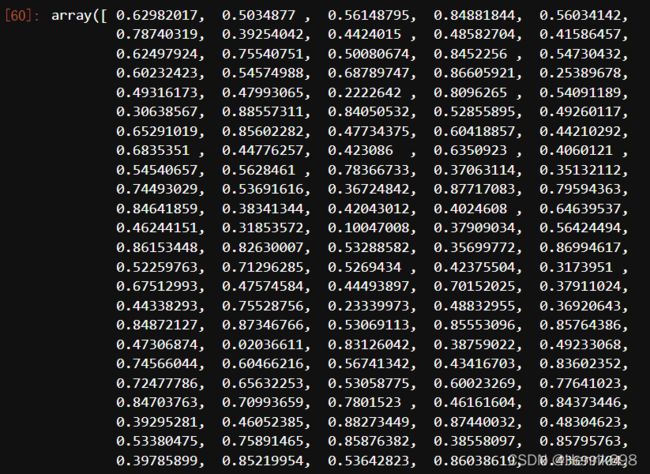
silhouette_samples(X,y_pred).shape
![]()
silhouette_samples(X,y_pred).mean()
![]()
#silhouette_samples(X,y_pred).mean()的结果与silhouette_score(X,y_pred) 的结果相同
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。
但它在每个簇的分割比较清晰时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
3.1.2.3 当真实标签未知的时候:Calinski-Harabaz Index
除了轮廓系数是最常用的,我们还有卡林斯基-哈拉巴斯指数(Calinski-Harabaz Index,简称CHI,也被称为方差比标准),戴维斯-布尔丁指数(Davies-Bouldin)以及权变矩阵(Contingency Matrix)可以使用。
在这里我们重点来了解一下卡林斯基-哈拉巴斯指数。Calinski-Harabaz指数越高越好。对于有k个簇的聚类而言,Calinski-Harabaz指数s(k)写作如下公式:
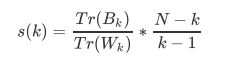

from sklearn.metrics import calinski_harabasz_score
from sklearn.cluster import KMeans
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
n_clusters = 3
#实例化,并fit训练
#参数random_state为例让模型稳定
#完成了聚类,不需要调用接口,求出了质心,数据中所有x都按照质心已经分好,聚类已经完成了。
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
#重要属性labels_,查看聚类的类别,每个样本所对应的类。
y_pred = cluster.labels_ #预测出来的结果。
X
y_pred
calinski_harabasz_score(X, y_pred)
![]()
“”"
虽然calinski-Harabaz指数没有界,在凸型的数据上的聚类也会表现虚高。但是比起轮廓系数,它有一个巨大的优点,就是计算非常快速。之前我们使用过魔法命令%%timeit来计算一个命令的运算时间,今天我们来选择另一种方法:时间戳计算运行时间。
“”"
#时间戳计算运行的时间
from time import time
#time():记下每一次time()这一行命令时的时间戳。
#时间戳是一行数字,用来记录此时此刻的时间。
t0 = time()
calinski_harabasz_score(X, y_pred)
time() - t0
![]()
t0 = time()
silhouette_score(X,y_pred)
time() - t0
![]()
#可以看得出,calinski-harabaz指数比轮廓系数的计算块了一倍不止。想想看我们使用的数据量,如果是一个以万计的数据,轮廓系数就会大大拖慢我们模型的运行速度了。
t0 #代表时间
![]()
#时间戳可以通过datetime中的函数fromtimestamp转换成真正的时间格式。
import datetime
datetime.datetime.fromtimestamp(t0).strftime(“%Y-%m-%d %H:%M:%S”)
![]()
3.1.3 案例:基于轮廓系数来选择n_clusters
我们通常会绘制轮廓系数分布图和聚类后的数据分布图来选择我们的最佳n_clusters。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
import pandas as pd
from sklearn.datasets import make_blobs #导入用来制作簇数据的类
from sklearn.metrics import calinski_harabasz_score
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
#基于轮廓系数来选择最佳的n_clusters
#不想要学习曲线,学习曲线不够有力。
#基于我们轮廓系数来选择最佳的n_clusters
#知道每个聚出来的类的轮廓系数是多少,还想要一个个类之间的轮廓系数的对比
#知道聚类完毕之后图像的分布是什么模样。
#先设定我们要分成的簇数
n_clusters = 4
#创建一个画布,画布上共有一行两列两个图
fig, (ax1, ax2) = plt.subplots(1, 2)
#画布尺寸
fig.set_size_inches(18, 7)
#第一个图是我们的轮廓系数图像,是由各个簇的轮廓系数组成的横向条形图。
#横向条形图的横坐标是我们的轮廓系数取值,纵坐标是我们的每个样本,因为轮廓系数是对于每一个样本进行计算的。
#首先我们来设定横坐标。
#轮廓系数的取值范围在[-1,1]之间,但我们至少是希望轮廓系数要大于0的
#太成的横坐标不利于我们的可视化,所以只设定X轴的取值在[-0.1,1]之间。
ax1.set_xlim([-0.1, 1]) #设置X轴坐标范围
#接下来设定纵坐标,通常来说,纵坐标是从0开始,最大值取到X.shape[0]的取值
#但我们希望,每个簇能够排在一起,不用的簇之间能够有一定的空隙。
#以便我们看到不同的条形图聚合成的块,理解它是对应了哪一个簇。
#因此我们在设定纵坐标的取值范围的时候,在X.shape[0]上,加上一个距离(n_clusters+1)*10,留作间隔用
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
#开始建模,调用聚类好的标签
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
#调用轮廓系数分数,注意,silhouette_score生成的是所有样本点的轮廓系数均值。
#两个需要输入的参数是,特征矩阵X和聚类完毕后的标签。
silhouette_avg = silhouette_score(X, cluster_labels)
#用print来报告一下结果,现在的簇数量(n_clusters)下,整体的轮廓系数究竟有多少。
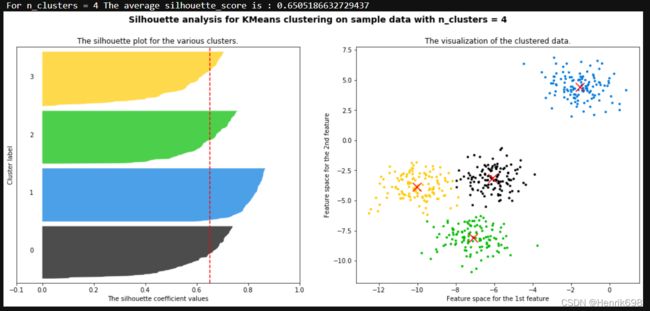
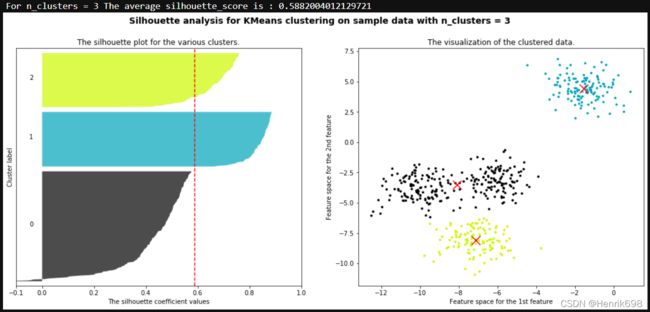
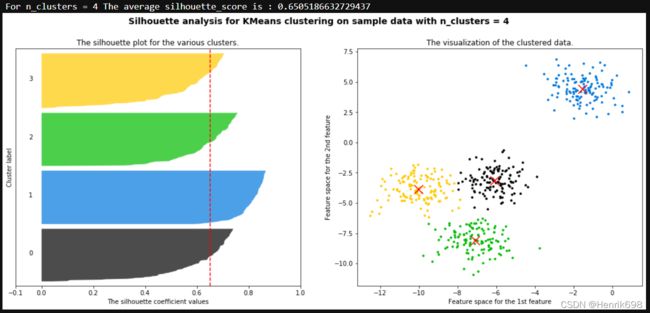
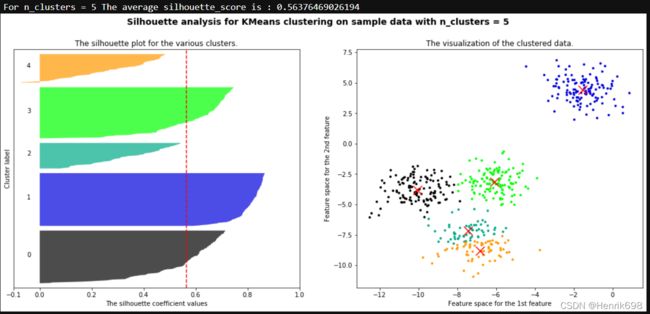
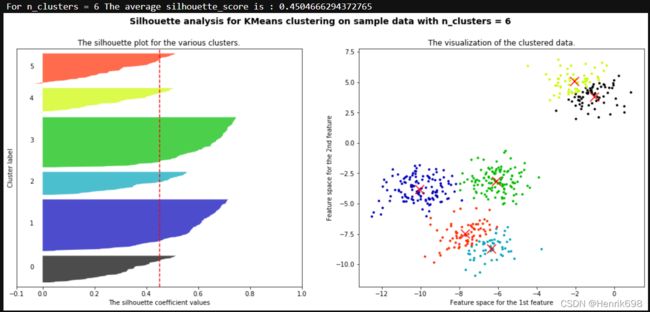
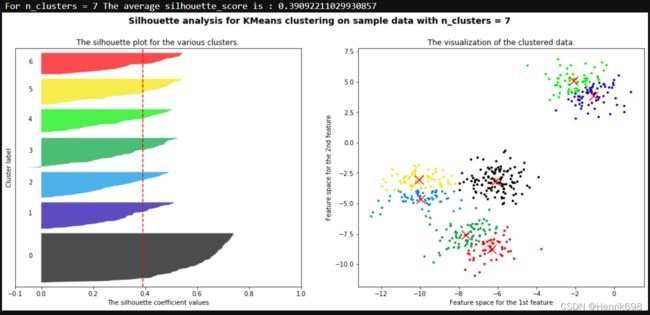
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
#调用silhouette_samples,返回每个样本点的轮廓系数,这就是我们的横坐标。
sample_silhouette_values = silhouette_samples(X, cluster_labels)
#设定y轴上的初始取值
y_lower = 10
#接下来,对每一个簇进行循环
for i in range(n_clusters):
#从每个样本的轮廓系数结果中抽取出第i个簇的轮廓系数,并对他进行排序
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
#注意,.sort()这个命令会直接改掉原数据的顺序
ith_cluster_silhouette_values.sort()
#查看这一个簇中究竟有多少个样本
size_cluster_i = ith_cluster_silhouette_values.shape[0]
#这一个簇在y轴上的取值,应该是由初始值(y_lower)开始,到初始值+加上这个簇中的样本数量结束(y_upper)
y_upper = y_lower + size_cluster_i
#colormap库中的,使用小数来调用颜色的函数
#在nipy_spectraL([输入任意小数来代表一个颜色])
#在这里,我们希望每个簇的颜色是不同的,我们需要的颜色种类刚好是循环的个数的种类
#在这里,只要能够确保,每次循环生成的小数是不同的,可以使用任意方式来获取小数
#在这里,我是用i的浮点数除以n_clusters,在不同的i下,自然生成不同的小数
#以确保所有的簇会有不同的颜色
color = cm.nipy_spectral(float(i)/n_clusters)
#开始填充子图1中的内容
#fill_between是填充曲线与直角之间的空间的函数
#fill_betweenx的直角是在纵坐标上
#fill_betweeny的直角是在横坐标上
#fill_betweenx的参数应该输入(定义曲线的点的横坐标,定义曲线的点的纵坐标,柱状图的颜色)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
#为每个簇的轮廓系数写上簇的编号,并且让簇的编号显示坐标轴上每个条形图的中间位置
#text的参数为(要显示编号的位置的横坐标,要显示编号的位置的纵坐标,要显示的编号内容)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
#为下一个簇计算新的y轴上的初始值,是每一次迭代之后,y的上线再加上10
#以此来保证,不同的簇的图像之间显示有空隙
y_lower = y_upper + 10
#给图1加上标题,横坐标轴,纵坐标轴的标签
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#把整个数据集上的轮廓系数的均值以虚线的形式放入我们的图中
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
#让y轴不显示任何刻度
ax1.set_yticks([])
#让x轴上的刻度显示为我们规定的列表
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
#开始对第二个图进行处理,首先获取新颜色,由于这里没有循环,因此我们需要一次性生成多个小数来获取多个颜色。
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=colors
)
#把生成的质心放到图像中去
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
#为图二设置标题,横坐标题,纵坐标题
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
#为整个图设置标题
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
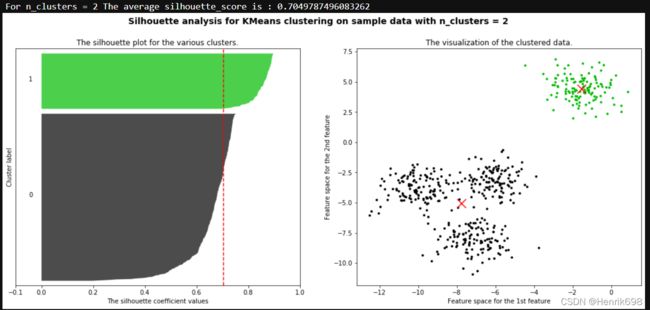
将上述过程包装成一个循环,可以得到:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
for n_clusters in [2,3,4,5,6,7]:
n_clusters = n_clusters
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
3.2 重要参数init & random_state & n_init:初始质心怎么放好?
在K-Means中有一个重要的环节,就是放置初始质心。如果有足够的时间,K-means一定会收敛,但Inertia可能收敛到局部最小值。是否能够收敛到真正的最小值很大程度上取决于质心的初始化。init就是用来帮助我们决定初始化方式的参数。
初始质心放置的位置不同,聚类的结果很可能也会不一样,一个好的质心选择可以让K-Means避免更多的计算,让算法收敛稳定且更快。在之前讲解初始质心的放置时,我们是使用”随机“的方法在样本点中抽取k个样本作为初始质心,这种方法显然不符合”稳定且更快“的需求。为此,我们可以使用random_state参数来控制每次生成的初始质心都在相同位置,甚至可以画学习曲线来确定最优的random_state是哪个整数。
一个random_state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则sklearn中的K-means并不会只选择一个随机模式扔出结果,而会在每个随机数种子下运行多次,并使用结果最好的一个随机数种子来作为初始质心。我们可以使用参数n_init来选择,每个随机数种子下运行的次数。这个参数不常用到,默认10次,如果我们希望运行的结果更加精确,那我们可以增加这个参数n_init的值来增加每个随机数种子下运行的次数。
然而这种方法依然是基于随机性的。
为了优化选择初始质心的方法,2007年Arthur, David, and Sergei Vassilvitskii三人发表了论文“k-means++: The advantages of careful seeding”,他们开发了”k-means ++“初始化方案,使得初始质心(通常)彼此远离,以此来 引导出比随机初始化更可靠的结果。在sklearn中,我们使用参数init ='k-means ++'来选择使用k-means ++作为质心初始化的方案。通常来说,我建议保留默认的"k-means++"的方法。
init:可输入"k-means++“,“random"或者一个n维数组。这是初始化质心的方法,默认"k-means++”。输入"kmeans++”:一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
random_state:控制每次质心随机初始化的随机数种子。
n_init:整数,默认10,使用不同的质心随机初始化的种子来运行k-means算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出。
from time import time
from sklearn.datasets import make_blobs #导入用来制作簇数据的类
from sklearn.metrics import calinski_harabasz_score
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
X.shape
![]()
y.shape
![]()
#init默认等于"k-means++“,所以可以不写出来
plus = KMeans(n_clusters = 10).fit(X)
#n_iter为迭代次数,质心选取的越好,模型收敛越快,迭代次数就越小
plus.n_iter_
![]()
#init为"random”
random = KMeans(n_clusters = 10,init=“random”,random_state=420).fit(X)
random.n_iter_
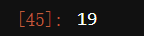
#运行时间对比
t0=time()
#init默认等于"k-means++“,所以可以不写出来
plus = KMeans(n_clusters = 10).fit(X)
#n_iter为迭代次数,质心选取的越好,模型收敛越快,迭代次数就越小
plus.n_iter_
time()-t0
![]()
t0=time()
#init为"random”
random = KMeans(n_clusters = 10,init=“random”,random_state=420).fit(X)
random.n_iter_
time()-t0
![]()
#init="k-means++"运行时间要长于init=“random”
#这可能是由于在最开始选择质心的时候init="k-means++"会花费更多时间
3.3 重要参数max_iter & tol:让迭代停下来
在之前描述K-Means的基本流程时我们提到过,当质心不再移动,Kmeans算法就会停下来。但在完全收敛之前,我们也可以使用max_iter,最大迭代次数,或者tol,两次迭代间Inertia下降的量,这两个参数来让迭代提前停下来。有时候,当我们的n_clusters选择不符合数据的自然分布,或者我们为了业务需求,必须要填入与数据的自然分布不合的n_clusters,提前让迭代停下来反而能够提升模型的表现。
max_iter:整数,默认300,单次运行的k-means算法的最大迭代次数。
tol:浮点数,默认1e-4,两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下
from time import time
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs #导入用来制作簇数据的类
from sklearn.metrics import calinski_harabasz_score
from sklearn.metrics import silhouette_samples, silhouette_score
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
random = KMeans(n_clusters = 10,init=“random”,max_iter=10,random_state=420).fit(X)
y_pred_max10 = random.labels_
silhouette_score(X,y_pred_max10)
![]()
random = KMeans(n_clusters = 10,init=“random”,max_iter=20,random_state=420).fit(X)
y_pred_max20 = random.labels_
silhouette_score(X,y_pred_max20)
![]()
3.4 重要属性与重要接口
到这里,所有的重要参数就讲完了。在使用模型的过程中,我也向大家呈现了各种重要的属性与接口,在这一小节来复习一下:
3.5 函数cluster.k_means

函数k_means的用法其实和类非常相似,不过函数是输入一系列值,而直接返回结果。一次性地,函数k_means会依次返回质心,每个样本对应的簇的标签,inertia以及最佳迭代次数。
from time import time
from sklearn.datasets import make_blobs #导入用来制作簇数据的类
from sklearn.metrics import calinski_harabasz_score
from sklearn.metrics import silhouette_samples, silhouette_score
#自己创建数据集
#参数centers表示数据生成几个簇
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
from sklearn.cluster import k_means
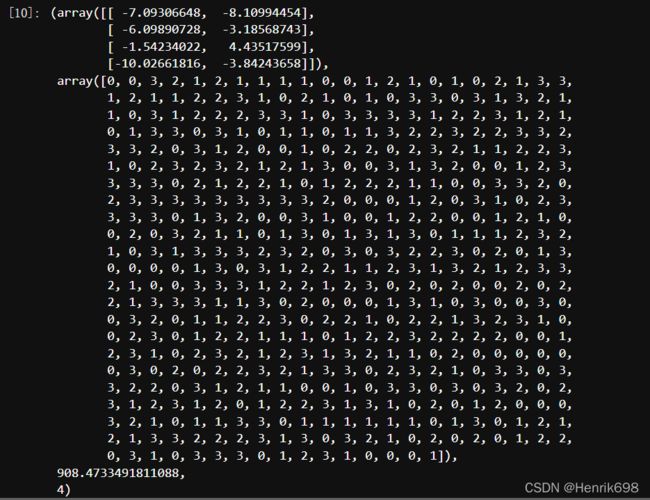
k_means(X,4,return_n_iter=True)
4 案例:聚类算法用于降维,KMeans的矢量量化应用
K-Means聚类最重要的应用之一是非结构数据(图像,声音)上的矢量量化(VQ)。非结构化数据往往占用比较多的储存空间,文件本身也会比较大,运算非常缓慢,我们希望能够在保证数据质量的前提下,尽量地缩小非结构化数据的大小,或者简化非结构化数据的结构。矢量量化就可以帮助我们实现这个目的。KMeans聚类的矢量量化本质是一种降维运用,但它与我们之前学过的任何一种降维算法的思路都不相同。特征选择的降维是直接选取对模型贡献最大的特征,PCA的降维是聚合信息,而矢量量化的降维是在同等样本量上压缩信息的大小,即不改变特征的数目也不改变样本的数目,只改变在这些特征下的样本上的信息量。
对于图像来说,一张图片上的信息可以被聚类如下表示:
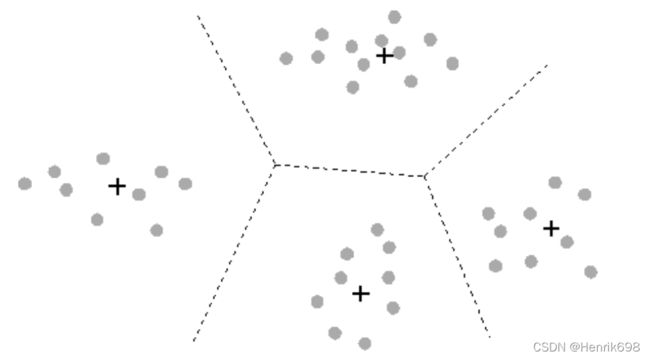
这是一组40个样本的数据,分别含有40组不同的信息(x1,x2)。我们将代表所有样本点聚成4类,找出四个质心,我们认为,这些点和他们所属的质心非常相似,因此他们所承载的信息就约等于他们所在的簇的质心所承载的信息。于是,我们可以使用每个样本所在的簇的质心来覆盖原有的样本,有点类似四舍五入的感觉,类似于用1来代替0.9和0.8。这样,40个样本带有的40种取值,就被我们压缩了4组取值,虽然样本量还是40个,但是这40个样本所带的取值其实只有4个,就是分出来的四个簇的质心。
用K-Means聚类中获得的质心来替代原有的数据,可以把数据上的信息量压缩到非常小,但又不损失太多信息。我们接下来就通过一张图图片的矢量量化来看一看K-Means如何实现压缩数据大小,却不损失太多信息量。
#1. 导入需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin
from sklearn.datasets import load_sample_image
from sklearn.utils import shuffle
#2. 导入数据,探索数据
china = load_sample_image(“china.jpg”)
china
#查看数据类型
china.dtype

china.shape
#长宽像素
![]()
china[0][0] #(三个数决定的颜色)
![]()
#包含多少种不同的颜色呢?去除重复值
newimage = china.reshape((427 * 640,3))
newimage
newimage.shape #所有像素的颜色
import pandas as pd
pd.DataFrame(newimage).drop_duplicates().shape
#现在有9万多种颜色
![]()
#图像可视化
plt.figure(figsize=(15,15))
plt.imshow(china) #.imshow()只导入三维数组形成的图片

#以上过程是探索图片的固定流程
#查看模块中的另一张图片
flower = load_sample_image(“flower.jpg”)
plt.figure(figsize=(15,15))
plt.imshow(flower)
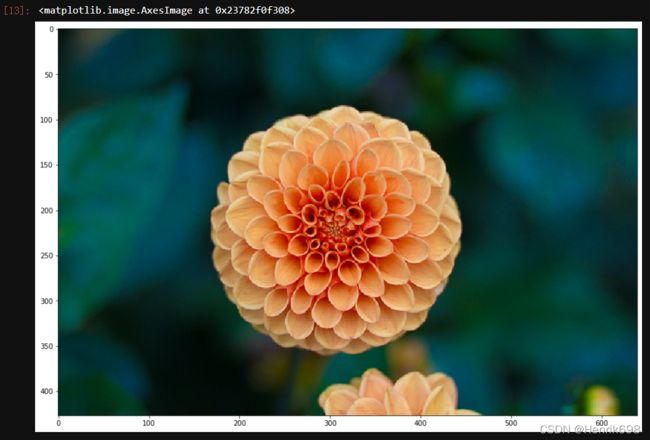
#3. 决定超参数,数据预处理
#kmeans用于图像压缩,将9w种颜色聚类成64类
#数据预处理
china.max()
![]()
n_clusters = 64
#plt.imshow在浮点数上表现非常优异,在这里我们把China中的数据,转换为浮点数,压缩到[0,1]之间
china = np.array(china, dtype=np.float64) / china.max()
china
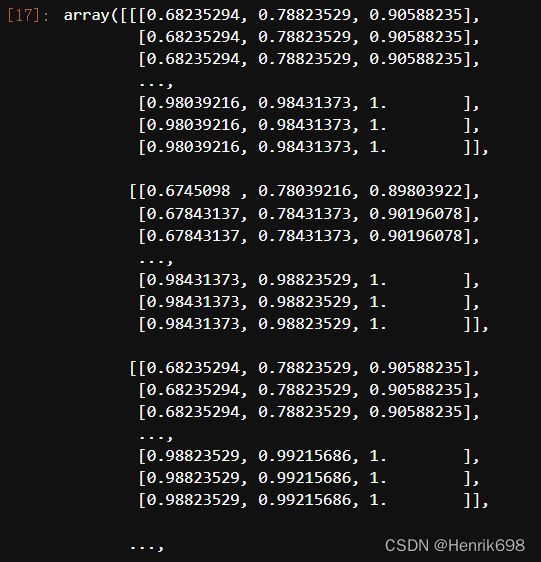
(china<0).sum() #没有任何一个数小于0
![]()
(china>1).sum() #没有任何一个数大于1
![]()
#目前说明china数据已经压缩到0到1之间了
#把china从图像格式,转换成矩阵格式。即三维数组转为二维矩阵
w, h, d = original_shape = tuple(china.shape)
w
![]()
h
![]()
d
![]()
#表示如果不等于3就请帮我报错
assert d == 3
#assert相当于raise error if not,表示为,“不为True就报错”
#要求d必须等于3,如果不等于,就报错
#展示assert功能
d_ = 5
assert d_ == 3, “一个格子中的特征数目不等于3种”

#展示assert功能
d_ = 3
assert d_ == 3, “一个格子中的特征数目不等于3种”
#发现不报错了
#reshape是改变结构
image_array = np.reshape(china, (w * h, d))
image_array
image_array.shape
![]()
#np.reshape(a,newshape,order=‘C’),order='C’不需要在意,reshape函数的第一个参数a是要改变结构的对象,第二个参数是要改变的新结构
#展示np.reshape的效果
a = np.random.random((2,4))
a

a.shape
![]()
a.reshape((4,2))
a.reshape((4,2)).shape
![]() np.reshape(a,(4,2)).shape
np.reshape(a,(4,2)).shape
![]()
a.reshape((4,2)) ==np.reshape(a,(4,2))
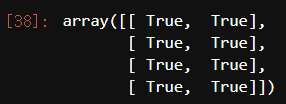
np.reshape(a,(2,2,2))
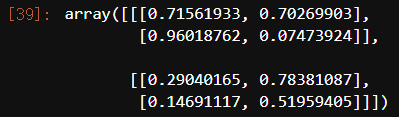
np.reshape(a,(2,2,2)).shape #三维数组
![]()
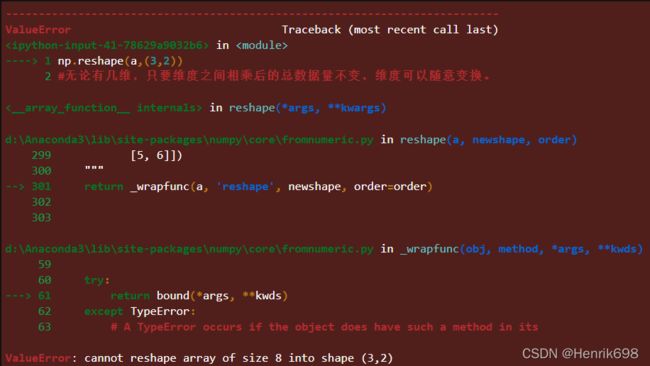
np.reshape(a,(3,2))
#无论有几维,只要维度之间相乘后的总数据量不变,维度可以随意变换。
#总结一下,就下面几行代码
n_clusters = 64
china = np.array(china, dtype=np.float64) / china.max()
w, h, d = original_shape = tuple(china.shape)
assert d == 3
image_array = np.reshape(china, (w * h, d))
#4. 对数据进行K-Means的矢量量化
#开始建模
#对数据进行K-Means的矢量量化
#首先,先使用1000个数据来找出质心
#shuffle是将顺序打乱的函数
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
kmeans.cluster_centers_

kmeans.cluster_centers_.shape
![]()
#找出质心后,按照已存在的质心对所有数据进行聚类
labels = kmeans.predict(image_array)
labels.shape
![]()
labels #这27w个样本点所对应的簇的质心的索引
![]()
#将数据放到集合中,集合有去重的功能
len(set(labels))
![]()
#簇的质心为kmeans.cluster_centers_,只要对其进行索引,labels当中的任何一个数,labels[]当中任何一个数所对应的质心
#而我们的labels与image_kmeans是一一对应的,可以将其替换
kmeans.cluster_centers_[labels[0]]
![]()
#使用质心来替换所有的样本
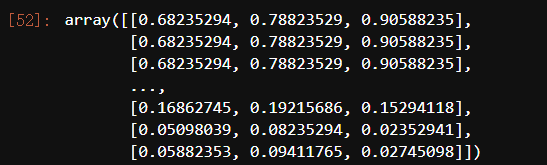
image_kmeans = image_array.copy()
image_kmeans #27w个样本点,9w多种不同的颜色(像素点)
image_kmeans.shape
![]()
for i in range(w*h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans #查看生成的新图片信息
image_kmeans.shape
![]()
pd.DataFrame(image_kmeans).drop_duplicates().shape
![]()
#恢复图片的结构
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shape
![]()
#5. 对数据进行随机的矢量量化
#首先随机抽取的质心,需要64个,shuffle用来打乱image_array的顺序,从中随机抽取64个点做为我们的质心。
centroid_random = shuffle(image_array, random_state=0)[:n_clusters]
#随机选择的样本点
centroid_random.shape
![]()
labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0)
#函数pairwise_distances_argmin(x1,x2,axis) 其中x1和x2分别是序列
#用来计算x2中的每个样本到x1中的每个样本点的距离,并返回和x2相同形状的,x1中对应的最近的样本点的索引。
labels_random.shape
![]()
labels_random
![]()
#去重,查看个数
len(set(labels_random))
![]()
#使用随机质心来替换所有样本
image_random = image_array.copy()
for i in range(w*h):
image_random[i] = centroid_random[labels_random[i]]
![]()
image_random = image_random.reshape(w,h,d)
image_random.shape
![]()
#6. 将原图,按KMeans矢量量化和随机矢量量化的图像绘制出来
plt.figure(figsize=(10,10))
plt.axis(‘off’) #不显示坐标轴
plt.title(‘Original image (96,615 colors)’)
plt.imshow(china)
plt.figure(figsize=(10,10))
plt.axis(‘off’)
plt.title(‘Quantized image (64 colors, K-Means)’)
plt.imshow(image_kmeans)
plt.figure(figsize=(10,10))
plt.axis(‘off’)
plt.title(‘Quantized image (64 colors, Random)’)
plt.imshow(image_random)
plt.show()


