ECCV2022 | 多任务SOTA模型!分割/深度/边界/显著图四项任务
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
后台回复【BEV】即可获取论文!
后台回复【ECCV2022】获取ECCV2022自动驾驶方向所有论文!
后台回复【领域综述】获取自动驾驶感知融合定位近80篇综述论文!
论文标题:Inverted Pyramid Multi-task Transformer for Dense Scene Understanding
1摘要
本文提出了一种新的端到端倒金字塔多任务Transformer算法(InvPT),以在统一的框架中同时对多个空间位置和多任务进行建模。据称,本文是第一篇探索设计用于多任务密集预测以进行场景理解的Transformer算法。此外,更高的空间分辨率已经被证明对密集预测任务有益,而由于大空间尺寸的复杂性,现有基于Transformer的算法搭建更大分辨率的网络是十分具有挑战性的。InvPT 提出了一个高效的 UP-Transformer 模块,以逐渐增加的分辨率学习多任务特征交互,它还结合了高效的自注意力信息传递和多尺度特征聚合,以输出任务特定的高分辨率预测结果。相比于以往单任务的SOTA模型,InvPT在NYUD-v2数据集上取得了2.59%的相对提升,在PASCAL-Context数据集上取得了1.76%的相对提升。

2方法
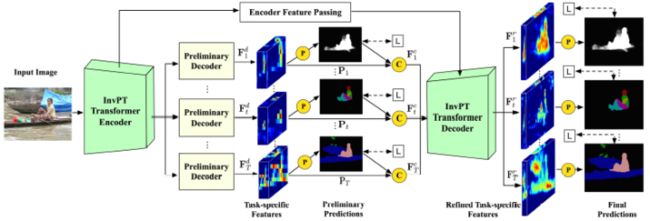
InvPT的整体框架如上图所示,包含三个核心模块:
多任务共享的InvPT Transformer encoder:首先,Transformer encoder从所有任务的输入图像中提取视觉特征,本文尝试使用ViT[14]和Swin Transformer[22]作为特征提取的主干;
任务相关的preliminary decoders:然后,preliminary decoder生成各个特定任务的特征和初步预测,并使用真值监督训练;
InvPT Transformer decoder:最后,每个任务的特定特征和初步预测组合为一个序列,输入至InvPT Transformer decoder中,以学习在全局空间和任务上下文中生成细化的特定任务特征,细化后的特征进一步生成最终的预测结果。
前两点比较好理解,下面着重讲解InvPT Transformer Decoder。
InvPT Transformer Decoder via UP-Transformer Block
当空间分辨率较大时,全局自注意力的计算量就会十分恐怖,因此很多视觉Transformer模型都会大幅降低特征图的分辨率[14,46,44],并输出低空间分辨率的特征。然而特征图的分辨率越大,模型保存的局部细节就会越多,因此分辨率的大小是密集预测问题的一大关键因素。另一点是,不同尺度的特征图可以对不同层次的视觉信息进行建模[42,50],因此对多个任务在多个尺度上互相学习是有益的。出于以上动机,本文设计了一个逐步扩大分辨率的Transformer Decoder,称之为InvPT decoder,其由高效的UP-Transformer 模块、跨尺度自注意力信息传递和多尺度编码器模块组成。
Main Structure:UP-Transformer block的结构如下图所示。InvPT解码器包含三个阶段,每个阶段都是设计的UP-Transformer模块,用来计算不同空间分辨率下的self-attention并更新特征图。InvPT解码器的第一阶段(即阶段0)在 InvPT编码器的输出分辨率(即 H0 × W0)下学习跨任务自注意力,而接下来的两个阶段逐次恢复特征图的空间分辨率,并在更高的分辨率下计算跨任务的自注意力。后两个阶段(即阶段1和阶段2)使用本文提出的 UP-Transformer模块以更高的分辨率细化特征图,并实现跨尺度自注意力的传播,以及来自InvPT Transformer encoder的多尺度特征聚合。

Task-Specific Reshaping and Upsampling:Transformer 的计算模块通常对2D的feature-token序列进行操作,特征度的空间结构被分解,而空间结构对密集任务而言至关重要,基于对空间结构的考量,直接对特征序列进行上采样并非易事。另一个问题是InvPT解码器的输入特征包含多个不同的任务特定特征,所以需要对每个任务分别执行特征上采样和细化,以避免其他任务破坏当前任务的特征。为了解决上述问题,本文为InvPT解码器设计了一个任务特定的reshaping和upsampling模块,即Reshape&UP模块,如上图(b)和下图所示。Reshape&UP模块对每个任务的特征进行单独操作,双线性插值后分辨率扩大两倍,进一步经过Conv-BN-Relu等操作进行特征融合和通道降维,最后再拼接各个任务的特征。
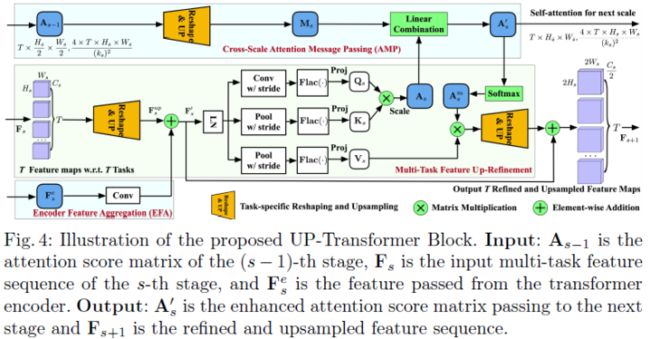
Multi-task UP-Transformer Block:多任务UP-Transformer模块如上图所示,在阶段1和阶段2中使用,并学习逐层增加多任务特征的空间分辨率,并进行特征交互和以全局方式细化所有任务的特征。由于该模块在上采样后的特征图上计算全局自注意力,内存占用会非常大,因此本文首先减小了Q/K/V矩阵的大小,以进行自注意力计算[44,46]。
Cross-Scale Self-Attention Message Passing:为了使 InvPT 解码器能够更有效地对不同尺度的跨任务交互进行建模,本文通过如下方式将上一个阶段的信息传递至当前阶段。

得到当前阶段的注意力图后,再通过Reshape&UP操作进行细化和上采样,进而得到最终的多任务特征,过程如下所示:
Efficient Multi-Scale Encoder Feature Aggregation:对于密集场景理解,一些基本任务(例如边界检测)需要较低级别的视觉特征。但是在Transformer 中有效地使用多尺度特征是很棘手的,因为Transformer在图像分辨率上具有二次计算复杂度,通常只在小分辨率特征图上操作。逐渐增加特征图的大小并结合多尺度特征对GPU内存来说非常具有挑战性。因此,本文设计了一种高效且有效的多尺度编码特征聚合(EFA)策略。结构如上图所示。
3实验结果
实验结果和可视化如下所示,相比于基线,InvPT在多个任务上均有明显的提升,NYUD数据集上整体提升2.59%,在PASCAL上整体提升1.76%。

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
