Swin Transformer
文章目录
- 1.题目和作者
- 2.摘要
- 3.引言
- 4.结论
- 5.模型
-
- 5.1Patch Merging
- 6.基于移动窗口的自注意力
-
- 6.1计算复杂度对比
- 6.2移动窗口
- 7.实验
1.题目和作者
Swin Transformer论文pdf版
Swin Transformer论文网址
Swin Transformer代码
文章标题:Swin Transformer:Hierarchiacl Vision Transformer using Shifted Windows
- Swin Transformer:用了移动窗口的层级式的Vision Transformer
- Swin=Shift(首字母)+Windows(前三个字母)
作者来自Microsoft Research Asia
- MSRA是研究的圣地,经常被誉为研究者的黄埔军校,从里面出来了一众大佬,而且产出了一系列非常有影响力的工作
- 比如大家耳熟能详的ResNet(单篇引用率已经超过10万),也是四位作者都在MSRA的时候完成的工作
2.摘要
这篇论文提出了一个新的Vision Transformer,叫做Swin Transformer。它可以被用来作为一个计算机视觉领域,一个通用的骨干网络。
- 因为Vit在结论中指出,ViT只是做了分类任务,把下游任务比如检测和分割,留给以后的人去探索了,所以说在ViT出来之后,大家虽然看到了Transformer在视觉领域的强大潜力,但是大家并不确定Transformer能不能把所有视觉的任务都做掉
- 所以Swin Transformer这篇论文的研究动机就是想来告诉大家使用Transformer没毛病,绝对能在方方面面上取代卷积神经网络,接下来大家都用Transformer就好了
但是直接把Transformer从NLP用到Vision是有一些挑战的,这个挑战主要来自两个方面,一个是尺度上的问题
- 比如我现在有一张街景的图片,里面有很多车和行人,里面的物体都大大小小的,这时候代表同样一个语义的词,比如说车或者是行人,他就有非常不同的尺寸,那这种现象在NLP就不会出现
另外一个挑战是图像的分辨率太大了
- 如果我们要以像素点作为基本单位的话,这个序列的长度就变得高不可攀,所以之前的工作的解决方案
- 方案一:用后续的特征图作为Transformer的输入
- 方案二:把图片打成patch,减少图片的分辨率
- 方案三:把图片画出一个个小窗口,然后在窗口里去做这个自注意力
- 所有的方案都是为了减少序列程度
- 基于这两个挑战,本篇论文的作者提出了hierachical Transformer
hierarchical Transformer的特征是通过一种移动窗口的方式学来的,移动窗口的好处,不仅带来了更大的效率
- 因为跟之前的工作一样,现在这个自注意力是在窗口内算的,所以这个序列的长度就大大降低了
同时通过shifting移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有cross-window connection,
- 从而变相的达到了一种全局建模的能力
这种层级式结构的好处不仅非常灵活,可以提供各个尺度的特征信息,同时,因为这个自注意力是在小窗口之内计算的,所以计算复杂度是随着图像大小而线性增长的
- 而不是平方级增长
- 这也为作者之后提出的Swin V2铺平了道路,从而让他们可以在特别大的分辨率上去预训练这个模型
- 因为Swin Tranformer 像卷积神经网络一样有分层的结构,有了多尺度的特征,所以就很容易使用到下游的任务里
作者不光是在ImageNet-1K上做了实验,而且达到了非常好的准确度87.3
而且还在密集预测型任务上,比如物体检测,还有物体分割上取得了很好的成绩,比如在COCO上,AP达到了58.7,比之前最好的方法高了2.7个点,在语义分割ADE上,也达到了53.5的效果,比之前最好的方法高了3.2个点
- 这些数据集都是大家常刷的数据集
这种基于Transformer的模型,在视觉领域是非常有潜力的
对于这种MLP架构,用shift window的方法也能提升
3.引言
在视觉领域,卷积神经网络之前是主导地位,但是Transformer在NLP领域使用效果非常好,所以我们将Transformer用到视觉领域来
- 但是因为ViT已经做过这件事情了
- 所以Swin Transformer在第三段的开始,说明研究动机是想证明Transformer是可以用作一个通用的骨干网络,就是对所有视觉任务,不光是分类,在检测、分割视频上也都能取得很好的效果
作者先说了ViT,进行对比,Vision Transformer把图片打成patch
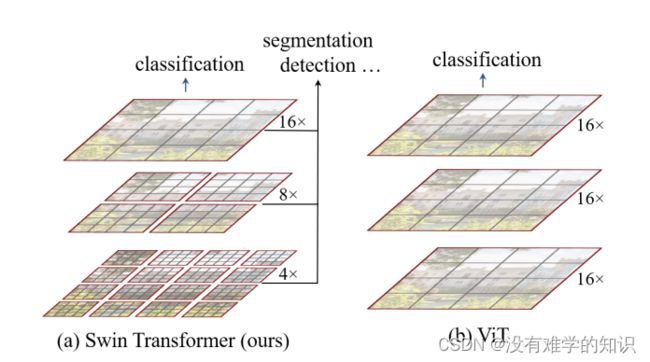
- 因为ViT里用的patch size是16*16的,16×就是16倍的下采样率,这也意味着,这里的每一个patch,自始至终代表的尺寸都是差不多的,它每一层的Transformer block都是16倍的下采样率,虽然它可以通过这种全局的自注意力操作,达到全局的建模能力,但是它对多尺寸特征的把握就会弱一些
- 对于视觉任务,尤其是这些下游任务,比如说检测和分割,多尺寸的特征是至关重要的
- 比如说对目标检测而言,运用最广的一个方法就是FPN(a feature pyramid network),意思就是当有一个分层式的卷积神经网络之后,每一个卷积出来的那些特征,receptive field感受野是不一样的,能抓住物体不同尺度的特征,从而能够很好的处理这个物体不同尺寸的问题
- 对于物体分割任务来说,最常见的就是UNet,UNet为了处理物体不同尺寸,提出了skip connection这个方法,意思就是当一系列下采样做完之后,现在去做上采样,不光是从bottleneck里去拿特征,还从之前每次下采样完之后的东西里面去拿特征,这样就将那些高频率的这些图像细节又全都能恢复出来了
- 当然分割里常用的还有PspNet,还有DeepLab,这些工作里也有相应的处理多尺寸的方法,比如说使用空洞卷积,使用psp和aspp层
- 总之对于计算机视觉的这些下游任务,尤其是这些密集预测型的任务检测、分割,有多尺寸的特征是至关重要的
但是在ViT里,它处理的特征都是单一尺寸的,而且是low resolution
- 也就是说自始至终都是处理的16倍下采样率过后的特征,所以说它可能就不适合处理这种密集预测型的任务
同时对于ViT而言,它的自注意力始终是在最大的窗口上进行了,就是始终是在整图上进行的,所以它是一个全局建模,复杂度也是跟图像的尺寸进行平方倍的增长
- Swin Transformer借鉴了很多卷积神经网络的设计理念,为了减少序列的长度,降低计算复杂度,Swin Transformer采取了小窗口之内的自注意力,而不是像ViT一样在整图上去算自注意力
- 这样只要窗口大小是稳定的,自注意力计算复杂度就是固定的,那整张图的计算复杂度就会跟这张图片的大小而成线性增长关系,就比如这个图片增大了 x x x倍,那窗口数量也就增大了 x x x倍,计算复杂度也是增加了 x x x倍
- 这个其实就是利用了卷积神经网络里的Locality的Inductive bias,利用这个局部性的先验知识,就是说同一个物体的不同部位或者语义相近的不同物体,还是大概率会出现在相连的地方,所以即使是在一个Local,一个小范围的窗口去算这个自注意力也是差不多够用的,全局去算自注意力,对于视觉任务来说其实是有点浪费资源的
- 另外一个挑战,如何去生成这个多尺寸的特征呢
- 卷积神经网络主要是有pooling池化操作,池化这个操作能够增大每一个卷积核能看到的感受野,从而使得每次池化过后的特征,抓住物体的不同尺寸
- 所以类似的Swin Transformer也提出了一个类似池化的操作,叫做patch merging,就是把相邻的小patch合成一个大patch,那这样合并出来的一个大patch,就能看到之前四个小patch看到的内容,感受野就增大了,同时也能抓住多尺寸的特征
Swin Transformer刚开始的下采样率是4倍,然后变成了8倍、16倍
- 一旦有了多尺寸的特征信息,有了4×、8×、16×的特征图,很自然的我们就可以将这些特征图输给一个FPN,从而就可以去做检测了
- 同样的道理,拥有多尺寸的特征图,也可以输给UNET,就可以去做分割了
所以这就是作者反复在论文里强调的,Swin Transformer是能够当做一个通用的骨干网络的,不光是能做这个图像的分类,还能做密集预测性的任务
作者在引言的第四段就开始讲Swin Transformer一个关键的设计,移动窗口的操作
如果在Transformer第L层,把这个输入或者说这个特征图分成这种小窗口的话,那就会有效的降低序列程度,从而减少计算复杂度
每一个灰色小patch就是最基本的元素单元
每一个红色的框是一个中型的计算单元,也就是一个窗口
在Swin Transformer里面每一个小窗口里面默认是有7×7=49个小patch,在这里只是画个示意图,主要来讲解shift操作时怎么完成的
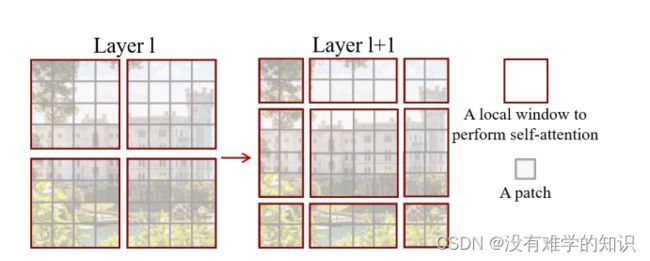
- 假设4个红色窗口组合起来外面是蓝色的窗口,然后将这个蓝色的窗口整体像右下角平移两个,单位,就是先往下平移两个,再往右平移两个
- 如果按照原来的方式,就是没有shift,那么这些窗口之间是不重叠的
- 但是如果每次自注意力的操作都在这个小的窗口内进行了,那这个窗口里的patch,就永远无法注意到其他窗口里的patch信息,这就达不到使用Transformer的初衷了,因为Transformer的初衷就是更好的理解上下文
- 现在我们加上自注意力的操作,比如左边图的第一个红色窗口里的patch,本来只能与该窗口进行联系,而现在变成右边的新红色窗口之后,就可以跟其他窗口里的patch进行交互了
- 再配合上之后提出的patch merging,那合并到这个Transformer最后几层的时候,每一个patch本身的感受野就已经很大了,就已经能看到大部分图片了,然后再加上移动窗口的操作,现在它所谓的这种窗口内的局部注意力,其实也就变相的等于是一个全局的自注意力操作了,这样就是既省内存效果也好,所谓一石二鸟
引言第五段,作者展示了一下实验结果
引言最后一段,作者坚信一个CV和NLP之间大一统的框架是能够促进两个领域共同发展的
4.结论
作者强调了一下Swin Transformer在COCO和ADE20K上的效果非常好,远远超越了之前最好的方法,基于此,希望Swin Transformer能激发出更多更好的工作,尤其是在多模态方面
最关键的贡献是基于Shifted Window的自注意力,这个对很多视觉任务是非常有帮助的
- 但是如果这个Shifted Windows操作不能运用到NLP领域里,其实在模型大一统上这个论据就不是那么强了
所以作者说接下来他们的任务就是要将Shifted Windows用到NLP领域里
5.模型
- 作者就是先讲了卷积神经网络,然后又将自注意力是如何帮助卷积神经网络的,最后就是用Transformer来做骨干网络
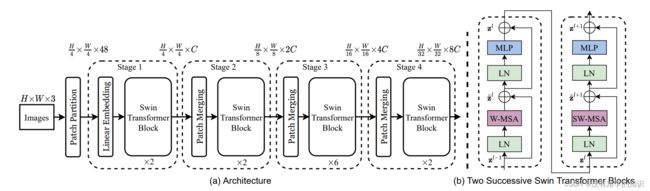
- 假设ImageNet输入图片为224×224×3
- 第一步,将图片经过Patch Partition将图片大小变为56×56×48(224/4=56,4×4×3=18)
- 在该篇论文里,patch size是4×4,而不是像ViT那样16×16
- 接下来将向量的维度变成一个预先设置好的值 C C C,对于Swin Tiny这个网络来说,也就是这个图里画的网络总览图, C C C=96
- 所以经历过Linear Embedding层之后,输入尺寸就变成了56×56×96,前面的56×56会被拉直成序列长度为3136的token,96就是每一个token的维度
- 接下来引入了基于窗口的自注意力(Swin Transformer Block)计算,每个窗口按照默认来说,都只有7×7=49个patch,所以说序列长度就只有49,解决了计算复杂度的问题
- 经过Swin Transformer Block尺寸是不变的
5.1Patch Merging
- 假设我们有一个张量,Patch Merging就是将临近的小patch合并成一个大patch(merging合并)
- 这样就可以起到下采样一个特征图的效果了
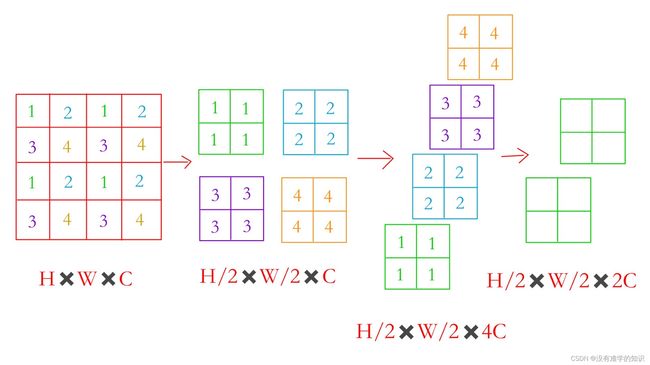
- 因为是下采样两倍,所以就是每隔一个点选一个,原来的一个张量,就会变成4个张量如,如上图,每隔一个点取一个,一开始取数字1,然后取数字2、3、4,这里的数字不是图像的值,而是对应的位置
- 如上图,假设原来张量的维度是 H × W × C H×W×C H×W×C,经过一次采样之后每个张量的大小是 H / 2 、 W / 2 H/2、W/2 H/2、W/2,我们再将4个张量,在 C C C这个维度上拼接起来,就变成了 H / 2 × W / 2 × 4 C H/2×W/2×4C H/2×W/2×4C
- 相当于用空间上的维度去换了更多的通道数,通过这个操作就将原来一个大的张量变小了,就类似于卷积神经网络里池化的操作
- 之后又用1×1的卷积核,将通道维数降下来变成 2 C 2C 2C
- 通过上述操作就能将原来一个大小为 H × W × C H×W×C H×W×C的张量,变成 H / 2 × W / 2 × 2 C H/2×W/2×2C H/2×W/2×2C的张量,空间大小减半,通道数乘2
- 所以再回到一开始的56×56×96,现在经过Patch Merging层,变成了28×28×192
- 经过Swin Transformer Block尺寸是不变的
第三和第四阶段都是同理
先做一个Patch Merging,再通过Swin Transformer Block
进一步降成了14×14×384,再进一步降成了7×7×768

- 将最后的7×7经过global average pooling(全局平均池化),拉直取平均值变成1了,原论文并没有画出来,因为Swin Transformer本义并不是只做分类的,还会去做检测和分割,所以只画了骨干网络的部分,没有去画最后的输出
- 如果最后是做分类,那么7×7×768就变成了1×768
6.基于移动窗口的自注意力
全局自注意力的计算会导致平方倍的复杂度
作者在论文中提到,去做窗口的自注意力机制,原来的图片会被平均分为一些没有重叠的窗口

- 如上图,我们将图像切成一些不重叠的方格,也就是橙黄色的,每一个方格就是一个窗口,并不是最小的计算单元
- 最小的计算单元是之前的patch
- 每个小方格是由7×7=49个patch组成的
- 所有的自注意力计算都是在这个7×7的小窗口里面完成的,所以序列长度永远都是49个
- 原来大的整体特征图的窗口数,每边是56/7=8,也就是8×8=64个窗口
- 所以我们会在64个窗口里分别去算自注意力
6.1计算复杂度对比
多头自注意力:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C \Omega(MSA)=4hwC^2+2(hw)^2C Ω(MSA)=4hwC2+2(hw)2C
基于窗口自注意力:
Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C \Omega(W-MSA)=4hwC^2+2M^2hwC Ω(W−MSA)=4hwC2+2M2hwC
其中, M M M就是窗口的长度,也就是上述的7
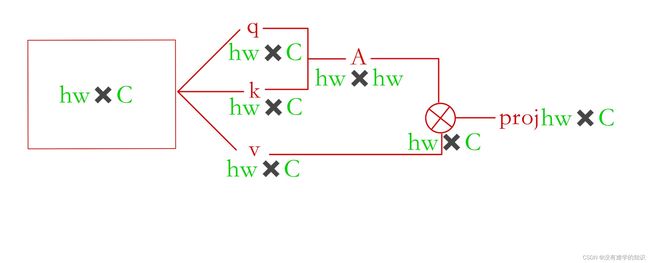
- 先推导标准的多头自注意力:
- 如上图,比如现在有一个输入,自注意力会先将输入复制成3个向量,分别为 q 、 k 、 v q、k、v q、k、v,具体每个值是什么意思可以参考文章Transformer,也就是原来的输入,分别乘了三个系数矩阵
- 一旦得到query和key之后,就将两者相乘得到自注意力的矩阵,有了自注意力矩阵之后,再与value相乘,因为是多头自注意力,所以最后还有一个projection layer投射层,这个投射层就会把向量的维度投射到我们想要的那个维度
- h w × C hw×C hw×C乘三个 C × C C×C C×C的系数矩阵得到三个 h w × C hw×C hw×C的矩阵,计算复杂度为 3 h w C 2 3hwC^2 3hwC2
- q 的 h w × C q的hw×C q的hw×C× k 的 h w × C k的hw×C k的hw×C= h w × h w hw×hw hw×hw,计算复杂度为 ( h w ) 2 C (hw)^2C (hw)2C
- 自注意力矩阵 h w × h w hw×hw hw×hw,与 v 的 h w × C v的hw×C v的hw×C相乘,计算复杂度也为 ( h w ) 2 C (hw)^2C (hw)2C
- 最后投射层也就是 h w × C hw×C hw×C乘 C × C C×C C×C变成了 h w × C hw×C hw×C,计算复杂度为 h w C 2 hwC^2 hwC2
- 再推导基于窗口的自注意力:
- 同样是参考上图,也可以直接套用多头自注意力公式,只是 h 、 w 、 C h、w、C h、w、C发生了变化, h 、 w h、w h、w变成了 m 、 m m、m m、m,即每个窗口的长和宽
- 所以公式代入之后,就变成了 4 w 2 C 2 + 2 M 4 C 4w^2C^2+2M^4C 4w2C2+2M4C,这个公式是在一个窗口里算多头自注意力
- 那么我们的窗口数是 h m × w m \frac h m × \frac w m mh×mw个,再乘上式等于 4 h w C 2 + 2 M 2 h w C 4hwC^2+2M^2hwC 4hwC2+2M2hwC
6.2移动窗口
虽然解决了计算复杂度的问题,但是窗口和窗口之间没有了通信,这样就达不到全局建模了,于是就提出了移动窗口的方式
每次都要先做基于窗口的多头自注意力(W-MSA),再做一次基于移动窗口的多头自注意力(SW-MSA),这样就达到了窗口和窗口之间的互相通信

- 这也是为什么Swin Transformer Block总是偶数,因为总需要上面两块连在一起
原来特征图上只有四个窗口,现在移动之后,变成了9个窗口
窗口数量增加了,窗口里每个元素大小也不一样

作者先引入cyclic shift(循环位移)操作

- 在得到9个窗口之后,进行cyclic shift(循环位移)操作
- 将上图的A、B、C移动到下面
- 在新的图像上将得到新的四宫格,移动之前和移动之后都是4个窗口,所以计算复杂度是不变的
但是新得到的四宫格里面的A、B、C是不一样跟灰色的做自注意力计算的,因为他们是从很远的地方人为移动过来的,所以并没有什么联系,
于是作者采用了掩码的方式
掩码操作之后,再采用一次循环位移,将A、B、C再还原回去,保持原来图片的相对位置是不变的,整体图片的语义信息也是不变的

-
如上图,每个窗口是7×7=49个patch,每个patch就是一个向量,再将窗口拉直
-
因为每次移位是窗口的一半,这里的窗口是7,也就是移动3
-
所以就有7×4=28个3号位元素,7×3=21个6号位元素
-
行就是向量的维度 C C C
-
将左边矩阵转置,相乘,左边矩阵第一行与右边矩阵第一列相乘,以此类推
-
作者设置了掩码的模板矩阵,将需要计算的矩阵设置为0,不需要的设置为负很大的数
-
将模板矩阵与相乘得到的矩阵进行相加,不需要的模块就会变成非常小的数,再经过 s o f t m a x softmax softmax操作之后就变成0了

-
同理,其他模块也是一样的操作,进行矩阵相乘,结果如上图
7.实验
做了两个预训练
一个是在ImageNet-1K上做预训练
一个是在ImageNet-22K上做预训练
测试都是在ImageNet-1K的测试集上去做的