让阿宅不再寂寞的聊天机器人
阿宅爱上了阿美
在一个有星星的夜晚
飞机从头顶飞过
流星也划破那夜空
虽然说人生并没有什么意义
但是爱情确实让生活更加美丽
阿美嫁给了二富
在一个有香槟的晴天
豪车从眼前驶过
车笛也震动那烈阳
虽然说爱情让生活变得美丽
但是失去确实让人生更加无趣
技术员阿宅失恋了,他最爱的阿美离开了他,夜深人静的晚上,看着和阿美那十几G的聊天记录,他哭了,眼泪在伴随的聊天记录的下滑也簌簌的落下,他从没想过眼泪的味道,是苦的!
阿宅苦笑了起来,打开了网易云,越来越收不住。突然他暴跳了起来,怒目圆瞪,歇斯底里的锤着眼前的空气,“不可能!不可能!”阿宅大喊到:”谁也别想抢走你, 不可能!不可能!我是不会让你离开的!你只能活着有我的世界里!只有我的世界!!“ 阿宅疯似的跑进房间,急躁的打开了电脑。。。。。。
他打开文档:恶狠狠的敲下这几个大字
智能阿美文字聊天机器人系统!!!
为了还原阿美那灵动和活泼的口语,阿宅决定使用 seq2seq +attention 的深度学习架构的NLP的聊天系统。
架构层面梳理:
(代码github地址):
GitHub - Boris-2021/ChatBot-seq2seq_attention: A NLP apply, base on seq2seq and attention.A NLP apply, base on seq2seq and attention. Contribute to Boris-2021/ChatBot-seq2seq_attention development by creating an account on GitHub. https://github.com/Boris-2021/ChatBot-seq2seq_attention
https://github.com/Boris-2021/ChatBot-seq2seq_attention
神经网络架构:
| seq2seq | Encoder层面: 双向GRU(内部5层网络)的架构 |
| Decoder层面: 单向GRU(内部3层)的架构 | |
| attention | Bahdanau attention 架构 |
| Luong attention 架构 |
解释:GRU是rnn(lstm)的变体(由lstm的三个门变成了两个门),BI-GRU是个双向GRU会联系上下文。这里Ecoder选择5层。Decoder(3GRU) : 默认的3层,单向的GRU。
Attention机制是现在深度神经网络流行的一种方式,从本质上说attention重点在于在encoder 和decoder之间的C中间序列中加了softmax.也可以理解为一种数据降维,将要集中的特征的地方调高相应的参数,在NLP领域有着广泛的应用。
项目流程架构:
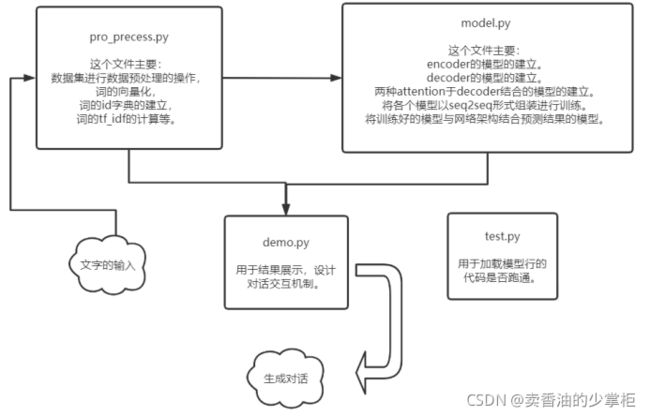
Model.py:seq2seq的模型,也就是encode,decode的部分。Attention架构,计算loss,
BLEU,各种loss,评价指标在这里实现。
Preproce.py:数据预处理,正则匹配,分词,tf-idf词频。
train.py:载入数据,调用模型,训练,设置超参数。保存模型。
test.py:测试模块
Demo.py:展示。
代码层面设计梳理:
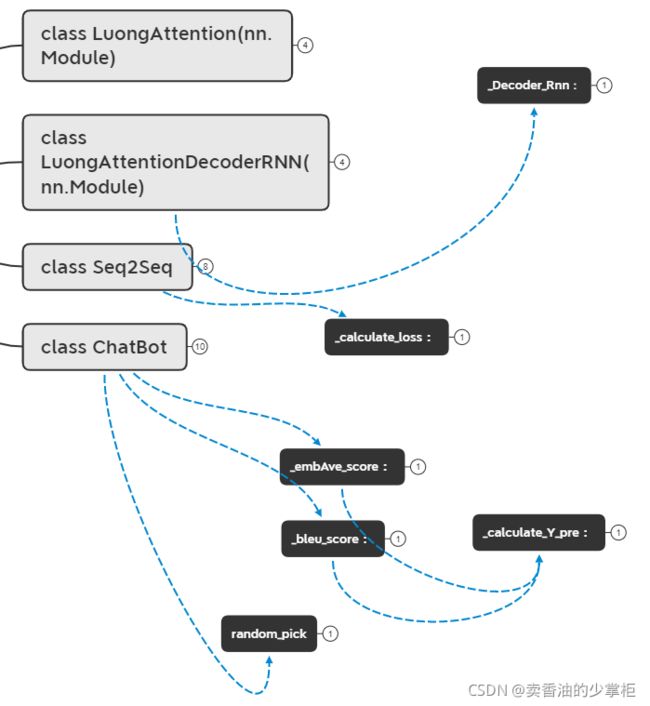
这里主要说明建立的类的作用,和类中方法的作用目的:
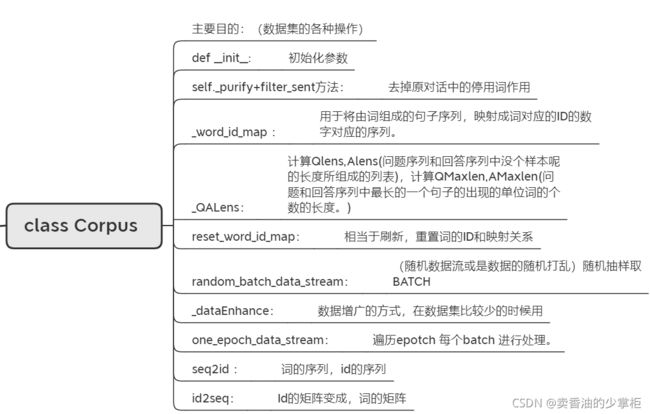





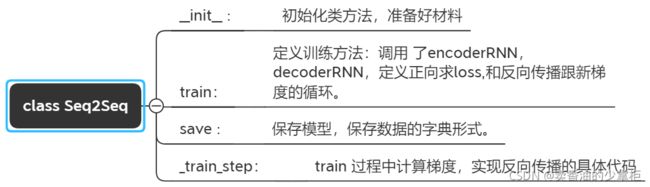

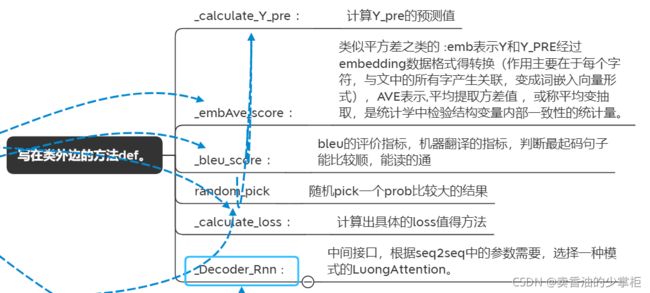
方法之间的调用关系:
xmind 已上传github,可以下载下来看
代码分析和相关技术点讲解:
语料内容:
在data文件夹中:qingyun.tsv

数据预处理初始化pre_process.py:
核心API:
| jieba | jieba.lcut()返回的列表 |
| jieba.cut()放回迭代对象 | |
| sklearn | train_test_split划分训练测试数据 |
创建数据集类 class Corpus(所有数据集操作都在类里):
#定义语料的类
class Corpus:
#初始化
def __init__(self, filePath, maxSentenceWordsNum=-1, id2word=None, word2id=None, wordNum=None, tfidf=False, QIDF=None, AIDF=None, testSize=0.2, isCharVec=False):
# testsize:取百分之20做测试
self.id2word, self.word2id, self.wordNum = id2word, word2id, wordNum
#遍历所有内容 #对预料所有进行操作
with open(filePath,'r',encoding='utf8') as f:
txt = self._purify(f.readlines())
data = [i.split('\t') for i in txt]补充self._purify方法:
def _purify(self, txt):
return [filter_sent(qa) for qa in txt]补充filter_sent()方法:
#去掉一些停用词
def filter_sent(sent):
return sent.replace('\n','').replace(' ','').replace(',',',').replace('。','.').replace(';',';').replace(':',':').replace('?','?').replace('!','!').replace('“','"').replace('”','"').replace("‘","'").replace("’","'").replace('(','(').replace(')',')')处理后的数据效果如图:

与原始数据对比:

#判断是否是英文字符,不是英文的话,中文要用使用jieba进行分词
if isCharVec:
data = [[[c for c in i[0]], [c for c in i[1]]] for i in data]
else:
data = [[jieba.lcut(i[0]), jieba.lcut(i[1])] for i in data]
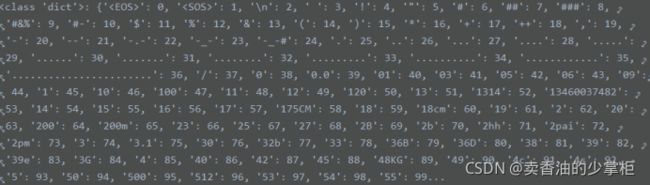
data = [i for i in data if (len(i[0])补充_word_id_map方法:
def _word_id_map(data, wordNum=None, word2id=None, id2word=None):
if id2word==None:
id2word = list(set([w for qa in data for sent in qa for w in sent]))
id2word.sort()
id2word = ['',''] + id2word + ['']
if word2id==None: word2id = {i[1]:i[0] for i in enumerate(id2word)}
if wordNum==None: wordNum = len(id2word)
print('Total words num:',len(id2word)-2) word2id 的效果:
try:
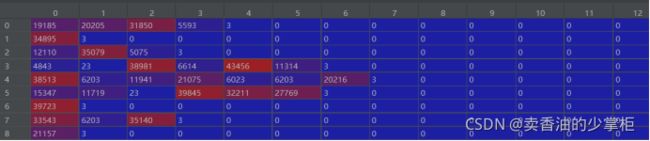
chatDataId = [[[self.word2id[w] for w in qa[0]],[self.word2id[w] for w in qa[1]]] for qa in self.chatDataWord]
except:
chatDataId = [[[self.word2id[w] for w in qa[0] if w in self.id2word],[self.word2id[w] for w in qa[1] if w in self.id2word]] for qa in self.chatDataWord]这句的作用是:将data原本一个一个的词,变成world2id中字典中数字的编号。如图:
![]()
变成:
![]()
self._QALens(chatDataId)
self.maxSentLen = max(maxSentenceWordsNum, self.AMaxLen)
self.QChatDataId, self.AChatDataId = [qa[0] for qa in chatDataId], [qa[1] for qa in chatDataId]
self.totalSampleNum = len(data)上边代码作用:转换成:question和answer的id列表。
补充_QALens方法:
def _QALens(self, data):
QLens, ALens = [len(qa[0])+1 for qa in data], [len(qa[1])+1 for qa in data]
QMaxLen, AMaxLen = max(QLens), max(ALens)
print('QMAXLEN:',QMaxLen,' AMAXLEN:',AMaxLen)
self.QLens, self.ALens = np.array(QLens, dtype='int32'), np.array(ALens, dtype='int32')
self.QMaxLen, self.AMaxLen = QMaxLen, AMaxLen作用:返回问答对话长度
if tfidf:
self.QIDF = QIDF if QIDF is not None else np.array([np.log(self.totalSampleNum/(sum([(i in qa[0]) for qa in chatDataId])+1)) for i in range(self.wordNum)], dtype='float32')
self.AIDF = AIDF if AIDF is not None else np.array([np.log(self.totalSampleNum/(sum([(i in qa[1]) for qa in chatDataId])+1)) for i in range(self.wordNum)], dtype='float32')
print("Total sample num:",self.totalSampleNum)
#划分训练和测试数据集
self.trainIdList, self.testIdList = train_test_split([i for i in range(self.totalSampleNum)], test_size=testSize)
self.trainSampleNum, self.testSampleNum = len(self.trainIdList), len(self.testIdList)
print("train size: %d; test size: %d"%(self.trainSampleNum, self.testSampleNum))
self.testSize = testSize
print("Finished loading corpus!")计算tf_idf:
关于tfidf的知识点:TF-IDF的定义及计算_Haward-CSDN博客_tfidf计算 https://blog.csdn.net/hao5335156/article/details/87835851
https://blog.csdn.net/hao5335156/article/details/87835851
TF-IDF算法详解:
TF-IDF算法详解_Miracle.Zhao的博客-CSDN博客_tf-idfhttps://blog.csdn.net/zhaomengszu/article/details/81452907?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1.opensearchhbase&spm=1001.2101.3001.4242.2
衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
最总输出的各项指标:
Total words num: 44908
QMAXLEN: 25 AMAXLEN: 25
Total sample num: 104912
train size: 83929; test size: 20983
Finished loading corpus!
至此完成数据预处理类中初始化方法步骤。
其他方法的补充说明:
#重置词的ID和映射关系
def reset_word_id_map(self, id2word, word2id):
self.id2word, self.word2id = id2word, word2id
chatDataId = [[[self.word2id[w] for w in qa[0]],[self.word2id[w] for w in qa[1]]] for qa in self.chatDataWord]
self.QChatDataId, self.AChatDataId = [qa[0] for qa in chatDataId], [qa[1] for qa in chatDataId]相当于刷新
添加其他方法(随机数据流或是数据的随机打乱)随机抽样取BATCH:
# 随机数据流
def random_batch_data_stream(self, batchSize=128, isDataEnhance=False, dataEnhanceRatio=0.2, type='train'):
# isDataEnhance :是否进行数据增广,dataEnhanceRatio 数据增广率,type代表只在训练中数据增广。
#判断数据是不是训练数据,另外给定结束符
idList = self.trainIdList if type=='train' else self.testIdList
eosToken, unkToken = self.word2id[''], self.word2id['']
# 结束符 未知符
while True:
# 打乱的操作 random.sample随机抽样
samples = random.sample(idList, min(batchSize, len(idList))) if batchSize>0 else random.sample(idList, len(idList))
#数据增广
if isDataEnhance:
yield self._dataEnhance(samples, dataEnhanceRatio, eosToken, unkToken) 补充yield和return的区别
深入理解yield以及和return的区别 - 南哥的天下 - 博客园https://www.cnblogs.com/leijiangtao/p/4806683.html
相同点:都是返回函数执行的结果
不同点:return 在返回结果后结束函数的运行,而yield 则是让函数变成一个生成器,生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
补充_dataEnhance方法:
#数据增广的方式
def _dataEnhance(self, samples, ratio, eosToken, unkToken):
#计算tf_idf
q_tf_idf = [[self.QIDF[w]*self.QChatDataId[i].count(w)/(self.QLens[i]-1) for w in self.QChatDataId[i]] for i in samples]
q_tf_idf = [[j/sum(i) for j in i] for i in q_tf_idf]
QDataId = [[w for cntw,w in enumerate(self.QChatDataId[i]) if random.random()>ratio or random.random()ratio/5 else unkToken for w in self.QChatDataId[i]] for i in samples]
ADataId = [self.AChatDataId[i] for i in samples]
#然后遍历取其中的一些ID
for i in range(len(samples)):
if random.random()1) & (ALens>1)
return QDataId[validId], QLens[validId], ADataId[validId], ALens[validId] 在预料集比较少的时候起到增加数据的作用。
else:
QMaxLen, AMaxLen = max(self.QLens[samples]), max(self.ALens[samples])
QDataId = np.array([self.QChatDataId[i]+[eosToken for j in range(QMaxLen-self.QLens[i]+1)] for i in samples], dtype='int32')
ADataId = np.array([self.AChatDataId[i]+[eosToken for j in range(AMaxLen-self.ALens[i]+1)] for i in samples], dtype='int32')
yield QDataId, self.QLens[samples], ADataId, self.ALens[samples] QdataId 变成shape(len(samples), Qmaxlen ) ,抽样个数行,该样本中最单词最多的对话的行中的列数,不足长度的Q对话,用
# 确定一个epoch数据流 确认数据是训练数据
def one_epoch_data_stream(self, batchSize=128, isDataEnhance=False, dataEnhanceRatio=0.2, type='train'):
# isDataEnhance :是否进行数据增广,dataEnhanceRatio 数据增广率,type代表只在训练中数据增广。
# 判断数据是不是训练数据据,另外给定结束符。
idList = self.trainIdList if type=='train' else self.testIdList
eosToken = self.word2id['']
for i in range((len(idList)+batchSize-1)//batchSize):
samples = idList[i*batchSize:(i+1)*batchSize]
# 数据增广
if isDataEnhance:
yield self._dataEnhance(samples, dataEnhanceRatio, eosToken, unkToken=None)
else:
QMaxLen, AMaxLen = max(self.QLens[samples]), max(self.ALens[samples])
QDataId = np.array([self.QChatDataId[i]+[eosToken for j in range(QMaxLen-self.QLens[i]+1)] for i in samples], dtype='int32')
ADataId = np.array([self.AChatDataId[i]+[eosToken for j in range(AMaxLen-self.ALens[i]+1)] for i in samples], dtype='int32')
yield QDataId, self.QLens[samples], ADataId, self.ALens[samples] 遍历epotch 每个batch 进行处理。
def seq2id(word2id, seqData):
seqId = [word2id[w] for w in seqData]
return seqId词的序列变成,id的序列。
def id2seq(id2word, seqId):
seqData = [id2word[i] for i in seqId]
return seqData模型建立阶段model.py:
核心API:
| torch.nn | nn.GRU |
| nn.utils.rnn.pack_padded_sequence | |
| nn.linear | |
| nn.Dropuout | |
| NLTK | sentence_bleu 评价指标 |
讲解:nn.gru: 主要是定义什么样的网络,类似于lstm但是计算比lstm简洁。
pack_padded_sequence API 的解释:torch.nn.GRU()函数解读_wang xiang的博客-CSDN博客https://blog.csdn.net/qq_40178291/article/details/100659208
Pytorch中的RNN之pack_padded_sequence()和pad_packed_sequence() - sbj123456789 - 博客园https://www.cnblogs.com/sbj123456789/p/9834018.html
lstm pytorch梳理之 batch_first 参数 和torch.nn.utils.rnn.pack_padded_sequence - 打了鸡血的女汉子 - 博客园小萌新在看pytorch官网 LSTM代码时 对batch_first 参数 和torch.nn.utils.rnn.pack_padded_sequence 不太理解, 在回去苦学了一番 ,将自己消https://www.cnblogs.com/yuqinyuqin/p/14100967.html
通俗讲解pytorch中nn.Embedding原理及使用:
通俗讲解pytorch中nn.Embedding原理及使用 - 简书函数调用形式 其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系...https://www.jianshu.com/p/63e7acc5e890
创建encoder类 class EncoderRNN
#定义Encoder
class EncoderRNN(nn.Module):
#初始化
def __init__(self, featureSize, hiddenSize, embedding, numLayers=1, dropout=0.1, bidirectional=True):
'''
:param featureSize: 特征大小
:param hiddenSize: GRU, lstm 隐层大小
:param embedding:Embedding就是从原始数据提取出来的Feature,也就是那个通过神经网络映射之后的低维向量。
:param numLayers:
:param dropout:防止过拟合
:param bidirectional:BI双向GRU
'''
super(EncoderRNN, self).__init__()
self.embedding = embedding
#核心API,建立双向GRU
self.gru = nn.GRU(featureSize, hiddenSize, num_layers=numLayers, dropout=(0 if numLayers==1 else dropout), bidirectional=bidirectional, batch_first=True)
#超参
self.featureSize = featureSize
self.hiddenSize = hiddenSize
self.numLayers = numLayers
self.bidirectional = bidirectional补充后边对embed ing来源的定义:
embedding = embedding if embedding else nn.Embedding(outputSize+1, featureSize)找到来源了在seq2seq类中的init中。
#前向计算,训练和测试必须的部分
def forward(self, input, lengths, hidden):
# input: batchSize × seq_len; hidden: numLayers*d × batchSize × hiddenSize
#给定输入
input = self.embedding(input) # => batchSize × seq_len × feaSize
#加入paddle 方便计算
packed = nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=True)
output, hn = self.gru(packed, hidden) # output: batchSize × seq_len × hiddenSize*d; hn: numLayers*d × batchSize × hiddenSize
output, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
#确定是否是双向GRU
if self.bidirectional:
output = output[:,:,:self.hiddenSize] + output[:,:,self.hiddenSize:]
return output, hn定义encoder前向计算的过程:。。
补充知识点:
nn.utils.rnn.pack_padded_sequence===>output==>nn.utils.rnn.pad_packed_sequence的变换。
nn.utils.rnn.pack_padded_sequence()操作:
pack之后,原来填充的 PAD(一般初始化为0)占位符被删掉了。
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
NOTE: 只要是维度大于等于2的input都可以作为这个函数的参数。你可以用它来打包labels,然后用RNN的输出和打包后的labels来计算loss。通过PackedSequence对象的.data属性可以获取 Variable。
torch.nn.utils.rnn.pad_packed_sequence()操作:
填充packed_sequence。
上面提到的函数的功能是将一个填充后的变长序列压紧。 这个操作和pack_padded_sequence()是相反的。把压紧的序列再填充回来。填充时会初始化为0。
返回的Varaible的值的size是 T×B×*, T 是最长序列的长度,B 是 batch_size,如果 batch_first=True,那么返回值是B×T×*。
Batch中的元素将会以它们长度的逆序排列。
创建decoderGRU class DecoderRNN 类:
#定义Decoder
class DecoderRNN(nn.Module):
#初始化
def __init__(self, featureSize, hiddenSize, outputSize, embedding, numLayers=1, dropout=0.1):
super(DecoderRNN, self).__init__()
self.embedding = embedding
#核心API
self.gru = nn.GRU(featureSize, hiddenSize, num_layers=numLayers, batch_first=True)
self.out = nn.Linear(featureSize, outputSize)这里用单向GRU,结构也就比较简单,gru输出后通过linear层输出结果。
#定义前向计算
def forward(self, input, hidden):
# input: batchSize × seq_len; hidden: numLayers*d × batchSize × hiddenSize
input = self.embedding(input) # => batchSize × seq_len × feaSize
#relu激活,softmax计算输出
input = F.relu(input)
output,hn = self.gru(input, hidden) # output: batchSize × seq_len × feaSize; hn: numLayers*d × batchSize × hiddenSize
output = F.log_softmax(self.out(output), dim=2) # output: batchSize × seq_len × outputSize
return output,hn,torch.zeros([input.size(0), 1, input.size(1)])定义前向传播,LogSoftmax其实就是对softmax的结果进行log,即Log(Softmax(x))
Bahdanau attention机制的decoder class BahdanauAttentionDecoderRNN 类:
BahdanauAttention与LuongAttention注意力机制简介_u010960155的博客-CSDN博客在使用tensorflow时发现其提供了两种Attention Mechanisms(注意力机制),如下The two basic attention mechanisms are:tf.contrib.seq2seq.BahdanauAttention (additive attention, ref.)tf.contrib.seq2seq.LuongAttention (multi...https://blog.csdn.net/u010960155/article/details/82853632
#定义 BahdanauAttention的Decoder
class BahdanauAttentionDecoderRNN(nn.Module):
#初始化
def __init__(self, featureSize, hiddenSize, outputSize, embedding, numLayers=1, dropout=0.1):
super(BahdanauAttentionDecoderRNN, self).__init__()
self.embedding = embedding
#定义attention的权重还有如何联合,及dropout,防止过拟合
self.dropout = nn.Dropout(dropout)
self.attention_weight = nn.Linear(hiddenSize*2, 1)
# 定义如何进行链接
self.attention_combine = nn.Linear(featureSize+hiddenSize, featureSize)
#核心API 搭建GRU层,并给定超参
self.gru = nn.GRU(featureSize, hiddenSize, num_layers=numLayers, dropout=(0 if numLayers==1 else dropout), batch_first=True)
self.out = nn.Linear(hiddenSize, outputSize)
self.numLayers = numLayers#定义前向计算
def forward(self, inputStep, hidden, encoderOutput):
#input做了dropout的操作,主要是防止过拟合
inputStep = self.embedding(inputStep) # => batchSize × 1 × feaSize
inputStep = self.dropout(inputStep)
#计算attention的权重部分,attention的本质是softmax
attentionWeight = F.softmax(self.attention_weight(torch.cat((encoderOutput, hidden[-1:].expand(encoderOutput.size(1),-1,-1).transpose(0,1)), dim=2)).transpose(1,2), dim=2)
context = torch.bmm(attentionWeight, encoderOutput) # context: batchSize × 1 × hiddenSize
attentionCombine = self.attention_combine(torch.cat((inputStep, context), dim=2)) # attentionCombine: batchSize × 1 × feaSize
attentionInput = F.relu(attentionCombine) # attentionInput: batchSize × 1 × feaSize
output, hidden = self.gru(attentionInput, hidden) # output: batchSize × 1 × hiddenSize; hidden: numLayers × batchSize × hiddenSize
output = F.log_softmax(self.out(output), dim=2) # output: batchSize × 1 × outputSize
return output, hidden, attentionWeight定义前向计算
定义luongAttention class LuongAttention + class LuongAttentionDecoderRNN 类:
#定义LuongAttention
class LuongAttention(nn.Module):
#初始化
def __init__(self, method, hiddenSize):
super(LuongAttention, self).__init__()
self.method = method
#三种模式,dot,general,concat
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
if self.method == 'general':
self.Wa = nn.Linear(hiddenSize, hiddenSize)
elif self.method == 'concat':
self.Wa = nn.Linear(hiddenSize*2, hiddenSize)
self.v = nn.Parameter(torch.FloatTensor(1, hiddenSize)) # self.v: 1 × hiddenSize补充知识点:luongAttention有三种模式【dot,general,conca区别在论文中查找】

知乎的解释:

#给出dot计算方法
def dot_score(self, hidden, encoderOutput):
return torch.sum(hidden*encoderOutput, dim=2)
# 给出general计算方法
def general_score(self, hidden, encoderOutput):
energy = self.Wa(encoderOutput) # energy: batchSize × seq_len × hiddenSize
return torch.sum(hidden*energy, dim=2)
# 给出gconcat计算方法
def concat_score(self, hidden, encoderOutput):
# hidden: batchSize × 1 × hiddenSize; encoderOutput: batchSize × seq_len × hiddenSize
energy = torch.tanh(self.Wa(torch.cat((hidden.expand(-1, encoderOutput.size(1), -1), encoderOutput), dim=2))) # energy: batchSize × seq_len × hiddenSize
return torch.sum(self.v*energy, dim=2)给出三种模式的计算方法。
# 定义前向计算
def forward(self, hidden, encoderOutput):
#确定使用哪种计算方式,3选1
if self.method == 'general':
attentionScore = self.general_score(hidden, encoderOutput)
elif self.method == 'concat':
attentionScore = self.concat_score(hidden, encoderOutput)
elif self.method == 'dot':
attentionScore = self.dot_score(hidden, encoderOutput)
# attentionScore: batchSize × seq_len
return F.softmax(attentionScore, dim=1).unsqueeze(1) # => batchSize × 1 × seq_len定义向前计算
补充Luongattention的架构图(来自论文):
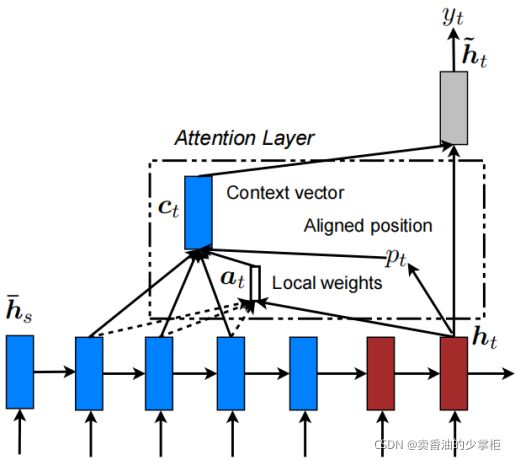
最终 定义luongattention decoder:
# 定义LuongAttentionDecoder
class LuongAttentionDecoderRNN(nn.Module):
#初始化
def __init__(self, featureSize, hiddenSize, outputSize, embedding, numLayers=1, dropout=0.1, attnMethod='dot'):
super(LuongAttentionDecoderRNN, self).__init__()
#对输入进行dropout
self.embedding = embedding
self.dropout = nn.Dropout(dropout)
#核心api,搭建GRU
self.gru = nn.GRU(featureSize, hiddenSize, num_layers=numLayers, dropout=(0 if numLayers==1 else dropout), batch_first=True)
#定义权重计算和联合方式
self.attention_weight = LuongAttention(attnMethod, hiddenSize)
self.attention_combine = nn.Linear(hiddenSize*2, hiddenSize)
self.out = nn.Linear(hiddenSize, outputSize)
self.numLayers = numLayers
# 定义前向计算
def forward(self, inputStep, hidden, encoderOutput):
# inputStep: batchSize × 1; hidden: numLayers × batchSize × hiddenSize
#对输入做dropout
inputStep = self.embedding(inputStep) # => batchSize × 1 × feaSize
inputStep = self.dropout(inputStep)
output, hidden = self.gru(inputStep, hidden) # output: batchSize × 1 × hiddenSize; hidden: numLayers × batchSize × hiddenSize
attentionWeight = self.attention_weight(output, encoderOutput) # batchSize × 1 × seq_len
# encoderOutput: batchSize × seq_len × hiddenSize
context = torch.bmm(attentionWeight, encoderOutput) # context: batchSize × 1 × hiddenSize
attentionCombine = self.attention_combine(torch.cat((output, context), dim=2)) # attentionCombine: batchSize × 1 × hiddenSize
attentionOutput = torch.tanh(attentionCombine) # attentionOutput: batchSize × 1 × hiddenSize
output = F.log_softmax(self.out(attentionOutput), dim=2) # output: batchSize × 1 × outputSize
return output, hidden, attentionWeight父类继承luongattention类,基本和B decoder 差不多,encoder和decoder间连接方式有所不同。
# 如何去选择decoder L or B or DecodeRnn
#定义Decoder
def _DecoderRNN(attnType, featureSize, hiddenSize, outputSize, embedding, numLayers, dropout, attnMethod):
'''
:param attnType: 选择L or B这两种decoder
:param featureSize:特征的维度
:param hiddenSize:隐层的大小
:param outputSize:输出得大小
:param embedding:embedding
:param numLayers:内部几层
:param dropout:正则去除过拟合
:param attnMethod:dot,general,concat
:return:
'''
#使用哪种attention
if attnType not in ['L', 'B', None]:
raise ValueError(attnType, "is not an appropriate attention type.")
if attnType == 'L':
return LuongAttentionDecoderRNN(featureSize, hiddenSize, outputSize, embedding=embedding, numLayers=numLayers, dropout=dropout, attnMethod=attnMethod)
elif attnType == 'B':
return BahdanauAttentionDecoderRNN(featureSize, hiddenSize, outputSize, embedding=embedding, numLayers=numLayers, dropout=dropout)
else:
return DecoderRNN(featureSize, hiddenSize, outputSize, embedding=embedding, numLayers=numLayers, dropout=dropout)这个方法定义了选择那种模式的luongattention。
定义seq2seq class Seq2Seq 类:
class Seq2Seq:
#初始化
def __init__(self, dataClass, featureSize, hiddenSize, encoderNumLayers=1, decoderNumLayers=1, attnType='L', attnMethod='dot', dropout=0.1, encoderBidirectional=False, outputSize=None, embedding=None, device=torch.device("cpu")):
# dataclass 是数据
outputSize = outputSize if outputSize else dataClass.wordNum
# 对话的长度,数据的长度。
embedding = embedding if embedding else nn.Embedding(outputSize+1, featureSize)
#数据读入
self.dataClass = dataClass
#搭建模型架构的内容。
self.featureSize, self.hiddenSize = featureSize, hiddenSize
# 准备encoder 调用构建
self.encoderRNN = EncoderRNN(featureSize, hiddenSize, embedding=embedding, numLayers=encoderNumLayers, dropout=dropout, bidirectional=encoderBidirectional).to(device)
# 准备decoder 调用构建
self.decoderRNN = _DecoderRNN(attnType, featureSize, hiddenSize, outputSize, embedding=embedding, numLayers=decoderNumLayers, dropout=dropout, attnMethod=attnMethod).to(device)
self.embedding = embedding.to(device)
self.device = device这里写的是encoder和decoder的过程,所需要的材料的准备阶段。
#定义训练方法
def train(self, batchSize, isDataEnhance=False, dataEnhanceRatio=0.2, epoch=100, stopRound=10, lr=0.001, betas=(0.9, 0.99), eps=1e-08, weight_decay=0, teacherForcingRatio=0.5):
# 使用那个api训练
self.encoderRNN.train(), self.decoderRNN.train()定义训练流程。
补充知识点:self.encoderRNN.train(), self.decoderRNN.train()这两个API使用的pythorcn中model.train()的作用
源码中的解释:
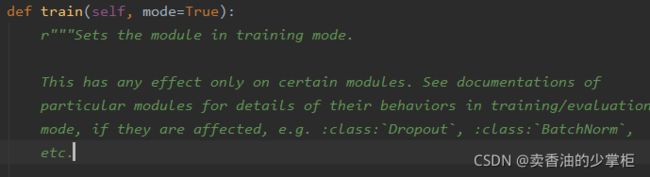
表示在有Batchnorm 和Dropout是的前向计算中指定当前模型是在训练还是验证。
#给定batchSize 和 是否数据增广isDataEnhance
batchSize = min(batchSize, self.dataClass.trainSampleNum) if batchSize>0 else self.dataClass.trainSampleNum
dataStream = self.dataClass.random_batch_data_stream(batchSize=batchSize, isDataEnhance=isDataEnhance, dataEnhanceRatio=dataEnhanceRatio)
#定义优化器,使用adam
# 对于测试数据batch制作。testsize默认0.2 ,即为0.2比例的测试数据。
if self.dataClass.testSize>0: testStrem = self.dataClass.random_batch_data_stream(batchSize=batchSize, type='test')
itersPerEpoch = self.dataClass.trainSampleNum//batchSize # 训练数据总长度//批次大小 = preEpoch
# 定义有优化器
encoderOptimzer = torch.optim.Adam(self.encoderRNN.parameters(), lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
decoderOptimzer = torch.optim.Adam(self.decoderRNN.parameters(), lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
# 记忆个时间
st = time.time()
#做每个epoch循环
for e in range(epoch):
for i in range(itersPerEpoch):
X, XLens, Y, YLens = next(dataStream)
loss = self._train_step(X, XLens, Y, YLens, encoderOptimzer, decoderOptimzer, teacherForcingRatio)补充loss计算中_train_stap方法:
#训练中的梯度及loss计算 bp
def _train_step(self, X, XLens, Y, YLens, encoderOptimzer, decoderOptimzer, teacherForcingRatio):
#计算梯度 BP 模型梯度初始化为0
encoderOptimzer.zero_grad()
decoderOptimzer.zero_grad()
#计算loss
loss, nTotal = _calculate_loss(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, teacherForcingRatio, device=self.device)
#实现反向传播 loss/nTotal 平均生成一个字符的产生的loss,本身返回的loss是生成一句话,即连续decoder的loss和。
(loss/nTotal).backward()
# 更新所有的参数
encoderOptimzer.step()
decoderOptimzer.step()
return loss.item() / nTotal_train_stap:中包含计算梯度==>计算loss==>反向传播,和梯度清零的操作。
补充_calculate_loss方法:
技巧teacher forcing是加速收敛的一个技巧,在decoder迭代计算出预测index的过程中,如果第一个字就预测错了,那么作为错误的输入,后面预测的结果大概率也就是错的了,第一个字错误意整个序列错误,这样的情况很显然会让训练收敛很困难,所以我们可以让网络在训练过程中有一定概率进行teacher forcing:在网络预测网一个单词后,我们不以这个预测出的单词作为decoder的下一次输入,而是把这个位置上的标签值作为下一次输入。这么做相当于强制要求网络学会每一单词的输入。形象一点,也就是把网络往每个时序节点上拉扯(这是我对teacher forcing的理解)。引用自:
PyTorch搭建聊天机器人(三)训练与评估 - 知乎https://zhuanlan.zhihu.com/p/263067832 补充:关键API F.nll_loss
nll_loss 函数接收两个tensor第一个是模型的output,第二个是label target,output中每一行与一个标签中每一列的元素对应,根据target的取值找出output行中对应位置元素,求和取平均值。 PyTorch-损失函数-NLLLoss_花开花落,人走茶凉-CSDN博客_f.nll_losshttps://blog.csdn.net/weixin_40476348/article/details/94562240
def _calculate_loss(encoderRNN, decoderRNN, X, XLens, Y, YLens, teacherForcingRatio, device):
featureSize, hiddenSize = encoderRNN.featureSize, encoderRNN.hiddenSize
# X: batchSize × XSeqLen; Y: batchSize × YSeqLen
X, Y = torch.tensor(X, dtype=torch.long, device=device), torch.tensor(Y, dtype=torch.long, device=device)#转tensor
XLens, YLens = torch.tensor(XLens, dtype=torch.int, device=device), torch.tensor(YLens, dtype=torch.int, device=device)
batchSize = X.size(0)
XSeqLen, YSeqLen = X.size(1), YLens.max().item()
# 初始化encoderOutput
encoderOutput = torch.zeros((batchSize, XSeqLen, featureSize), dtype=torch.float32, device=device)
d = int(encoderRNN.bidirectional)+1
hidden = torch.zeros((d*encoderRNN.numLayers, batchSize, hiddenSize), dtype=torch.float32, device=device)
# XLens进行降序排序
XLens, indices = torch.sort(XLens, descending=True)
#索引回归升序排序=desortedIndices
_, desortedIndices = torch.sort(indices, descending=False)
encoderOutput, hidden = encoderRNN(X[indices], XLens, hidden)
# encoderOutput按desortedIndices 重排 对应原始的 X
encoderOutput, hidden = encoderOutput[desortedIndices], hidden[-d*decoderRNN.numLayers::d, desortedIndices, :] #hidden[:decoderRNN.numLayers, desortedIndices, :]
# 初始化decoderInput seq,以一个开始字符开始。
decoderInput = torch.tensor([[sosToken] for i in range(batchSize)], dtype=torch.long, device=device)
loss, nTotal = 0, 0
for i in range(YSeqLen):
#遍历 对于每个decoder的中,都会取top,并计算loss,训练过程中对比训练数据和真实数据之间的差
# decoderOutput: batchSize × 1 × outputSize
decoderOutput, hidden, decoderAttentionWeight = decoderRNN(decoderInput, hidden, encoderOutput)
loss += F.nll_loss(decoderOutput[:,0,:], Y[:,i], reduction='sum')
nTotal += len(decoderInput)
if random.random() < teacherForcingRatio:
decoderInput = Y[:,i:i+1]
else:
topv, topi = decoderOutput.topk(1)
decoderInput = topi[:,:,0]# topi.squeeze().detach()
# 过滤掉长度已经小于当次循环长度为i的句子。
restId = (YLens>i+1).view(-1)
decoderInput = decoderInput[restId]
hidden = hidden[:, restId, :]
encoderOutput = encoderOutput[restId]
Y = Y[restId]
YLens = YLens[restId]
# loss,和循环的计数。
return loss, nTotal计算具体loss值。
显示评价指标:
#计算bleu的参考指标
if (e*itersPerEpoch+i+1)%stopRound==0:
bleu = _bleu_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, self.dataClass.maxSentLen, device=self.device)
embAve = _embAve_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, self.dataClass.maxSentLen, device=self.device)
print("After iters %d: loss = %.3lf; train bleu: %.3lf, embAve: %.3lf; "%(e*itersPerEpoch+i+1, loss, bleu, embAve), end='')
if self.dataClass.testSize>0:
X, XLens, Y, YLens = next(testStrem)
bleu = _bleu_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, self.dataClass.maxSentLen, device=self.device)
embAve = _embAve_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, self.dataClass.maxSentLen, device=self.device)
print('test bleu: %.3lf, embAve: %.3lf; '%(bleu, embAve), end='')
restNum = ((itersPerEpoch-i-1)+(epoch-e-1)*itersPerEpoch)*batchSize
speed = (e*itersPerEpoch+i+1)*batchSize/(time.time()-st)
print("%.3lf qa/s; remaining time: %.3lfs;"%(speed, restNum/speed))ResNum:剩余的数据(对话数量),speed: 处理的数据量比时间差
这两个是翻译的评价指标
BLUE评价指标:机器翻译的评价指标https://zhuanlan.zhihu.com/p/223048748(#bleu的评价指标,机器翻译的指标,最起码句子能比较顺,能读的通)
主要输入就是:Y 和Y_PRE(预测结果)
主要API :from nltk.translate.bleu_score import sentence_bleu。
def _bleu_score(encoderRNN, decoderRNN, X, XLens, Y, YLens, maxSentLen, device, mean=True):
Y_pre = _calculate_Y_pre(encoderRNN, decoderRNN, X, XLens, Y, maxSentLen, teacherForcingRatio=0, device=device)
Y = [list(Y[i])[:YLens[i]-1] for i in range(len(YLens))]
Y_pre = Y_pre.cpu().data.numpy()
Y_preLens = [list(i).index(0) if 0 in i else len(i) for i in Y_pre]
Y_pre = [list(Y_pre[i])[:Y_preLens[i]] for i in range(len(Y_preLens))]
bleuScore = [sentence_bleu([i], j, weights=(1,0,0,0)) for i,j in zip(Y, Y_pre)]
return np.mean(bleuScore) if mean else np.sum(bleuScore)embAVe评价指标:类似平方差之类的 :emb表示Y和Y_PRE经过embedding数据格式得转换(作用主要在于每个字符,与文中的所有字产生关联,变成词嵌入向量形式),AVE表示,平均提取方差值 ,或称平均变抽取,是统计学中检验结构变量内部一致性的统计量。
验证性因素分析AVE和CR值_fitzgerald0的博客-CSDN博客AVE (Average Variance Extracted)“平均方差提取值” 衡量收敛效度CR(Construct Reliability, CR)建构信度,反映了每个潜变量中所有题目是否一致性地解释该潜变量,当该值高于0.70时表示该潜变量具有较好的建构信度。验证性因素分析AVE和CR值,可以通过AMOS或者Mplus输出的因子负荷和误差变异,手工求解,也可以用R公式如下:...https://blog.csdn.net/fitzgerald0/article/details/78999691
def _embAve_score(encoderRNN, decoderRNN, X, XLens, Y, YLens, maxSentLen, device, mean=True):
Y_pre = _calculate_Y_pre(encoderRNN, decoderRNN, X, XLens, Y, maxSentLen, teacherForcingRatio=0, device=device)
Y_pre = Y_pre.data
Y_preLens = [list(i).index(0) if 0 in i else len(i) for i in Y_pre]
# emb代表embedding
emb = encoderRNN.embedding
# 每个单独的字符变成词嵌入向量
Y, Y_pre = emb(torch.tensor(Y, dtype=torch.long, device=device)).cpu().data.numpy(), emb(Y_pre).cpu().data.numpy()
# 每一句话的中的词的嵌入向量均值
sentVec = np.array([np.mean(Y[i,:YLens[i]], axis=0) for i in range(len(Y))], dtype='float32')
sent_preVec = np.array([np.mean(Y_pre[i,:Y_preLens[i]], axis=0) for i in range(len(Y_pre))], dtype='float32')
# 计算Ave
embAveScore = np.sum(sentVec*sent_preVec, axis=1)/(np.sqrt(np.sum(np.square(sentVec), axis=1))*np.sqrt(np.sum(np.square(sent_preVec), axis=1)))
return np.mean(embAveScore) if mean else np.sum(embAveScore)#保存model
def save(self, path):
torch.save({"encoder":self.encoderRNN, "decoder":self.decoderRNN,
"word2id":self.dataClass.word2id, "id2word":self.dataClass.id2word}, path)
print('Model saved in "%s".'%path)保存模型:保存4方面信息: encoder,decoder,word2id,id2word。
#读入预处理的数据进行操作
from model.pre_process import seq2id, id2seq, filter_sent
开始创建chatbot class ChatBot 类:
目的:定义聊天系统,将各个网络架构集合起来,组成整个系统。
class ChatBot:
def __init__(self, modelPath, device=torch.device('cpu')): #初始化
modelDict = torch.load(modelPath)
self.encoderRNN, self.decoderRNN = modelDict['encoder'].to(device), modelDict['decoder'].to(device)
self.word2id, self.id2word = modelDict['word2id'], modelDict['id2word']
self.hiddenSize = self.encoderRNN.hiddenSize
self.device = device
self.encoderRNN.eval(), self.decoderRNN.eval()定义:输入问题seq,传入神经网络后,结果序列中使用贪心算法,拿到回答seq 的过程。
ef predictByGreedySearch(self, inputSeq, maxAnswerLength=32, showAttention=False, figsize=(12,6)):
# inputseq :输入的问句
inputSeq = filter_sent(inputSeq) # 去掉停用词
inputSeq = [w for w in jieba.lcut(inputSeq) if w in self.word2id.keys()] #先做分词
X = seq2id(self.word2id, inputSeq) # 变成单词的编号
XLens = torch.tensor([len(X)+1], dtype=torch.int, device=self.device) #处理输入成张量,计算长度,加结束符
X = X + [eosToken] # 加终止符
X = torch.tensor([X], dtype=torch.long, device=self.device) # x输入数据转化成张量
#定义相关的层,确定相应的encoder,确定隐层
d = int(self.encoderRNN.bidirectional)+1 # 如果是双向的需要numlayers *2
hidden = torch.zeros((d*self.encoderRNN.numLayers, 1, self.hiddenSize), dtype=torch.float32, device=self.device)# hidden矩阵的初始化
encoderOutput, hidden = self.encoderRNN(X, XLens, hidden)
hidden = hidden[-d*self.decoderRNN.numLayers::2].contiguous()补充:contiguous:view只能用在contiguous的variable上。如果在view之前用了transpose, permute等,需要用contiguous()来返回一个contiguous copy。
一种可能的解释是:
有些tensor并不是占用一整块内存,而是由不同的数据块组成,而tensor的view()操作依赖于内存是整块的,这时只需要执行contiguous()这个函数,把tensor变成在内存中连续分布的形式。
继续:。。
定义循环得到每个字id的过程。当输出遇到结束符,或者超过最大长度限制结束。
attentionArrs = []
Y = []
decoderInput = torch.tensor([[sosToken]], dtype=torch.long, device=self.device) #给定decoder的输入 sos起始字符
while decoderInput.item() != eosToken and len(Y)如果需要showAttention 可视化:
if showAttention: # 是否可视化attention,
attentionArrs = np.vstack(attentionArrs) # 竖直(按列顺序)把数组给堆叠起来
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot('111')
cax = ax.matshow(attentionArrs, cmap='bone')
fig.colorbar(cax)
ax.set_xticklabels(['', ''] + inputSeq)
ax.set_yticklabels([''] + outputSeq)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show() 最终输出的结果seq 去掉最后的eos 结束符。
return ''.join(outputSeq[:-1])下边构建基束搜索beamsearch的定义,inference时使用,计算量比贪婪算法大:
原理解释:
如何理解语言生成的greedy search 与 beam search_姬香的博客-CSDN博客greedy search每一步都都采用最大概率的词,如下:from numpy import arrayfrom numpy import argmax# greedy decoderdef greedy_decoder(data): # 每一行最大概率词的索引 return [argmax(s) for s in data]# 定义一个句子,长度为10,词典大...https://blog.csdn.net/qq_18310041/article/details/89004108
def predictByBeamSearch(self, inputSeq, beamWidth=10, maxAnswerLength=32, alpha=0.7, isRandomChoose=False, allRandomChoose=False, improve=True, showInfo=False):
# 定义输出
outputSize = len(self.id2word)
inputSeq = filter_sent(inputSeq) #去停用词
inputSeq = [w for w in jieba.lcut(inputSeq) if w in self.word2id.keys()]#分词
X = seq2id(self.word2id, inputSeq)
XLens = torch.tensor([len(X)+1], dtype=torch.int, device=self.device) #输入转tensor 同时加结束符
X = X + [eosToken]
X = torch.tensor([X], dtype=torch.long, device=self.device)
# 默认参数情况下,使用双向gru encoder 和2层GRU decoder
d = int(self.encoderRNN.bidirectional)+1
# 初始化hidden
hidden = torch.zeros((d*self.encoderRNN.numLayers, 1, self.hiddenSize), dtype=torch.float32, device=self.device)
encoderOutput, hidden = self.encoderRNN(X, XLens, hidden)
hidden = hidden[-d*self.decoderRNN.numLayers::2].contiguous()
#把搜索宽度和最大回答长度做个数组 beamWidth行maxAnswerLength列
Y = np.ones([beamWidth, maxAnswerLength], dtype='int32')*eosToken
# prob: beamWidth × 1 下限的概率0 beamWidth行每一行seq的打分
prob = np.zeros([beamWidth, 1], dtype='float32')
#初始化输出seq 一个起始符开始。
decoderInput = torch.tensor([[sosToken]], dtype=torch.long, device=self.device)
# decoderOutput: 1 × 1 × outputSize; hidden: numLayers × 1 × hiddenSize
decoderOutput, hidden, decoderAttentionWeight = self.decoderRNN(decoderInput, hidden, encoderOutput)
# topv: 1 × 1 × beamWidth; topi: 1 × 1 × beamWidth
# 在贪心算法中只取了topk(1),这里beamWidth。
topv, topi = decoderOutput.topk(beamWidth)
# decoderInput: beamWidth × 1
decoderInput = topi.view(beamWidth, 1)
for i in range(beamWidth):
Y[i, 0] = decoderInput[i].item()
Y_ = Y.copy() # 将第一个字符id 的beamWidth个结果 放在第一列的位置(每一行,0列)
prob += topv.view(beamWidth, 1).data.cpu().numpy()
prob_ = prob.copy() # 第一个字符id beamWidth个结果的概率
# hidden: numLayers × beamWidth × hiddenSize
hidden = hidden.expand(-1, beamWidth, -1).contiguous()
localRestId = np.array([i for i in range(beamWidth)], dtype='int32')
encoderOutput = encoderOutput.expand(beamWidth, -1, -1) # => beamWidth × 1 × hiddenSize
for i in range(1, maxAnswerLength):# 从第二个词开始,每个词进行计算
# decoderOutput: beamWidth × 1 × outputSize; hidden: numLayers × beamWidth × hiddenSize; decoderAttentionWeight: beamWidth × 1 × XSeqLen
decoderOutput, hidden, decoderAttentionWeight = self.decoderRNN(decoderInput, hidden, encoderOutput)
# topv: beamWidth × 1; topi: beamWidth × 1
if improve:
decoderOutput = decoderOutput.view(-1, 1)
if allRandomChoose:
topv, topi = self._random_pick_k_by_prob(decoderOutput, k=beamWidth)
else:
topv, topi = decoderOutput.topk(beamWidth, dim=0)
else:
topv, topi = (torch.tensor(prob[localRestId], dtype=torch.float32, device=self.device).unsqueeze(2)+decoderOutput).view(-1,1).topk(beamWidth, dim=0)
# decoderInput: beamWidth × 1
decoderInput = topi%outputSize
#计算过程,主要算概率,算路径上的最大概率
idFrom = topi.cpu().view(-1).numpy()//outputSize
Y[localRestId, :i+1] = np.hstack([Y[localRestId[idFrom], :i], decoderInput.cpu().numpy()])
prob[localRestId] = prob[localRestId[idFrom]] + topv.data.cpu().numpy()
hidden = hidden[:, idFrom, :]
restId = (decoderInput!=eosToken).cpu().view(-1)
localRestId = localRestId[restId.numpy().astype('bool')]
decoderInput = decoderInput[restId]
hidden = hidden[:, restId, :]
encoderOutput = encoderOutput[restId]
beamWidth = len(localRestId)
if beamWidth<1: #直到搜索宽度为0
break
lens = [i.index(eosToken) if eosToken in i else maxAnswerLength for i in Y.tolist()]
ans = [''.join(id2seq(self.id2word, i[:l])) for i,l in zip(Y,lens)]
prob = [prob[i,0]/np.power(lens[i], alpha) for i in range(len(ans))]
# 上边的代码主要对结果,长度,概率,做了个定义和计算
# 给定结果id的策略
if isRandomChoose or allRandomChoose: #对于回答方面做的策略,会去prob最大的那个,同时也可以给出概率
prob = [np.exp(p) for p in prob]
prob = [p/sum(prob) for p in prob]
if showInfo:
for i in range(len(ans)):
print((ans[i], prob[i]))
return random_pick(ans, prob)
else:
ansAndProb = list(zip(ans,prob))
ansAndProb.sort(key=lambda x: x[1], reverse=True)
if showInfo:
for i in ansAndProb:
print(i)
return ansAndProb[0][0]定义验证的方法;
#定义验证方法
def evaluate(self, dataClass, batchSize=128, isDataEnhance=False, dataEnhanceRatio=0.2, streamType='train'):
dataClass.reset_word_id_map(self.id2word, self.word2id) #给定输入,同时初始化bleu等评价指标
dataStream = dataClass.one_epoch_data_stream(batchSize=batchSize, isDataEnhance=isDataEnhance, dataEnhanceRatio=dataEnhanceRatio, type=streamType)
bleuScore, embAveScore = 0.0, 0.0
totalSamplesNum = dataClass.trainSampleNum if streamType=='train' else dataClass.testSampleNum#选用test数据
iters = 0
st = time.time()
while True: #验证的循环中主要完成计算bleu和embave的评分同时打印出来
try:
X, XLens, Y, YLens = next(dataStream)
except:
break
bleuScore += _bleu_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, dataClass.maxSentLen, self.device, mean=False)
embAveScore += _embAve_score(self.encoderRNN, self.decoderRNN, X, XLens, Y, YLens, dataClass.maxSentLen, self.device, mean=False)
iters += len(X)
finishedRatio = iters/totalSamplesNum
# 打印时间,完成比例
print('Finished %.3lf%%; remaining time: %.3lfs'%(finishedRatio*100.0, (time.time()-st)*(1.0-finishedRatio)/finishedRatio))
return bleuScore/totalSamplesNum, embAveScore/totalSamplesNum定义根据概率,随机抽取k个结果:
def _random_pick_k_by_prob(self, decoderOutput, k):#根据概率随机取K个结果
# decoderOutput: beamWidth*outputSize × 1
df = pd.DataFrame([[i] for i in range(len(decoderOutput))])
prob = torch.softmax(decoderOutput.data, dim=0).cpu().numpy().reshape(-1)
topi = torch.tensor(np.array(df.sample(n=k, weights=prob)), dtype=torch.long, device=self.device)
return decoderOutput[topi.view(-1)], topi定义随机pick 一个概率比较大的结果。
def random_pick(sample, prob):#随机pick一个prob比较大的
x = random.uniform(0,1)
cntProb = 0.0
for sampleItem, probItem in zip(sample, prob):
cntProb += probItem
if x < cntProb:break
return sampleItem定义计算Y_pre(y预测结果的过程):
主要用于_bleu_score,_embAve_score评价指标。
#计算Y的预测值
def _calculate_Y_pre(encoderRNN, decoderRNN, X, XLens, Y, YMaxLen, teacherForcingRatio, device):
featureSize, hiddenSize = encoderRNN.featureSize, encoderRNN.hiddenSize
# X: batchSize × XSeqLen; Y: batchSize × YSeqLen
X, Y = torch.tensor(X, dtype=torch.long, device=device), torch.tensor(Y, dtype=torch.long, device=device) #给定输入
XLens = torch.tensor(XLens, dtype=torch.int, device=device)
batchSize = X.size(0)
XSeqLen = X.size(1)
encoderOutput = torch.zeros((batchSize, XSeqLen, featureSize), dtype=torch.float32, device=device) #encoder输出
d = int(encoderRNN.bidirectional)+1
hidden = torch.zeros((d*encoderRNN.numLayers, batchSize, hiddenSize), dtype=torch.float32, device=device)
# # XLens进行降序排序
XLens, indices = torch.sort(XLens, descending=True)
_, desortedIndices = torch.sort(indices, descending=False) #排序
encoderOutput, hidden = encoderRNN(X[indices], XLens, hidden)
encoderOutput, hidden = encoderOutput[desortedIndices], hidden[-d*decoderRNN.numLayers::d, desortedIndices, :] #hidden[:decoderRNN.numLayers, desortedIndices, :]
decoderInput = torch.tensor([[sosToken] for i in range(batchSize)], dtype=torch.long, device=device)#把encoder的输出接入到decoder输入中
Y_pre, localRestId = torch.ones([batchSize, YMaxLen], dtype=torch.long, device=device)*eosToken, torch.tensor([i for i in range(batchSize)], dtype=torch.long, device=device)
for i in range(YMaxLen): #循环 把每一个batch中的y_pre的得到(使用attention的权重)
# decoderOutput: batchSize × 1 × outputSize
decoderOutput, hidden, decoderAttentionWeight = decoderRNN(decoderInput, hidden, encoderOutput)
if random.random() < teacherForcingRatio:
decoderInput = Y[:,i:i+1]
else:
topv, topi = decoderOutput.topk(1)#取top1
decoderInput = topi[:,:,0]# topi.squeeze().detach()
Y_pre[localRestId, i] = decoderInput.squeeze()
restId = (decoderInput!=eosToken).view(-1)
localRestId = localRestId[restId]
decoderInput = decoderInput[restId]
hidden = hidden[:, restId, :]
encoderOutput = encoderOutput[restId]
Y = Y[restId]
if len(localRestId)<1:
break
return Y_predemo.py ,test.py, train.py 的讲解:
剩下的部分的代码就比较简单了,这里不做太多解释了,具体内容请看源码。
补充一个知识点:argparse.ArgumentParser() 的学习
Python3学习总结——argparse.ArgumentParser()_ia_heng的博客-CSDN博客@TOC本文只是作为以后回顾所学知识所用argparse 官方教程argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后 argparse 将弄清如何从 sys.argv 解析出那些参数。 argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。此模块是 Python 标准库中推荐的命令行解析模块。如何使用创建解...https://blog.csdn.net/qq_36293056/article/details/105122682
阿宅的后续故事:
通过几个昼夜的爆肝码代码,最后阿宅把那和阿美好几个G的美好回忆==>聊天记录文档,传入了系统中,聊天机器人学习。
”成功了!!成功了!!“,阿宅通红的眼睛盯着屏幕,身体激动的控制不住的抖动”我的阿美回来了!!55555.。。“。

阿宅心满意足的睡着了,在甜甜的梦乡中,嘴角抿起了笑意。。。。。