人工智能、深度学习和AIoT
1 引言
如果从人类最初的幻想开始算起,人工智能的历史非常久远,也许能与人类文明比肩。而现代化的人工智能历史是从1956年达特茅斯会议开始的。在这之后,人工智能的研究几经起落,符号主义、联结主义、专家系统等都曾经兴盛一时。如今,深度学习又代表人工智能走上了时代潮头,几乎渗透到了这个时代的每一个领域。

然而,不管是哪一种技术手段,到目前为止,人工智能终究不过是一种对人类智能的拙劣模仿。每一种学说和流派都只是站在某一个角度来看待、模仿人类某一方面的思维、语言和行动。
从某种程度上说,是深度学习让人工智能走出学术象牙塔和科幻作品,在二十一世纪的第二个十年火遍整个世界。然而令人遗憾的是,这种盛况的出现并不是因为人工智能理论的突破,而是因为人类社会整体科技和生活方式的发展。
正如很多人了解的那样,如今蓬勃发展的人工智能技术有三大支柱,分别是算法、算力和数据。准确地说,这三根支柱支撑起来的不是人工智能技术,而是深度学习技术。再进一步地说,真正促使人工智能在二十一世纪腾飞的,不是算法,而是算力和数据。
2 深度学习的基石
早在1957年,Rosenblatt就在Cornell航空实验室发明感知机——一种简单的人工神经网络。然而,单层感知机能解决的问题是十分有限的,为此,Minsky甚至专门写了一本叫《感知机》的书与Rosenblatt论战,并取得了完胜。感知机的发展也因此而停滞,直到六十多年后才出现了多层感知机——深度神经网络。Rosenblatt的那个年代也是一个神仙打架的时代,Minsky更不用多说,他是达特茅斯会议的发起人之一、图灵奖获得者,更有一个响亮的称号——“人工智能之父”。如果仅仅是将人工神经网络的层数加深就能解决问题,这些宗师级的人物会想不到吗?当时摆在Rosenblatt眼前的事实是,他不知道如何对多层感知机进行训练。这就像一座无法逾越的大山,让当时的人看不到感知机未来的希望,直到计算机硬件水平发展到了二十世纪末才让多层感知机有了出现的基础。
1986年,Rummelhart、McClelland和Hinton在多层感知器中使用BP算法,才解决了深度人工神经网络训练的问题。1990到1998年期间,Lecun等人陆续发表了关于第一个深度卷积神经网络LeNet的论文,LeNet也成功应用于手写体字符识别应用中,在MNIST数据集上实现了99.2%的准确率。以最典型的LeNet-5为例,LeNet-5网络一共由7层组成,分别是三个卷积层(C1、C3、C5),两个下采样层(S2、S4),一个全连接层(F6)和一个输出层(softmax)。LeNet基本具备了现代CNN网络的特点,其局部感受野、权值共享和下采样的核心思想至今依然影响着CNN网络的发展。然而,真正使深度神经网络声名鹊起的却并不是LeNet,而是还要等到2012年的AlexNet。在这之前,还有两个工作是至关重要的。一个是斯坦福大学李飞飞教授发起的ImageNet项目,一个是NVIDIA推出的通用并行计算架构CUDA。

ImageNet是一个包含超过1400万张图像和2万多个类别的大规模标注图像数据集,这些数据可以免费提供给研究人员用于非商业用途。2010年到2017年期间,ImageNet项目每年举办一次大规模视觉识别挑战赛,即ILSVRC。在历年的ILSVRC中涌现出了大量经典的、甚至划时代的深度学习算法,例如Inception、ResNet等。正是ImageNet和ILSVRC的出现,给深度学习的发展加上了液氮加速器。在2012年,AlexNet在ILSVRC竞赛上大放异彩,正式宣布了深度学习时代的开启。
NVIDIA是一家做显卡出身的公司,其最早推出的GPU产品(GeForce 256,1998年)最先在游戏领域得到了青睐,因为其特有的并行处理能力可以加快游戏的图形帧速度,这是CPU难以做到的。而并行处理能力,恰好也是深度神经网络中的矩阵运算所需要的。因此,将GPU用于深度神经网络的训练就顺理成章了。为了让工程师和科学家们更好地利用GPU进行通用计算,NVIDIA在2007年发布了面向开发者的通用并行计算架构CUDA,这直接推动了GPU进入深度学习领域,并逐渐取得了业界无可撼动的老大哥地位。目前,NVIDIA GPU依然是深度学习社区最为青睐的计算机硬件产品,其构建起的深度学习生态也已成为NVIDIA最为宽广的商业护城河,其他大部分企业只能望洋兴叹。
介绍完ImageNet和NVIDIA,回过头来再看AlexNet的成功。AlexNet能在2012年ILSVRC竞赛一举夺魁,固然离不开Hinton、Krizhevsky等人在算法上做出的努力,但这些努力却更多的体现在如何对深度神经网络进行更好的训练上,例如使用Dropout、数据增广、激活函数ReLU,并采用了多GPU训练。我们应该看到AlexNet的成功还有另外两块至关重要的基石,那就是相比于前深度学习时代的以NVIDIA GPU为代表的超大算力和以ImageNet为代表的海量数据。没有这两者,深度学习便无从谈起。

3 深度学习的本质
深度学习虽然在第三次人工智能浪潮中取得了令人惊叹的表现,但难以回避的是,其从一开始就有着令人不安的缺陷,那就是不可解释性。深度学习不但没有符号主义严密的逻辑关系,甚至也丢掉了统计学习分而治之(divide and conquer)的思想,它所呈现出的是一种端到端(end to end)的黑盒模式,只有输入和输出,没有能令人信服的理由。因为不可解释,所以也不可靠。因此,深度学习在很多对安全要求极为严苛的领域都难以实用。
然而不可否认的是,从结果上看,深度学习确实在一些领域取得了质的突破,甚至在某些限制性任务上超出了人类的平均水平,例如ResNet在2015年ILSVRC竞赛的分类任务上历史性超过人类,Alpha Go击败人类顶级棋手。
正如世界上所有事物一样,深度学习也具有着让人矛盾的两方面,一方面是远超传统算法的鲁棒性、泛化性和准确性,另一方面是令人难以捉摸的不可解释性。而这两方面的原因都应该从其本质上去寻找。而深度学习的本质是高维拟合。
到目前为止,不论人工智能技术怎样发展,其不变的技术核心还是数学建模,还是在用各种数学模型来解决实际问题。最简单的数学模型是线性拟合,复杂一点可以做曲线拟合或平面拟合,再复杂一点可以做超平面拟合,也就是从某些角度增加模型的维度。深度学习的核心特征是深层结构和海量参数,本质上是在用海量参数高维拟合复杂数据,而这些参数都是通过训练策略模型自己“学习”到的,我们不知道哪些参数有什么样的现实意义,所以模型可解释性极差。但也是因为高维拟合,深度学习对问题的建模往往更加准确,所以在统计学意义上,深度学习算法常常是更优的。
从这个角度看,深度学习其实是一门工程,一门能够实现一定人工智能效果的计算机工程,谈不上科学,最多是脑科学、心理学等科学理论的拙劣应用。很多深度学习领域的从业者往往自嘲为“炼丹师”,因为真正在深度学习落地的环节,很多时候起决定性作用的不是算法上的差异,而是工程设计上的优劣。但如果将问题维度升级,深度学习也是可以帮助我们进行科学研究的,比如数据挖掘。计算机和我们人类不同的是,人类擅长演绎,而计算机擅长归纳。面对海量数据,人类很难从中归纳出隐藏很深的规律,但计算机可以,也不一定这就是科学规律,但这最起码给科学家提供了一些方向,再去证实或证伪,从这个角度而言,深度学习也是有助于科学发现的。
4 深度学习的应用
既然深度学习是一门工程,那只有能用起来它才有发展的生命力,否则迟早会被历史淘汰。应用就是深度学习的灵魂。事实上,深度学习领域的很多创新也都是为了能让深度学习算法真正用起来而设计的,比如残差结构是为了解决在模型训练中的梯度消失问题,批归一化(Batch Normalization)是为了解决训练中的局部最优问题。
与传统计算机应用不同的是,深度学习的应用为了实现落地,深度学习从硬件到软件发展出了一个庞大的工程生态。
深度学习的硬件可以分为两部分,一部分是训练端(类似于软件的开发侧),一部分是推理端(类似于软件的应用侧)。训练端的深度学习硬件要对大量数据进行并行处理,对算力的规模、速度要求极高,是一种高速密集并行计算模式。目前训练端的深度学习硬件主要以NVIDIA GPU为主。在此之外,国外还有Google TPU、AMD GPU等;国内有华为昇腾、百度昆仑芯等。NVIDIA最先开辟了深度学习硬件领域。凭借着先发优势和多年耕耘,NVIDIA建立起的行业生态非常成熟,与同类公司相比优势不可以道里计。推理端的深度学习硬件因为要保证算法的推理速度,因此更看重计算的效率,在很多场景下,任务对算法的响应速度要求很高,这时甚至需要将推理芯片部署到数据端,采用一种边缘计算模式。相比于训练端,推理端的深度学习硬件类型更丰富,按类型可以分为GPU、ASIC和FPGA三种。和训练端情况类似的是,NVIDIA同样占据了市场和生态的优势位,但不同的是,由于推理端靠近场景应用,在通用计算外,面向特定领域特定场景的硬件也能占据一席之地,因此有更多公司参与进来,形成了一个更为多元的局面。除NVIDIA Jetson外,国外还有Google Coral、Intel神经计算棒、Xilinx FPGA等;国内有华为Atlas、百度昆仑芯、寒武纪思元、地平线征程等。
相比其他计算机软件,深度学习软件对硬件更为依赖,这也是NVIDIA能在深度学习领域建立起巨大生态优势的关键原因之一。得益于最早进入深度学习领域,目前最为活跃的深度学习框架基本都建立在NVIDIA生态基础上,例如深度学习两大开源框架TensorFlow和PyTorch都对NVIDIA GPU有着很好的支持。而且除非自研芯片,否则新推出的深度学习框架也会首选适配NVIDIA GPU,而不是其他硬件。以下是在国内外最知名的两个开源代码托管平台码云(Gitee)和Github上的深度学习框架情况对比。
码云(Gitee)
| 排名 | 框架名 | Commits | Fork | Star | Contributors | 发布方 |
|---|---|---|---|---|---|---|
| 1 | MindSpore | 57650 | 3400 | 7100 | 1073 | 华为 |
| 2 | PaddlePaddle | 38537 | 321 | 3900 | 864 | 百度 |
| 3 | OneFlow | 8943 | 12 | 32 | 152 | 清华 |
| 4 | MegEngine | 2280 | 6 | 16 | 35 | 旷视 |
| 5 | Jittor | 2894 | 23 | 58 | 46 | 清华 |
Github
| 排名 | 框架名 | Commits | Fork | Star | Contributors | 发布方 |
|---|---|---|---|---|---|---|
| 国外 | ||||||
| 1 | TensorFlow | 139261 | 87500 | 169000 | 3236 | |
| 2 | Pytorch | 54187 | 16900 | 60600 | 2557 | |
| 3 | Theano | 28127 | 2500 | 9600 | 351 | 蒙特利尔大学 |
| 4 | MXNet | 11893 | 6900 | 20200 | 874 | Amazon |
| 5 | Caffe | 4156 | 1900 | 4300 | 269 | BAIR |
| 国内 | ||||||
| 1 | MindSpore | 56741 | 601 | 3200 | 421 | 华为 |
| 2 | PaddlePaddle | 38699 | 4800 | 19200 | 651 | 百度 |
| 3 | OneFlow | 8948 | 477 | 4000 | 清华 | |
| 4 | MegEngine | 2894 | 497 | 4400 | 40 | 旷视 |
| 5 | Jittor | 1539 | 270 | 2600 | 35 | 清华 |
深度学习框架实际上是一套对上快速开发算法、对下方便调用计算机硬件资源的软件工具箱,因此既和深度学习算法关系密切,又和计算机硬件强相关。根据使用阶段不同,深度学习框架也分为训练端和推理端两类。除了NVIDIA本身不做框架外,一般发布新框架的公司会与自己推出的硬件绑定,也会适配其他流行的深度学习框架。值得注意的是,为了增强不同框架的模型之间的可交互性,还有一种专门用来做中间表示的开放模型ONNX。通过ONNX,很多框架模型之间可以灵活转化,极大地方便了深度学习模型的部署。
4 AIoT
如果说应用是深度学习的灵魂,那AIoT就是深度学习的未来。
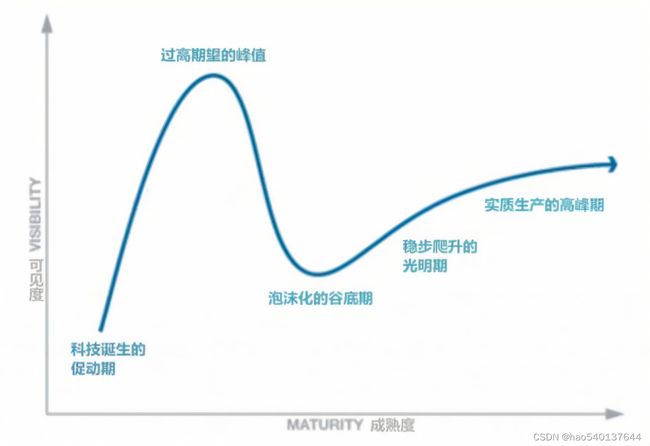
AIoT是AI和IoT的综合,也就是人工智能+物联网。根据高德纳技术成熟度曲线理论,目前深度学习已经处于高期望峰值与泡沫化谷底之间,亟需通过大规模的落地应用来实现再次的稳步爬升。
就目前的技术发展来看,深度学习很难实现所谓通用人工智能,人工智能技术在很长一段时间里还会遵守“没有免费的午餐(No Free Lunch Theorem, NFL)”理论。因此,深度学习的应用必须要结合具体场景,建立云边端协同和万物互联的AI应用未来。
5 小结
本文简单回顾了人工智能和深度学习的发展脉络,对深度学习的基础、本质和发展进行了一定的思考。观点纯属一家之言,欢迎批评讨论。
参考文章
- 《深度学习-31:单层感知机》https://blog.csdn.net/shareviews/article/details/83017353
- 《GPU在深度学习中究竟起了什么作用》https://blog.51cto.com/u_14411234/3114009