数据湖概念辨析以及常见技术通览
这是大数据技术扫盲系列的第二篇【数据湖概念辨析以及常见技术通览】
全文3000字,阅读需要10分钟
一、数据湖概念的起源
数据湖的概念被首次提出是在2010年的Hadoop World大会上,时任Pentaho创始人兼CTO的James Dixon,刚刚发布了Pentaho(一个BI分析组件)集成Hadoop的第一个版本。
在当时来看,hadoop还未被大规模应用,数据集市更多的基于传统数据库构建、且与应用绑定,数据并未集中化存储,BI在基于传统数仓架构下,仅允许聚合后的数据进行分析,这就导致两个核心问题:
只能使用部分属性,而这些数据也只能回答预先定义好的问题。
数据被聚合后,底层细节丢失,无法满足业务用户的个性化需求。
而数据湖概念刚被提出时,希望企业数据如同小溪一般,源源不断的、原汁原味的流入到数据湖中,用户可以直接基于数据湖里的数据提取、并萃取这些数据。
二、数据湖的定义
- 商业公司或组织给出的定义
维基百科:数据湖是一类存储数据自然/原始格式的系统,数据湖通常是企业中全量数据的单一存储,全量数据包括原始系统产生的数据、以及各类任务产生的转换后的数据,各类任务包括报表、可视化、高级分析和机器学习。数据结构包括包括结构化、半结构化、非结构化。数据沼泽是一种退化的、缺乏管理的数据湖。
AWS:数据湖是一个集中式存储,允许存储任意规模的结构化、非结构化数据。允许按照原样存储数据(无需对数据进行结构化处理)而运行不同类型的分析,包括转换、BI分析、机器学习等
阿里:数据湖是统一存储库,可以对接多种数据输入方式,可以存结构化、非结构数据,可以无缝对接多种计算分析平台。
微软:数据湖可以使开发者、数据科学家、分析师更简单的存储、处理数据,支持任意类型、任意规模、任意产生速度的数据,可以跨平台、跨语言。
综上,我们发现一些共性的内容,
数据湖可以存储任何类型的数据,包括结构化、半结构化、非结构化。
数据湖可以支持多种计算场景,包括BI分析、机器学习
数据湖支持任意规模数据的存储。
2.当今视角下,数据湖的新定义以及关键能力
我们站在2010年的视角来看数据湖,彼时,希望通过hadoop来解决原始数据的存储问题,通过连接BI做数据的分析和萃取问题。
我们站在当下的视角来看数据湖,如今存储的成本不再昂贵,数据湖也不是单单从存储的视角出发来强调集中存储,更是一种数据架构的方法,架构过程中需要考虑以下几个核心问题:
计算模式融合的问题:既要考虑结构化、也要考虑非结构化数据的计算和处理。结构化的数据我们已经处理了几十年,方法论也已经非常成熟,我们要考虑非结构化数据的存储、以及与机器学习平台的深入融合绑定。比如机器学习平台如何引入数据、标注数据、特征回写、训练等。
数据管理问题:要考虑退化的问题,让数据更有序,而非放任不管,在使用的时候提供更可信的数据,这里边包括流程、标准和规范、确保数据操作过程中的前向治理可落地。
从能力角度,数据湖应该具备以下能力
可快速集成数据的能力:用于快速接入数据
多源异构数据的存储能力:低成本存储数据
支持多种计算引擎的融合:包括离线计算、实时计算、以及机器学习训练
具备可信的数据管理能力。
三、数据湖 vs 数据仓库
辩论最多的就是数据湖和数据仓库的区别和联系,有很多的声音说数据湖是数据仓库的下一个阶段,但并非如此。
从价值主张上看,二者都是一种数据价值挖掘的构建方法。
从形式上看,数据湖强调数据的原汁原味,而数据仓库强调高度结构化和预定义。有一个形象的比喻,数据湖是水池,数据仓库是瓶装矿泉水。
从存储内容上看,数据湖不限制存储的数据类型,设备数据、社媒数据、应用数据等照单全收,而数据仓库强调业务系统内结构化的关系型数据。
至于网上其他的对比,包括存储的性价比(湖高仓低),数据质量(湖差仓好)、面向用户(仓仅面向业务分析、湖面向分析、开发和数据科学家)等等,我认为过于片面,比如在云原生的背景下,数据仓库也可以选择对象存储、匹配数据缓存技术加速查询,既做到了低成本,也做到了高效。数据仓库和数据湖是从数据的角度出发, 一种构建的方法论,而不应与技术做绑定。
一种常见的做法是,数据湖存储原汁原味的数据,机器学习平台从中抽取数据、数据仓库从中ETL数据、即席分析从中查询数据等。在仓和湖是一套治理体系,确保数据定义的一致性。
四、主流技术介绍
前面提到了,当下的数据湖是一种数据架构方法,而非一种技术,所以并没有一种技术可以提供整体的解决方案,都是从某一个特定维度出发而做出的阐述。目前最多的包括Hadoop、Delta Lake、Hudi、Iceberg。
1.Hadoop
Hadoop作为大数据技术的开山鼻祖,提供了最原始的分布式数据存储、以及离线计算能力,但是随着技术的发展,各种实时计算能力也逐步加入到hadoop生态圈内,所以基于hadoop也可以构建数据湖能力,存储能力由hdfs提供、计算能力则由上下游的生态提供,包括spark生态、hive的离线计算、flink实时计算、impala的即席查询等等。其中sparkMlib也内置了机器学习的算法,支持常用的机器学习建模。
以下三种技术都作为数据湖的数据存储层,主要提供数据管理功能,提供ACID语义、多版本、以及upsert。
2.Delta Lake
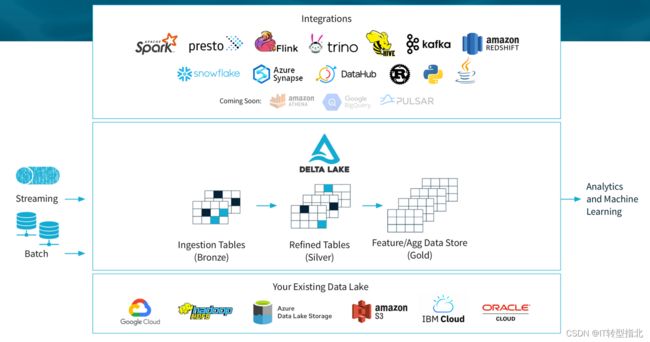
Delta Lake是Databricks公司推出的,在推出之前,Databricks的客户通过lambda架构来构建流批场景,
流处理链路:spark Streaming实时消费kafka的增量数据,得到实时的结果,这个仅保存当前时间下的状态,无法反映历史情况。
批处理链路:spark Batch消费kafka的增量数据,并将数据导入到文件系统中,主要是HDFS或者S3,用于下游的全量数据分析和处理
这套方案中,存在四个问题,
第一个是数据写入文件系统后,无法保证ACID语义,在写入的时候读取数据,可能读到中间态;
第二个无版本记录,业务需要读取最近n次导入的数据版本,这样的需求无法满足;
第三个是文件一旦写入到hdfs,修改数据的难度很大,尤其是面对回滚、删数据等场景下,都只能通过ETL的幂等流程设计才能实现。比如覆盖、做快照表、拉链表等;
第四个是文件系统写入时无法校验,缺少全局的严格schema规范,下游用数据的时候需要处理格式错乱的数据
databricks另外一个众人熟知的项目是spark,所以delta也作为spark生态的一部分,与spark绑定。
3.Hudi
全称,Hadoop Upserts Deletes and Incrementals
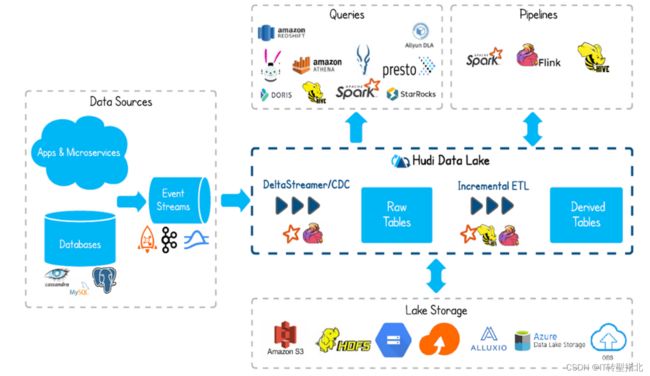
Hudi是Uber公司推出的,在推出之前,Uber通过hadoop解决了vertica扩展姓问题,但是仍碰到Databricks遇到的一些问题,最严重的就是无法upsert历史数据。
从业务的需求上看,数据湖需要同时满足读取历史数据需求、只读取实时数据需求、合并读取实时+历史需求。
hudi实现了copy on write 和merge on read两种数据格式,merge on read解决他们的快速upsert,把增量数据写入到delta文件中,定期合并delta文件和存量的data文件。
从名字上可以看出,hudi创立的强调了其主要支持 Upserts、Deletes 和 Incremental 数据处理
4.Iceberg
Iceberg是Netflix公司推出的,奈飞的工程师发现hive中一个月会产生2688个分区和270个数据文件,即使是面对简单的数据查询,数据分区裁剪的过程也需要十多分钟,主要问题是hive的元数据分别托管到hdfs和外部mysql,写入操作的ACID也无法保证。
所以iceberg也是从解决hive的ACID以及upsert角度出发来解决数据高效更新的问题