机器学习基础篇:关于线性回归-正则化、MLE、MLP
关于线性回归正则化、MLE、MLP
-
- 正则化、MLE、MLP
- 阐述线性回归从两个方面:
-
- 未加正则化的线性回归:
- 加了正则化后的线性回归:
- 过拟合:
-
- 正则化的框架:
- 另:
- 加L2正则化(矩阵形式)
- 加L2正则化(MLE-概率形式-频率派)
- MLE如下:
- 加L2正则化(概率形式-贝叶斯派)
- 结论
正则化、MLE、MLP
阐述线性回归从两个方面:
未加正则化的线性回归:
①标量的最小二乘法LSE:
损失函数是
L = ∣ ∣ w T x i − y i ∣ ∣ 2 L = ||w^Tx_i-y_i||^2 L=∣∣wTxi−yi∣∣2
,目标是求其最小值,对其做矩阵变换,变换后对w求导,
∂ L ( w ) w = ( X T X + X T X ) W − X T Y − X T Y = 2 X T X W − 2 X T Y = 0 \begin{aligned} \frac{\partial L(w)}{w} &=(X^TX+X^TX)W-X^TY-X^TY \\ &=2X^TXW-2X^TY=0 \end{aligned} w∂L(w)=(XTX+XTX)W−XTY−XTY=2XTXW−2XTY=0
得参数w的解,
有解即有最小值,但由于解的形式带逆,因此结果有风险
②概率角度解释:
MLE,假设值+高斯,概率
加了正则化后的线性回归:
最小二乘法 《=》最大后验估计
即 MLE+正则化 = MLP
过拟合:
①增加数据
②减少模型复杂度:特征选取pca、方差、P值
③正则化
正则化的框架:
a r g m i n [ L ( w ) + λ P ( w ) ] argmin[L(w)+\lambda P(w)] argmin[L(w)+λP(w)]
,其中 L ( w ) L(w) L(w)是损失函数, P ( w ) P(w) P(w)是惩罚项
另:
P ( w ) = ∣ ∣ w 1 ∣ ∣ 1 P(w)=||w_1||_1 P(w)=∣∣w1∣∣1
L 1 约 束 范 围 − > ∣ w 1 ∣ + ∣ w 1 ∣ + . . . + ∣ w n ∣ < = C L1约束范围->|w_1|+|w_1|+...+|w_n|<=C L1约束范围−>∣w1∣+∣w1∣+...+∣wn∣<=C
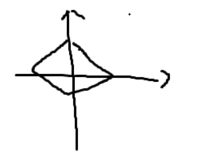
P ( w ) = ∣ ∣ w 2 ∣ ∣ 1 2 = w T w P(w)=||w_2||^2_1=w^Tw P(w)=∣∣w2∣∣12=wTw
L 2 约 束 范 围 − > ∣ w 1 ∣ 2 + ∣ w 1 ∣ 2 + . . . + ∣ w n ∣ 2 < = C L2约束范围->\sqrt{|w_1|^2+|w_1|^2+...+|w_n|^2}<=C L2约束范围−>∣w1∣2+∣w1∣2+...+∣wn∣2<=C

加L2正则化(矩阵形式)
因 为 P ( w ) = w T w 所 以 P ( w ) ′ = 2 λ w \begin{aligned} 因为P(w)=w^Tw \\ 所以P(w)'=2\lambda w \end{aligned} 因为P(w)=wTw所以P(w)′=2λw
其中w是n维的向量,加了L2正则化的求导如下
∂ L ( w ) w = ( X T X + X T X ) W − X T Y − X T Y + 2 λ w = 2 ( X T X + λ I ) W − X T Y 解 得 w = ( X T X + λ I ) − 1 X T Y \begin{aligned} \frac{\partial L(w)}{w} &=(X^TX+X^TX)W-X^TY-X^TY+2\lambda w \\ &=2(X^TX+\lambda I)W-X^TY \end{aligned} \\ 解得w = (X^TX+\lambda I)^{-1}X^TY w∂L(w)=(XTX+XTX)W−XTY−XTY+2λw=2(XTX+λI)W−XTY解得w=(XTX+λI)−1XTY
加L2正则化(MLE-概率形式-频率派)
MLE如下:
已知
y = w T x + ε , ε ∼ N ( 0 , σ 2 ) y=w^Tx+\varepsilon,\varepsilon \sim N(0,\sigma^2) y=wTx+ε,ε∼N(0,σ2)
得
p = ( y ∣ x i ; w ) ∼ N ( w T x , σ 2 ) p=(y|x_i;w)\sim N(w^Tx,\sigma^2) p=(y∣xi;w)∼N(wTx,σ2)
而对于单个样本来说
p ( y ∣ w ) = 1 2 π σ e − 1 2 σ 2 ( y i − w T x i ) 2 p(y|w) = \frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{1}{2 \sigma^{2}}(y_i-w^Tx_i)^{2}} p(y∣w)=2πσ1e−2σ21(yi−wTxi)2
又MLE是为了求得某参数使得函数达到最大值,这里我们用连乘
MLE->max(p1 * p2 * p3…pn)
因此,对于N个样本来说,概率似然函数为:
L ( w ) = l o g P ( Y ∣ X ; w ) = l o g ∏ i = 1 N P ( y i ∣ x i ; w ) = ∏ i = 1 N l o g P ( y i ∣ x i ; w ) = Σ i = 1 N l o g 1 2 π σ + Σ i = 1 N l o g e − 1 2 σ 2 ( y i − w T x i ) 2 = Σ i = 1 N ( l o g 1 2 π σ − 1 2 σ 2 ( y i − w T x i ) 2 ) \begin{aligned} L(w)&=log{P(Y|X;w)} \\&=log\prod_{i=1}^{N}{P(y_i|x_i;w)} \\&=\prod_{i=1}^{N}log{P(y_i|x_i;w)} \\&=\Sigma_{i=1}^{N}log\frac{1}{\sqrt{2 \pi} \sigma} + \Sigma_{i=1}^{N}loge^{-\frac{1}{2 \sigma^{2}}(y_i-w^Tx_i)^{2}} \\&=\Sigma_{i=1}^{N}(log\frac{1}{\sqrt{2 \pi} \sigma}-\frac{1}{2 \sigma^{2}}(y_i-w^Tx_i)^2) \end{aligned} L(w)=logP(Y∣X;w)=logi=1∏NP(yi∣xi;w)=i=1∏NlogP(yi∣xi;w)=Σi=1Nlog2πσ1+Σi=1Nloge−2σ21(yi−wTxi)2=Σi=1N(log2πσ1−2σ21(yi−wTxi)2)
求解参数w为
w ^ = a r g m a x ( L ( w ) ) = a r g m a x ( − 1 2 σ 2 ( y i − w T x i ) 2 ) = a r g m i n ( y i − w T x i ) 2 \begin{aligned}\hat{w}&=argmax(L(w)) \\&=argmax(-\frac{1}{2 \sigma^{2}}(y_i-w^Tx_i)^2) \\&=argmin(y_i-w^Tx_i)^2 \end{aligned} w^=argmax(L(w))=argmax(−2σ21(yi−wTxi)2)=argmin(yi−wTxi)2
得出:最小二乘法隐含了一个噪声服从正态分布的假设
加L2正则化(概率形式-贝叶斯派)
此时的w参数不再是固定的,而是一个随机变量,根据新增信息(先验)
w ∼ N ( 0 , σ 0 2 ) w \sim N(0,\sigma_0^2) w∼N(0,σ02)
计算修正概率,更新后验概率值得到后验概率
p ( w ∣ y i ) = p ( y ∣ w ) p ( w ) p ( y ) p(w|y_i)=\frac{p(y|w)p(w)}{p(y)} p(w∣yi)=p(y)p(y∣w)p(w)
MAP角度来看,求w的最大后验:
w ^ = a r g m a x ( ∏ i = 1 N p ( w ∣ y i ) ) \begin{aligned}\hat{w}&=argmax(\prod_{i=1}^{N}p(w|y_i)) \end{aligned} w^=argmax(i=1∏Np(w∣yi))
因为p(y)跟w无关,相当于一个常量,因此有
w ^ = a r g m a x ( p ( y ∣ w i ) p ( w i ) ) \begin{aligned} \\\hat{w}&=argmax(p(y|w_i)p(w_i)) \end{aligned} w^=argmax(p(y∣wi)p(wi))
又由前面MLE可得(单样本来看)
似 然 : p ( y ∣ w ) = 1 2 π σ 2 e − 1 2 σ 2 ( y i − w T x i ) 2 似然:p(y|w) = \frac{1}{\sqrt{2 \pi} \sigma^2} e^{-\frac{1}{2 \sigma^{2}}(y_i-w^Tx_i)^{2}} 似然:p(y∣w)=2πσ21e−2σ21(yi−wTxi)2
先 验 : p ( w ) = 1 2 π σ 0 2 e − 1 2 σ 2 ∣ ∣ w ∣ ∣ 2 2 先验:p(w) = \frac{1}{\sqrt{2 \pi} \sigma_0^2} e^{-\frac{1}{2 \sigma^{2}}||w||_2^{2}} 先验:p(w)=2πσ021e−2σ21∣∣w∣∣22
可得
w ^ = a r g m a x ( p ( y ∣ w ) p ( w ) ) = a r g m a x l o g [ p ( y ∣ w ) p ( w ) ] = a r g m a x l o g ( p ( y ∣ w ) ) + a r g m a x l o g ( p ( w ) ) = a r g m a x ( − 1 2 σ 2 ( y − w T x ) 2 − 1 2 σ 0 2 ∣ ∣ w ∣ ∣ 2 2 ) = a r g m i n ( ( y − w T x ) 2 σ 2 + ∣ ∣ w ∣ ∣ 2 2 σ 0 2 ) \begin{aligned} \\\hat{w}&=argmax(p(y|w)p(w)) \\&=argmaxlog[p(y|w)p(w)] \\&=argmaxlog(p(y|w))+argmaxlog(p(w)) \\&=argmax(-\frac{1}{2 \sigma^{2}}(y-w^Tx)^{2}-\frac{1}{2 \sigma_0^{2}}||w||_2^{2}) \\&=argmin(\frac{(y-w^Tx)^{2}}{\sigma^{2}}+\frac{||w||_2^{2}}{\sigma_0^{2}}) \end{aligned} w^=argmax(p(y∣w)p(w))=argmaxlog[p(y∣w)p(w)]=argmaxlog(p(y∣w))+argmaxlog(p(w))=argmax(−2σ21(y−wTx)2−2σ021∣∣w∣∣22)=argmin(σ2(y−wTx)2+σ02∣∣w∣∣22)
因此
w ^ M A P = a r g m i n Σ i = 1 N ( y i − w T x i ) 2 + σ 2 σ 0 2 ∣ ∣ w ∣ ∣ 2 2 \begin{aligned} \\\hat{w}_{MAP}&=argmin\Sigma_{i=1}^{N}(y_i-w^Tx_i)^{2}+\frac{\sigma^{2}}{\sigma_0^{2}}||w||_2^{2} \end{aligned} w^MAP=argminΣi=1N(yi−wTxi)2+σ02σ2∣∣w∣∣22
结论
-
结论1:未加正则项情况下,最小二乘法是 《=》极大似然估计MLE+噪声符合高斯分布
-
结论2:加L2正则项情况下,最小二乘法/MLE是 《=》MAP+先验和噪声都符合高斯分布