python相关性分析
什么是相关性
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关性的三种方法
皮尔逊相关系数(pearson):pearson相关系数连续性变量才可采用
肯达相关系数(kendall):Kendall相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。
斯皮尔曼相关系数(spearman):spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。
两个连续变量间呈线性相关时,使用Pearson积差相关系数,不满足积差相关
分析的适用条件时,使用Spearman秩相关系数来描述,当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用spearman或kendall相关。
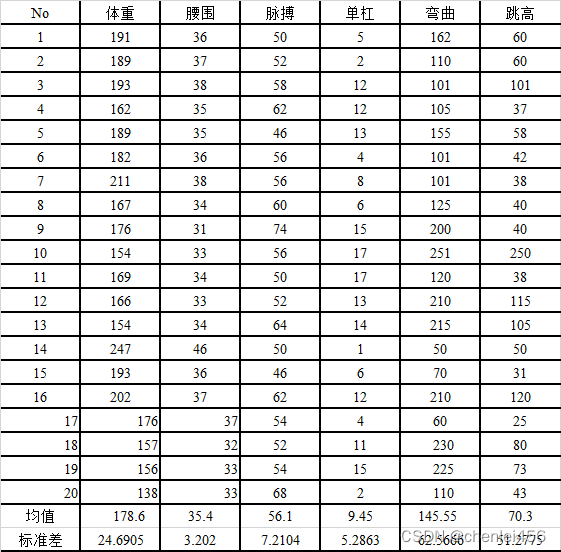
数据
pandas.DataFrame.corr(method='pearson')
'参数'
"""
method= pearson,kendall,spearman 对应着三种方法
默认meathod = pearson
"""
import pandas as pd
data = pd.read_excel("D:\sheet\corr.xlsx")
df = data.iloc[:20,:] # 相关性分析的时候不需要用到 均值和标准差
print(df.corr())# 这组数据采用默认Pearson进行相关性分析
体重 腰围 脉搏 单杠 弯曲 跳高
体重 1.000000 0.870243 -0.365762 -0.389694 -0.493084 -0.226296
腰围 0.870243 1.000000 -0.352892 -0.552232 -0.645598 -0.191499
脉搏 -0.365762 -0.352892 1.000000 0.150648 0.225038 0.034933
单杠 -0.389694 -0.552232 0.150648 1.000000 0.695727 0.495760
弯曲 -0.493084 -0.645598 0.225038 0.695727 1.000000 0.669206
跳高 -0.226296 -0.191499 0.034933 0.495760 0.669206 1.000000
相关关系不等因果关系
相关性表示两个变量同时变化,而因果关系是一个变量导致另一个变量变化,例如,一项统计显示,游泳时溺水人数越多,冰淇淋销售就越多,也就是游泳溺水人数和冰淇淋销售量之间呈线性正相关关系。由此可以得出吃冰淇淋就会增加游泳溺水的风险的结论吗?
显然不能得出这样的结论,这两个事件都受到了夏天气温升高的影响,是否吃冰淇淋跟溺水不存在任何因果关系。