《机器学习—李宏毅》HW1
目录
Objectives
Useful Links
PyTorch
Step 1. 读入和处理data
Dataset & Dataloader
Tensors
Step 2. 定义神经网络
定义一个神经网络层
定义自己的模型
Optimization
一、Features Scaling
参考文章
二、选择合适的features
原理
方法
一 过滤法
二 包装法
三 嵌入法
黑盒试错法
参考文章
具体实践——通过kaggle波士顿房价预测来提升hw1的perfrom
三、网络结构调整
参考文章
四、optimizer调整
参考文章
遇到的问题
Objectives
DNN+Regression/Training tips/PyTorch
Useful Links
Gradient Descent
DNN
Pytorch
PyTorch
针对作业可能需要用到的utils,进行代码教学
Step 1. 读入和处理data
Dataset & Dataloader
Dataset用来读入和存储data,dataloader用来批处理这些数据。
定义自己的data初始化和处理类,用来实现下面的loader:

Tensors
张量存储与计算,以及常见的可能遇到问题,和numpy的相似方法
用它来做梯度下降非常方便,如下图:

Step 2. 定义神经网络
定义一个神经网络层
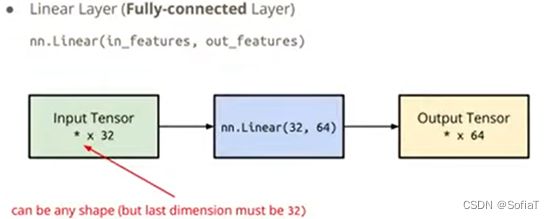
定义自己的模型


Optimization
一、Features Scaling
参考文章
使用sklearn里的方法,因为以下概念没搞清楚,导致预测大幅偏离。
fit,transform,fit_transform详解_Mingsheng Zhang的博客-CSDN博客_fit_transform参数
二、选择合适的features
原理
剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间,解决过拟合的问题。
方法
根据特征选择的形式,可分为三大类:
- Filter(过滤法):按照
发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选 - Wrapper(包装法):根据目标函数(往往是预测效果评分),每次选择若干特征,或者排除若干特征
- Embedded(嵌入法):先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征(类似于Filter,只不过系数是通过训练得来的)
一 过滤法
通过各种评测方法对features与y的相关性进行打分,选取得分偏高的features,过滤掉得分低的features。
1. Pearson相关系数
几何意义,可以理解为两个向量之间的夹角余弦值。相关系数为:

优点:速度快、易于计算;
缺点:只能判断线性相关性,如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
实际使用
注意要先把数据Features Scaling再做皮尔逊系数计算
其他参考
如何理解皮尔逊相关系数(Pearson Correlation Coefficient)? - 知乎 (zhihu.com)
sklearn特征缩放(feature scaling)[MinMaxScaler, standardization]_墨氲的博客-CSDN博客_sklearn 特征缩放
2. 卡方验证
其他参考
卡方检验(两个类别变量是否独立)以及chi2_contingency - 小小喽啰 - 博客园 (cnblogs.com)
机器学习之sklearn.feature_selection chi2基于卡方,特征筛选详解 - 简书 (jianshu.com)
3. MIC
4. 距离相关系数
5. 方差选择法
二 包装法
1. 前向搜索
2. 后向搜索
3. 递归特征消除法
三 嵌入法
1. 基于惩罚项的特征选择法
2. 基于学习模型的特征排序
黑盒试错法
参考文章
【机器学习】特征选择(Feature Selection)方法汇总 - 知乎 (zhihu.com)
A Simple Way to Know How Important Your Input is in Neural Network | by Muhammad Ryan | DataDrivenInvestor
具体实践——通过kaggle波士顿房价预测来提升hw1的perfrom
参考Code房价预测kaggle入门项目
跟随练习
1. 分析output,发现output不是正态分布而是双峰分布

简单搜索了一下,貌似output不是正态分布在CNN中没啥问题,参考帖子:
machine learning - Is it important for a neural network to have normally distributed data? - Stack Overflow
regression - How to to get normal distributed neural network output - Cross Validated (stackexchange.com)
数据不正态分布如何办? - 知乎 (zhihu.com)
2. 分析特征数据
用sns.boxplot做箱图分析,如各州之间感染数目的差异:

看来boxplot适合用于看类似enum类别的数据。其他的数据都是比较分散的浮点数,这里不做箱图分析了就。
3. 利用HeatMap
利用以协方差为原理的热度图

分析可见,行为类别的8个features,在这五天强相关
Behavior Indicators (8) ○ wearing_mask、travel_outside_state...
相关疾病监测的4个features五天也都是互相强相关
COVID-like illness (4) ○ cli、ili …
HeatMap具体教程:
Seaborn Heatmap using sns.heatmap()
4. 按照上述分析调整features
对于高度线性相关,且scale也类似的数据,取求和后的平均值,最后把features降到18,private score从1.32 提升到 1.09
三、网络结构调整
没有找到比较好的方法,于是使用暴力循环,遍历了有两层nn.linear的情况下node不超过features的所有情况,取前18个最优值,经过比较得到i=2, j=11(此时features=18)为最优解,同时private score从1.09 提升到 0.98
参考文章
How to Configure the Number of Layers and Nodes in a Neural Network (machinelearningmastery.com)
四、optimizer调整
参考文章
torch.optim — PyTorch 1.11.0 documentation
五、继续提升
参考文章
李宏毅2022机器学习HW1解析_机器学习手艺人的博客-CSDN博客_李宏毅hw1
2022李宏毅作业hw1—新冠阳性人员数量预测。_亮子李的博客-CSDN博客_李宏毅hw1
之前手动选取的features,得到的最优score为0.97995,现在在此基础上换用selectKBest的f_regression取前25个,提升为Score: 0.90655。

模型上试了一下,用nn.LeakyReLU(0.1)替换RELU,在我这边反而降低了,所以没有采用。
遇到的问题
1. pytorch与torch的区别安装
conda安装torch报错后,经查阅发现这里hw给的import的torch和pytorch完全是两个不同的模组。参考stack overflow:
可以直接pip安装,安装后报错,开始思考是不是另外两个模组与torch有关
todo:按照pdf上安装环境
2. 报错
安装源错了,我默认安装成了清华镜像的,uninstall后-c pytorch了