如何读论文(李沐)
目录
- 第一遍——选出有价值的文章
- 第二遍——精度部分文章
- 第三遍—重点研读一篇文章
- ResNet论文逐段精读【论文精读】 ——训练比较快
-
- 1. intro
- 解决梯度消失或者梯度爆炸的方法?
- identity mapping
- deep residual learning framework
- 2. Related work
-
- 残差连接,如何处理输入和输出是不同的情况?
- 如何适应更深的网络?
- 对比SGD 和 ResNet
- 虽然层数很深,但是模型复杂度不大的话,也不容易过拟合
- residual 和 机器学习中gradient boosting不同
- Transformer论文逐段精读【论文精读】——处理时序信息,如机器翻译
-
- 深度学习模型
- abstract
- 结论
- intro
-
- RNN 的特点是什么?缺点是什么?
- Background
- 第一段:如何用卷积神经网络替换掉循环神经网络,使得减少时序的计算?
- 第二段:自注意力机制
- 3. model architecture
-
- 编码器-解码器架构?
- 3.1 Encoder and decoder stacks
-
- layer norm是什么?
- 3.2 注意力层
- transfromer 对于长信息的处理会更好?
- 5 training
- 零基础多图详解图神经网络(GNN/GCN)【论文精读】
-
- 图神经网络
- 如何把图片表示成图?
- 文本表示成图?
- 还有很多东西能表示成图?
- 把数据表示成图后,,在图上能定义什么问题?
-
- 图层面的任务?
- 顶点层面的任务?
- 边上面的任务?
- 将神经网络用在图上面,,有什么挑战?
- 这么存之后,如何用神经网路处理它?
-
- 最后的输出,如何得到预测值?
- 信息传递?
-
- 可以在比较早的时候,进行边和顶点的汇聚?
- 加入全局的信息,有什么用?
- GNN 对于超参数比较敏感?
- 任何机器学习的模型,都有一些假设在里面?
- GCN 图卷积神经网络
- GNN评价
- 5 GAN 论文精度
- BERT ——自然语言处理NLP
-
- 1 intro
- 2. Related work
- 3.BERT (预训练,微调)
- 7-ViT论文逐段精读【论文精读】
-
- 如果在计算机视觉领域,想用transformer的话,,那问题是,,如何把图片,转变为1维的序列
- BERT
- GPT
- 结论
- 8-MAE 论文精读
-
- intro
- intro
- approach
-
- Q 怎么解码出相应的像素?
- 简单实现 simple implementation
- exp
- 12 如何找研究想法1
- 13 MoCo ——无监督表征学习
- 15 Alphafold2 科学界的最大突破2021
- 16 Deepmind 用机器学习帮助数学文章
- 17 Swin transformer (ICCV21最佳论文)
- 18 研究工作的价值
- 19 AlphaFold2
- 20 研究新意度(Novelty)
- 21 CLIP论文 (openAI)未开源
- 22 双流网络论文——视频分类领域开山之作
- 23 GPT, GPT2, GPT3 —— openAI
- openAI codex ——gpt (关注他们解决的问题)
- deepmind alphaCode
- 26 HAI 人工智能的报告
- 27 双流I3D网络—— 视频识别 kinetics (有代码)
- 28 视频理解串
-
- 1手动特征 - CNN
- Two-Stream
- 3D CNN
- Video transformer
- 29 操作系统方向——参数服务器
- 30 串烧
-
- C3D
- Non-local Neural Networks-做视频理解
- A closer Look at Spatiotemporal Convolutions for Action Recognition
- SlowFast Networks for video recognition
- video transformer
- Is space-time attention all you need for video understanding?
- Pathways 论文精读——系统方向
- GPipe: Efficient training of Giant Neural Networks using Pipeline Parallelism ——系统方向
-
-
- 模型并行 和 数据并行
- megatron LM:Training Multi-Billion Parameter Language Models Using Model Parallelism
-
- title
- abs
- intro
- method
- exp
- conclusion
第一遍——选出有价值的文章
看题目, 摘要,直接看结论
要知道文章,大概讲什么,,方法怎么样
决定要不要继续读
第二遍——精度部分文章
了解作者是怎么想的,怎么讲述东西的
可以从头到尾读,
作者提出的方法,和别人的方法差别有多大,,流程图,,x轴,y轴
读它引用的文献
第三遍—重点研读一篇文章
知道每一句话在干什么,,,重复,实现这一片文章,脑补文章
我会怎么办?能不能走下去?
ResNet论文逐段精读【论文精读】 ——训练比较快
https://www.bilibili.com/video/BV1P3411y7nn/?spm_id_from=333.788
1. intro
介绍应该是,摘要的强化版,介绍工作
解决梯度消失或者梯度爆炸的方法?
- 随机初始化时,不要太大, 也不要太小
- 在中间加入一些正则化,batch normalization,可以使得校验每个层之间的输出,梯度的均值和方差,可以使得很深的网络可以训练
是可以训练,可以收敛,但是精度会变差?
但是这不是过拟合,,因为训练误差也降低了,,而overfitting是说,训练误差很好,测试误差很大
identity mapping
指的是,输入是x, 输出是 x
如果后面的那些层,都学成 x ->x 的结果,那么,更深的网络,也不应该精度变差!
deep residual learning framework
新增加的层,不应该直接去学 h(x), 而应该去学 h(x) - x, 也就是,新增加的层,要去学,,前几层预测值 与 最终结果 之间的残差
那最后的输出,就是 后基层预测的F(x)(理论上应该与,h(x) - x ,越接近越好) + x
2. Related work
残差连接,如何处理输入和输出是不同的情况?
- 输入和输出中添加一些额外的0, 使得这两个形状能对应起来
- 1*1的卷积层,,空间维度上不做改变,可以改变通道
如何适应更深的网络?
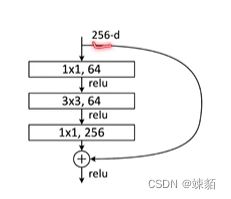
可以用更多的通道数 ,比如256,,如果不想计算力上升的话,,那可以先用11的卷积核 改变通道数,相当于降维,在进行运算,,在用11的卷积核回到原来的维度!
对比SGD 和 ResNet
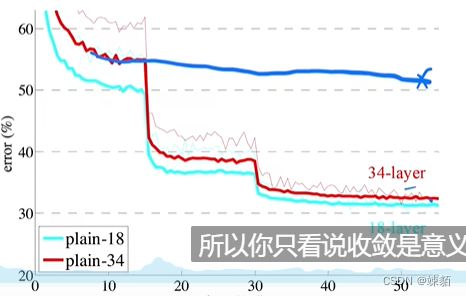
如果训练误差像蓝色一样,,那就需要在中间调一下,学习率,,就会像红色一样了
总结一下,也就是,当训练不动了之后,,需要调节学习率,已达到更优的效果
虽然层数很深,但是模型复杂度不大的话,也不容易过拟合
residual 和 机器学习中gradient boosting不同
gradient boosting 实在标号上做 residual
而,他实在特征上做 residual
Transformer论文逐段精读【论文精读】——处理时序信息,如机器翻译
最近几年,深度学习最重要的文章之一
深度学习模型
- MLP
- Cl
- RNN
- Transformer

abstract
BLEU score: 是机器翻译中,常见的衡量标准
主要是用在机器翻译领域的transformer,之后,bert , bgt把这个架构用在了更多的自然语言处理的任务上,,几乎什么东西都能用
结论
有代码:https://github.com/tensorflow/tensor2tensor
intro
RNN 的特点是什么?缺点是什么?
在RNN中,给定一个序列的话,它的计算是把这个序列从左到右一步一步的往前做
假设一个序列是一个句子的话,一个词一个词的看
对t个词,会计算一个输出,叫ht,,是一个隐藏状态,是有ht-1 和 t 这个词决定的
这样就可以,把前面学到的历史信息放在ht-1加上现在的t,得到输出。
问题是
- 难以并行,在GPU和 TPU上运行困难,计算性能差
- 历史信息一步一步传递,就像串行进位的加法器,,如果时序比较长的话,较前面的信息可能丢掉
但这一块也有很多改进,并行呀,分解呀,但本质上没有解决太多问题
attention在RNN中的应用:
怎么样把编码器的东西 有效的传递给 解码器
** transformer**
纯用attention,并行度高
Background
讲清楚相关工作是谁,联系是什么,区别是什么
第一段:如何用卷积神经网络替换掉循环神经网络,使得减少时序的计算?
CNN: 卷积在做计算时,每一次看一个比较小的窗口,如果两个像素隔得比较远的话,,则需要用很多层的卷积,才能把这两个隔得远的像素点融合起来
如果使用transformer的attention机智的话,,只需要一层就可以看到所有信息
卷积优点是:可以做多个输出通道,一个通道可以识别不同的模式
第二段:自注意力机制
3. model architecture
编码器-解码器架构?
编码器 : 有一个长度为n的序列,对于每一个单词,编码器会 把 它表示成, zt,是每一个单词对应的向量
解码器:拿到编码器的输出,然后会生成一个长度为m的序列,m和n不一定长
auto-regressive : 过去时刻的输出,也会作为当前时刻的输入,,成为 自回归
3.1 Encoder and decoder stacks
layer norm是什么?
** batch norm** : 每一次,把 每一列,就是每一个特征,把它在一个小的mini-batch里面,把它的均值变为0,方差变为1(算出这一列的均值和方差,,正态分布化标准)
在训练时这么做,,在测试机上,是全部的均值和方差,而不是每一列的
batch-norm也会学两个参数,使得能初始化为 任意均值和方差的矩阵
layer-norm : 把每一行,取出来,标准化
layer-norm 用的多,因为,在持续的序列模型中,每个样本长度可能会发成变化
当样本长度相差较大时,计算出的均值和方差差别也很大 ,如果样本序列太长,在训练时,没有见过,那么batchnorm结果可能不怎么好
3.2 注意力层
没听懂
transfromer 对于长信息的处理会更好?
attention 对于模型的假设更少,特征邵,也就是需要大数据量训练
是的,但是transformer需要更大的数据量才能训练出来,,相比如 RNN, 和卷积
5 training
bpe : 提取出词根,使得字典更小
零基础多图详解图神经网络(GNN/GCN)【论文精读】
课程地址
distill 博客 地址
图神经网络
只要层数足够多,那么一个阶段,,可以利用到后面的所有信息
如何把图片表示成图?
2442443的一张图,我们可以把它表示成一个tensor, 进行卷积操作
我们也可以把它 当成一个图,,它的每一个像素,就是一个顶点,,如果邻接,就有边
文本表示成图?
文本可以认为是一个序列,,我们可以把其中的每一个词,表示成每一个顶点,,上下词之间,有一条边
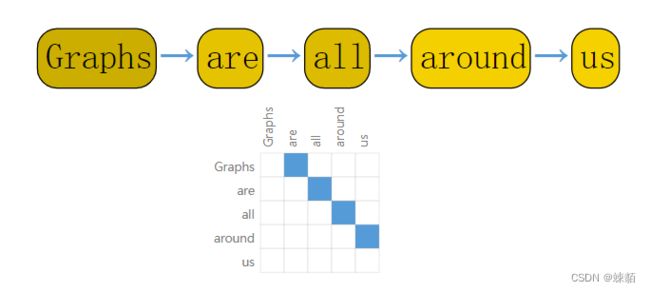
还有很多东西能表示成图?
引用图,关系图,分子图,知识图等等
把数据表示成图后,,在图上能定义什么问题?
图层面的任务?
给一张图,对图进行分类,,有两个环的,就挑出来
遍历就可以
顶点层面的任务?
判断每一个点,是 处于a 还是 属于 b?
边上面的任务?
给一张图片,,来学习,,图片中,人物之间的关系?
谁踢了谁,谁打了谁等等,,
给定图,预测边上的属性
将神经网络用在图上面,,有什么挑战?
最核心的问题是,如何表示图,使得,图和神经网络兼容?
如果用邻接矩阵表示,图顶点之间的连接信息的话,,那么矩阵可能会非常大,而且,邻接矩阵对于顺序不敏感(不同的顺序都表示同一张图)
其实,可以用邻接表变形的方式存储,存储高效 而且,顺序无关
这么存之后,如何用神经网路处理它?
GNN : 输入是图, 输出也是图,它会对顶点和边的向量进行改变,但是不会改变图的连接性。
最后的输出,如何得到预测值?
给了最后一层的输出,是一个图,对于每一个顶点,进入到一个线性层(全连接层),然后,进入softmax, 最后得到 分类的概率
不管缺乏那一个类,都可以通过汇聚的操作,得到对应的属性

信息传递?
假设要对 图的顶点 进行更新,那么不是只用它一个向量,,而是把它 和 它旁边的向量,都加起来,一起放入神经网络,这样,它就包含了周围的信息
可以在比较早的时候,进行边和顶点的汇聚?
把顶点和边的信息,互相加起来,,进行信息传递
加入全局的信息,有什么用?
在早期进行大量信息传递
GNN 对于超参数比较敏感?
层数,每个属性的嵌入有多大,汇聚用什么操作,信息传递方式
任何机器学习的模型,都有一些假设在里面?
比如,CNN,假设空间变换的不变性
RNN, 假设时序的连续性
GNN ,假设是, 图的对称性,时序不变形
GCN 图卷积神经网络
GCN,有k层,每一层都看它的卷积的话,每个点,都看,已自己为中心的点,做信息汇聚
GNN评价
图是个很强大的工具,,但是强大也会带来问题,,很难优化
它的每一个结构是一个动态的,如何在gpu上计算,是一个很难得事情。
图神经网络对于 超参数敏感
5 GAN 论文精度
gan,可以生成很多自然界中没有的东西
分辨模型: 给定一系列数据集,如何预测实数值
生成模型:生成数据本身
MLP (多层的感知机): multilayer perceptron
gan主要用在图片生成
BERT ——自然语言处理NLP
bert: 是用来设计去训练深的双向的表示,使用没有裱好的数据,联合左右的信息
1 intro
带掩码的语言模型,,没随机选一些资源,盖住,模型要预测盖住的东西是什么!也就是 完形填空
GPT 使用了transformer架构,只能处理单项的信息
ELmo双向想法,RNN
2. Related work
在 imagenet上训练好模型,拿到别的地方用
在大量的无标好的图片上训练出来的模型,可能比少量的有标号上训练出的模型要好
3.BERT (预训练,微调)
预训练是在没有裱好的数据上训练的,
所有权重,用有标号的数据,进行微调
在与训练时,输入是没有标号的句子堆,之后,对每一个任务创建一个bert模型,权重的初始化,就是训练好的值,,用有标记的数据,进行微调

7-ViT论文逐段精读【论文精读】
vision transformer 的结论是说,如果在足够多的数据上预训练,,也就不需要卷积神经网络,,直接用一个标准的 transformer 也能把问题处理的很好
一个纯transformer, 在图像块上,也是可以表现得很好的
现在大规模数据集上做训练,,然后,再在小数据集上做微调
tranfromer: 有一个编码器,输入是一系列单词,输出也是一些单词
transformer 最主要的操作,就是,自注意力操作
自注意力操作,就是每个元素 要和 每个元素做互动,两两互相,算的一个Attention, 也就是自注意力的图,然后用这个自注意力的图去做加权平均,最后得到输出
如果在计算机视觉领域,想用transformer的话,,那问题是,,如何把图片,转变为1维的序列
如果把每个像素,拉直,,那么序列长度太大,,复杂度太高
把图片分成小patch(1616), 一个patch是一个元素(通过线性层进行映射),然后大小为 224 x 224 的图片,,就被映射成了 1414的图片,有监督训练
BERT
类似于完形填空,预测被挖掉的词
GPT
用language modelling 做自监督,
有一个句子,预测下一个词
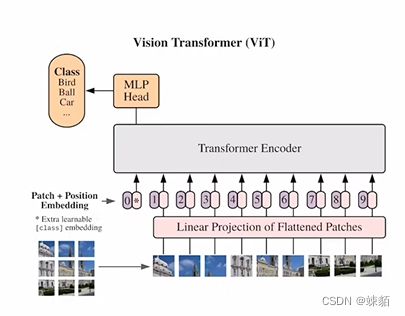
结论
如果数据集比较小(<14M),那还是用卷积
如果数据集比较大,那就用ViT
自注意力操作,能够模拟很长序列之间的关系
8-MAE 论文精读
transformer 是基于 纯编码器和解码器的架构的文章,在机器翻译上,比RNN好一点
bert : 把 transformer 拓展到 NLP任务上,使用了完形填空的自监督训练机制,可以在大规模的,没有标号的数据集上,训练处很好的模型
ViT: 将 transformer 用到CV上,把 图片分割成 16 X 16的patch, 然后每个patch作为一个词,放入transfromer中训练。
假设训练样本足够大,,可能比CNN有更好的性能
MAE : 通过完形填空来获取图片的理解,只不过拓展到没有标号的数据上,mae 是一个自编码器,可以重构图片中确实的像素
intro
MAE: 随机的盖住图像当中的一些块,然后去重构这些被盖住的像素
一是 非对称的 encoder 和 decoder架构,
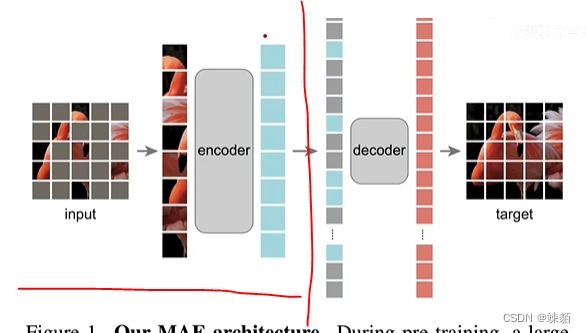
可以使用MAE的代码,红线部分前面的,都借鉴,,剩下的只增加几个层,就可以解决自己的问题了!!
intro
在NLP中,自监督学习已经可以做的很好了,但是在计算机视觉方面,还依然需要大量的标注的数据
CNN, 不好还原像素
**非对称的编码器和解码器架构:**编码器和解码器看到的图片不一样,编码器只看到 未被遮住的块,解码器能看到所有的块,,主要是为了加快计算速度
在大量没有标号的数据上,通过自监督学习,学习出模型,在迁移学习,也能取得不错的效果
approach
Q 怎么解码出相应的像素?
最后是一个线性层,这个线性层会投影到 16*16 大小的维度,然后reshape,就能还原出原始的像素信息
损失函数是mse
简单实现 simple implementation
生成token列,也就是,一个patch拿过来之后,做一次线性的投影,再加上位置信息。
把序列随机打乱,拿掉最后一块,解码时,还原成原来的顺序
exp
12 如何找研究想法1
- 别的数据增强,会不会速度更快,都连更快
- 新的模型,替换掉ViT
13 MoCo ——无监督表征学习
对比学习 : 通过多张图片对比着学习,对比学习要做的,就是,模型中相似的特征,尽可能的拉近,,不相似的尽可能,拉远
Moco, 可以构建一个有大有一致的字典,从而可以无监督的学习一个模型的视觉表征,,然后这个模型可以迁移到其他下游任务
对比学习的目标,不断改变的,和分类,目标检测这一类任务不一样
15 Alphafold2 科学界的最大突破2021
用 蛋白质的氨基酸序列 来 预测蛋白质的结构‘ —— 改变了整个生物学
16 Deepmind 用机器学习帮助数学文章
用在一个新领域了
Nature 和 Science 和顶级会议不一样 , 图做的很好
在数学里面,很重要的模式是发现一些导论,提出一些猜想
ai 可以找反例,证明定理等等
n-m+r=2 ,机器学习可以学到参数,然后用数学公式证明
- 发现参数,发现函数,存在某种关系
- 使用归因技术,查找更加有用的特征
你有很多想法,机器学习能帮你验证想法可不可靠,是不是值得继续想下去
17 Swin transformer (ICCV21最佳论文)
证明了,transformer 可以在视觉领域应用
swin transformer 就是想让 vision transformer 像卷积网络一样,也能够分成几个block, 也能做层级式的特征提取
基于移动窗口的自注意力机制
本来移动窗口之后,得到了9个窗口,而且窗口之间的patch数量每个都不一样,为了能达到高效性,批次处理
先进行循环位移,把9个窗口变成4个窗口,使用一种特殊的掩码机制,使得每一个窗口之间,能合理的计算自注意力
最后,再把自注意力还原得到原来的图
18 研究工作的价值
用有新意的方法,有效的,解决一个研究问题
摘要 :问题,新意,结果
19 AlphaFold2
用深度神经网络进行蛋白质结构预测
输入是,人类蛋白质的氨基酸序列,
输出是,预测三维空间中的位置
特征抽取,编码器,解码器
特征抽取之后,就得到 不同序列的特征 和 氨基酸之间的特征
现在,有标号上的数据上训练一个模型,然后把预测中置信度比较高的蛋白质序列拿出来,跟原始数据集,凑成一个更大的数据集,在重新开始训练
消融实验:去掉某块,之后的结果
20 研究新意度(Novelty)
21 CLIP论文 (openAI)未开源
输入是,一堆图片 和 图片的标签,,然后转化成矩阵,,通过对比学习的方法,(正负样本的区分),预训练,得到图片视觉上的特征,,无监督学习,需要大量的数据
直接从自然语言中,得到一些监督信号,多模态对比学习
分类也不一定局限于现在的标签
few-shot : 有一些带标签的数据
局限性 Limitatoin
不能通过扩大数据集的方法,提高精确度
应该要 思考更好的算法,在降低计算资源的情况下,提高准确度
对比学习的目标函数 和 生成学习的目标函数 合在一起
贡献
打破了固定标签的种类,用无监督的方式,泛化性能也很好
22 双流网络论文——视频分类领域开山之作
双流卷积神经网络 做 视频中的 动作识别
空间流神经网络 : 输入是单帧的图片,输出是分类的概率,
时间流神经网络(光流):输入是单帧的图片,输出是分类的概率,学习到动作信息
最后加权平均,就能得到最后的预测
光流,不仅计算速度慢,而且占用空间存储,,改进是,直接把光流信息压缩,存成图片
当我们发现一个神经网络解决不了问题的时候,我们也可以使用双流神经网络,,如果深度学习,学不到动作信息,,不放把动作信息作为一个先验的条件输入网络
23 GPT, GPT2, GPT3 —— openAI
transformer 的编码器 和 解码器:
编码器: 抽取特征,看到全局的序列,进行编码
解码器: 有掩码的存在,只看前面的信息,预测空的值
gpt ,就是 transformer的解码器
gpt2 : 数据集更大,
zero-shot : 做下游任务的时候,不需要重新训练模型,不需要带标签的数据,参数也不会变
openAI codex ——gpt (关注他们解决的问题)
代码,自动写代码 codex
fine-tuning : 微调
模型的影响:模型生成的代码,还是有可能出代码
不用太关注解决问题,而是关注数据
作者在github上爬了很多数据,然后训练处一个gpt3模型,根据文档写代码,然后,用164道题测试了一下
文档不能太长,问题不能太复杂,目前正确率30%左右
deepmind alphaCode
允许更长的文档,问题更复杂
搜集数据集,基于transformer的模型,效果好
26 HAI 人工智能的报告
模式识别是一个任务,要在数据中识别某一个任务,机器学习是一个技术
创造虚拟人脸
采集虚拟人的动作,运动员的关节
语义分割
医疗领域
人脸检测和识别:刷脸支付
视觉推理 : 图片中伞是向上还是向下
物体检测 : 目标检测(COCO)
文本摘要 : arXiv
情绪识别:评论是正面的还是负面的?
语音识别
RL :游戏(下棋)
机器人
机械手臂的价格:下降
AI判断虚假消息
27 双流I3D网络—— 视频识别 kinetics (有代码)
视频识别,a new model , kinetics dataset
视频识别:3种流行的视频识别的方法
第一:CNN + LSTM(处理时序信息)
第二种,训练3D网络
第三种,双流网络
双流 I3D: 从二位变成 3 维,用双流
使用2D网络参数进行扩充
下游任务:
视频分割、视频分类

28 视频理解串
1手动特征 - CNN
如何把卷积网络用到视频里面?
单帧进入CNN
多分辨率卷积神经网络
Two-Stream
从原始视频中抽取,光流图像,作为时间流信息
在模型中间,时空信息二合一,early fusion,一定程度上,early更好
similarly, there still have late fusion, that is, fusion optical stream with time stream at last layer.
3D CNN
特别简单的方式,处理长网络
视频理解——王利民
TSN 论文:视频理解文章
把视频分为几段,每段随机凑去一帧,,然后通过双流网络,在加权合并
segment: 分割
Batch Normalization : 虽然能让模型加速,但是也带来了严重的的后果,比如过拟合
Data augmentation: 数据增强。改变图片的长宽比,强制性在边角做裁剪
Video transformer
29 操作系统方向——参数服务器
容灾:持续备份
读数据,拿权重,迭代
分布式机器学习,就是把,机器学习的任务,分到多台机器上做
30 串烧
C3D
3D网络 直接学习时空特征,卷积神经网络

I3D 提出了一个数据集,2d 网络扩充成 3d网络
证明 是可以迁移的
自注意力,用来学习远距离特征
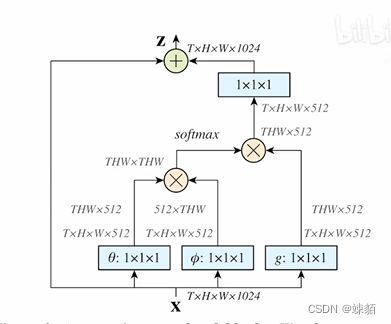
Non-local Neural Networks-做视频理解
自注意力模块,把2d -> 3d
不用光流信息,也能做的不错的结果
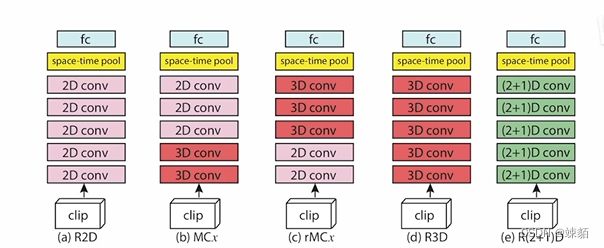
A closer Look at Spatiotemporal Convolutions for Action Recognition
测试到底哪种方法好?
SlowFast Networks for video recognition
重头训练,训练时间长不需要imagenet
没有使用光流,模拟人类的光流
慢分支,小输入,大网络
快分支,大输入,小网络
视频分类,视频检测,都很好
video transformer
Is space-time attention all you need for video understanding?
vision transformer 迁移到 video 上

Pathways 论文精读——系统方向
分布式ML:每台机器上,都安装pytorch所需要的包,存放上所有的代码,只不过每个机器拿到自己的数据,分别计算自己的梯度,
之后,梯度全部加起来,然后返回给各个计算机,再进行下一轮计算
tf 主要是高性能,应用的主要是公司,google内部的工程师
显示构造图,在编译,使用起来可能比较麻烦,也不方便查看中间变量
TPU:tpu的连接如下图,2d的格子设计,类似于超算,一个tpu核,会和他的上下左右的节点连接,是高速连接,,一个Pod, pod 与 pod 之间的连接是通过数据中心的,低俗的
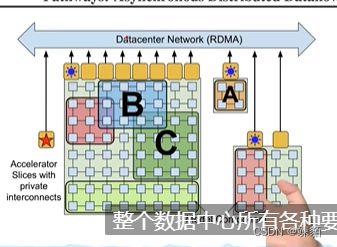
有可能死锁
GPipe: Efficient training of Giant Neural Networks using Pipeline Parallelism ——系统方向
流水线并行
模型并行 和 数据并行
模型并行: 把网络切开
数据并行,把数据切开,分别放在两块gpu上
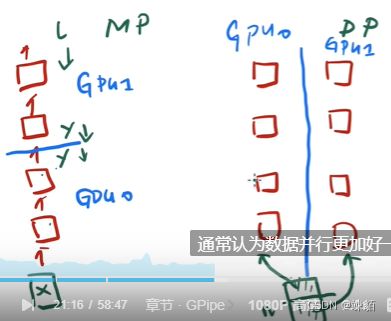
流水线并行:把数据切开,并行执行
megatron LM:Training Multi-Billion Parameter Language Models Using Model Parallelism
(系统方向)