计算机视觉人体骨骼点动作识别-1.训练自己的关键点检测模型
人体关键点检测算法
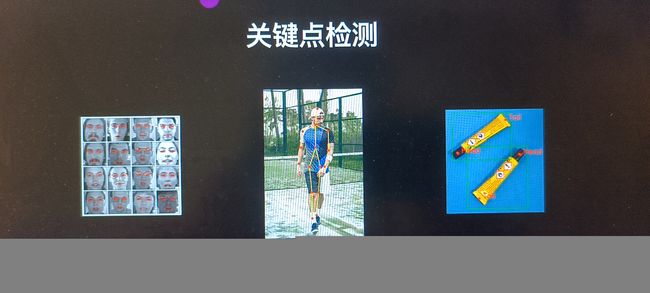
关键点并不特指人体骨骼关键点,还有人脸关键点,物体的关键点。其中人体的关键点,也叫作pose Estimation,是最热门,也是最有难度,应用最广的。

应用可以包括:行为识别,人机交互,智能家居,虚拟现实。
具体细分下来可以分为:单人/多人,2D/3D。
关键点检测算法,总体分为3类
- 方法1:基于坐标(coordinate)

- 方法2:基于概率图(heatmap)

- 方法3:基于heatmap和offset(偏移)

单人2D关键点检测算法

多人2D关键点检测算法

自上而下精度高。自下而上速度快。


3D关键点检测算法

训练自己的关键点检测模型
我们实际上做的是单人的行为识别,但是配合yolo可以实现多人的检测。
采集数据集
注意:数据集中的衣服跟实际推理时候的衣服不一样都会影响效果。
工业场景下,使用高精度的动作捕捉服获得样本。我们是用mediapipe或者open pose来获得样本即可。python使用3.7版本,因为windows环境下,我们的动作捕捉脚本不支持3.8.
conda的环境要求:
- python==3.7
- pytorch根据自己的cuda版本匹配(nvcc --version 看cuda版本)
- mediapipe(只能使用pip安装)
- yolov5
- pandas
"""
使用MP采集各种人体姿态训练素材
保存姿态图片,以及
"""
import torch
import cv2
import numpy as np
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
import time
class Mpkeypoints:
"""
获取人体Pose关键点
"""
def __init__(self):
self.mp_pose = mp.solutions.pose
self.pose = self.mp_pose.Pose(min_detection_confidence=0.5,min_tracking_confidence=0.5)
self.save_count = 1
def getFramePose(self,image):
"""
获取关键点
"""
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = self.pose.process(image)
return results.pose_landmarks,self.mp_pose.POSE_CONNECTIONS,results
def landmark_to_csv(self,frame,frame_index):
"""
获取特征
1.获取6个关键点
2.特征保存到CSV文件、原图、渲染图保存到文件夹
"""
frame_copy = frame.copy()
frame_h,frame_w= frame_copy.shape[:2]
# 获取关键点
pose_landmarks,conns,results = self.getFramePose(frame)
# 判断画面中是否有关键点:
if pose_landmarks:
p_list = [[landmark.x,landmark.y] for landmark in pose_landmarks.landmark[11:17]]
# 转为numpy,才能广播计算
p_list = np.asarray(p_list)
# 原图上绘制
resize_points = []
for x,y in p_list:
p_x = int(x * frame_w)
p_y = int(y * frame_h)
cv2.circle(frame_copy,(p_x,p_y),10,(0,255,0),-1)
resize_points.append(x)
resize_points.append(y)
# 每隔5帧保存
if frame_index % 2 == 0:
# 保存原始图片
file_name = './data/pose/raw/raw_{}.jpg'.format(frame_index)
cv2.imwrite(file_name,frame)
# 保存渲染图
file_name = './data/pose/render/rend_{}.jpg'.format(frame_index)
cv2.imwrite(file_name,frame_copy)
# 保存关键点
file_name = './data/pose/txt/frame_{}.txt'.format(frame_index)
with open(file_name,'w') as f:
for p in resize_points:
f.write('%s\n' % p)
print('成功保存:第{}帧,共保存了{}个'.format(frame_index,self.save_count))
self.save_count +=1
return frame_copy
class Pose_detect:
def __init__(self):
# 加载模型
self.model = torch.hub.load('./yolov5', 'custom', path='./weights/yolov5m.pt',source='local') # local repo
# 置信度阈值
self.model.conf = 0.4
# 加载摄像头
self.cap = cv2.VideoCapture(0)
# 画面宽度和高度
self.frame_w = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.frame_h = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 关键点检测
self.mp_keypoints = Mpkeypoints()
def detect(self):
# 帧数
frame_index = 4000
while True:
ret,frame = self.cap.read()
if frame is None:
break
# 转为RGB
img_cvt = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 推理
results = self.model(img_cvt)
pd = results.pandas().xyxy[0]
person_list = pd[pd['name']=='person'].to_numpy()
# 遍历每辆车
for person in person_list:
l,t,r,b = person[:4].astype('int')
frame_crop = frame[t:b,l:r]
# 关键点检测
frame_back = self.mp_keypoints.landmark_to_csv(frame_crop,frame_index)
cv2.rectangle(frame, (l,t), (r,b), (0,255,0),5)
# cv2.putText(frame, str(r-l), (l,t-10), cv2.FONT_HERSHEY_PLAIN, 10, (0,255,0),5)
cv2.imshow('demo',frame_back)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
frame_index +=1
self.cap.release()
cv2.destroyAllWindows()
plate = Pose_detect()
plate.detect()
训练模型
我们做的是行为识别方法一的实现方式,最后训练猫狗的模型,识别猫狗行为也是可以的。
安装jupterlab:pip install jupyterlab 如果用着用着崩了,重启一下就好了。