Tensorrt实现solov2加速
Tensorrt实现solov2加速
- SOLO简介
- 环境依赖
- 快速开始
-
- 转换pytorch模型
- 生成FP16模型并执行推理
-
- 第一版程序,使用pycuda
- 第二版程序,不使用pycuda
- 测试效果
SOLO简介
solo系列网络是由Xinlong Wang提出的单阶段实例分割网络。其搭建在mmdetection库中。solov2主干网络如下图所示:
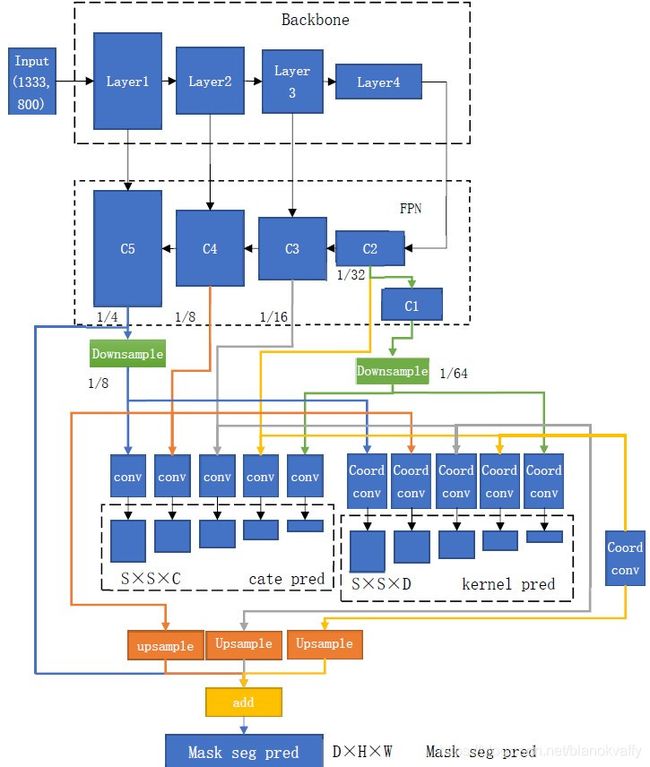
其在COCO数据集上获得了较高的AP,并且由于其单阶段实例分割的特点,方面直接实现端到端的部署。因此,我们可以采用pytorch转onnx再转tensorrt的方式实现solo的半精度、int8加速,达到实时运行的目的。
环境依赖
我们采用TensorRT7.1的部署环境(TensorRT 7.0的instance normalization层存在bug,造成推理结果不正确,参见gihub该问题的讨论)。具体测试环境如下:
Ubuntu 18.04
opencv 4
CUDA 10.1
TensorRT 7.1.3
pytorch 1.3
快速开始
以下代码展示了如何利用tensorrt的python接口快速进行pytorch到onnx模型的转换,大家也可以去我的github上下载。
转换pytorch模型
根据以下脚本将pytorch模型转化为onnx模型:
import argparse
import mmcv
import torch
from mmcv.runner import load_checkpoint
import torch.nn.functional as F
from mmdet.models import build_detector
import cv2
import torch.onnx as onnx
import numpy as np
import torch.nn as nn
numclass=80
def points_nms(heat, kernel=2):
# kernel must be 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=1)
keep = (hmax[:, :, :-1, :-1] == heat).float()
return heat * keep
def fpn_forward(self, inputs):
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# build top-down path
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
sh = torch.tensor(laterals[i].shape)
laterals[i - 1] += F.interpolate(
laterals[i], size=(sh[2]*2,sh[3]*2), mode='nearest')
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
# part 2: add extra levels
if self.num_outs > len(outs):
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.extra_convs_on_inputs:
orig = inputs[self.backbone_end_level - 1]
outs.append(self.fpn_convs[used_backbone_levels](orig))
else:
outs.append(self.fpn_convs[used_backbone_levels](outs[-1]))
for i in range(used_backbone_levels + 1, self.num_outs):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
return tuple(outs)
def forward_single(self, x, idx, eval=False, upsampled_size=None): # bbox head
ins_kernel_feat = x
y_range = np.linspace(-1, 1, ins_kernel_feat.shape[-1],dtype=np.float32)#h
x_range = np.linspace(-1, 1, ins_kernel_feat.shape[-2],dtype=np.float32)#w
x, y = np.meshgrid(y_range, x_range)
y = y[None][None]
x = x[None][None]
coord_feat =np.concatenate([x, y], 1)
coord_feat__ = torch.tensor(coord_feat)
seg_num_grid = self.seg_num_grids[idx]
cate_feat = F.interpolate(ins_kernel_feat, size=seg_num_grid, mode='bilinear')
#ins_kernel_feat = torch.cat([ins_kernel_feat, coord_feat], 1)
kernel_feat = torch.cat([ins_kernel_feat, coord_feat__], 1)
# kernel branch
kernel_feat = F.interpolate(kernel_feat, size=seg_num_grid, mode='bilinear')
kernel_feat = kernel_feat.contiguous()
for i, kernel_layer in enumerate(self.kernel_convs):
kernel_feat = kernel_layer.conv(kernel_feat)
num_group = torch.tensor(kernel_layer.gn.num_groups)
sh = torch.tensor(kernel_feat.shape)
kernel_feat = kernel_feat.view(1,num_group,-1)
insta_weight = torch.ones(num_group)
insta_bias = torch.zeros(num_group)
kernel_feat = F.instance_norm(kernel_feat,weight=insta_weight)
kernel_feat = kernel_feat.view(sh[0],sh[1],sh[2],sh[3])
gn_weight = kernel_layer.gn.weight.data.view(1,-1,1,1)
gn_bias = kernel_layer.gn.bias.data.view(1,-1,1,1)
kernel_feat = gn_weight*kernel_feat
kernel_feat = gn_bias+kernel_feat
kernel_feat = F.relu(kernel_feat)
#kernel_feat = kernel_layer(kernel_feat)
kernel_pred = self.solo_kernel(kernel_feat)
# cate branch
cate_feat = cate_feat.contiguous()
for i, cate_layer in enumerate(self.cate_convs):
cate_feat = cate_layer.conv(cate_feat)
num_group = torch.tensor(cate_layer.gn.num_groups)
sh = torch.tensor(cate_feat.shape)
cate_feat = cate_feat.view(1,num_group,-1)
insta_weight = torch.ones(num_group)
insta_bias = torch.zeros(num_group)
cate_feat = F.instance_norm(cate_feat,weight=insta_weight)
cate_feat = cate_feat.view(sh[0],sh[1],sh[2],sh[3])
gn_weight = cate_layer.gn.weight.data.view(1,-1,1,1)
gn_bias = cate_layer.gn.bias.data.view(1,-1,1,1)
cate_feat = gn_weight*cate_feat
cate_feat = gn_bias+cate_feat
cate_feat = F.relu(cate_feat)
#cate_feat = cate_layer(cate_feat)
cate_pred = self.solo_cate(cate_feat)
if eval:
cate_pred = points_nms(cate_pred.sigmoid(), kernel=2).permute(0, 2, 3, 1)
return cate_pred, kernel_pred
def split_feats(self, feats):
sh1 = torch.tensor(feats[0].shape)
sh2 = torch.tensor(feats[3].shape)
return (F.interpolate(feats[0], size=(int(sh1[2]*0.5),int(sh1[3]*0.5)), mode='bilinear'), #从da到xiao
feats[1],
feats[2],
feats[3],
F.interpolate(feats[4], size=(sh2[2],sh2[3]), mode='bilinear'))
def reshap_gn_mask_nead(layer,inputs):
inputs = layer.conv(inputs)
num_group = torch.tensor(layer.gn.num_groups)
sh = torch.tensor(inputs.shape)
inputs = inputs.view(1,num_group,-1)
insta_weight = torch.ones(num_group)
insta_bias = torch.zeros(num_group)
inputs = F.instance_norm(inputs,weight=insta_weight)
inputs = inputs.view(sh[0],sh[1],sh[2],sh[3])
gn_weight = layer.gn.weight.data.view(1,-1,1,1)
gn_bias = layer.gn.bias.data.view(1,-1,1,1)
inputs = gn_weight*inputs
inputs = gn_bias+inputs
outputs = F.relu(inputs)
return outputs
def forward(self, inputs): #mask head
feature_add_all_level = reshap_gn_mask_nead(self.convs_all_levels[0].conv0,inputs[0])
x = reshap_gn_mask_nead(self.convs_all_levels[1].conv0,inputs[1])
sh = torch.tensor(x.shape)
feature_add_all_level += F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
x = reshap_gn_mask_nead(self.convs_all_levels[2].conv0,inputs[2])
sh = torch.tensor(x.shape)
x = F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
x = reshap_gn_mask_nead(self.convs_all_levels[2].conv1,x)
sh = torch.tensor(x.shape)
feature_add_all_level += F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
y_range = np.linspace(-1, 1, inputs[3].shape[-1],dtype=np.float32)#h
x_range = np.linspace(-1, 1, inputs[3].shape[-2],dtype=np.float32)#w
x, y = np.meshgrid(y_range, x_range)
y = y[None][None]
x = x[None][None]
coord_feat =np.concatenate([x, y], 1)
coord_feat__ = torch.tensor(coord_feat)
input_p = torch.cat([inputs[3], coord_feat__], 1)
x = reshap_gn_mask_nead(self.convs_all_levels[3].conv0,input_p)
sh = torch.tensor(x.shape)
x = F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
x = reshap_gn_mask_nead(self.convs_all_levels[3].conv1,x)
sh = torch.tensor(x.shape)
x = F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
x = reshap_gn_mask_nead(self.convs_all_levels[3].conv2,x)
sh = torch.tensor(x.shape)
feature_add_all_level += F.interpolate(x, size=(sh[2]*2,sh[3]*2), mode='bilinear')
feature_pred = reshap_gn_mask_nead(self.conv_pred[0],feature_add_all_level)
return feature_pred
def main_forward(self,x):
x = self.extract_feat(x)
outs = self.bbox_head(x, eval=True)
mask_feat_pred = self.mask_feat_head(
x[self.mask_feat_head.
start_level:self.mask_feat_head.end_level + 1])
cate_pred_list = [outs[0][i].view(-1, numclass) for i in range(5)]
kernel_pred_list = [
outs[1][i].squeeze(0).permute(1, 2, 0).view(-1, 256) for i in range(5)]
cate_pred_list = torch.cat(cate_pred_list, dim=0)
kernel_pred_list = torch.cat(kernel_pred_list, dim=0)
return (cate_pred_list,kernel_pred_list,mask_feat_pred)
def parse_args():
parser = argparse.ArgumentParser(description='get solo onnx model')
parser.add_argument('--config', help='test config file path')
parser.add_argument('--checkpoint', help='checkpoint file')
parser.add_argument('--outputname',help="output name")
parser.add_argument('--numclass', type=int,default=80)
parser.add_argument('--inputh', type=int,default=800)
parser.add_argument('--inputw', type=int,default=1344)
args = parser.parse_args()
return args
def main():
args = parse_args()
cfg = mmcv.Config.fromfile(args.config)
cfg.model.pretrained = None
cfg.data.test.test_mode = True
global numclass
# build the model and load checkpoint
model = build_detector(cfg.model, train_cfg=None, test_cfg=cfg.test_cfg)
from types import MethodType
model.bbox_head.forward_single = MethodType(forward_single,model.bbox_head)
model.bbox_head.split_feats = MethodType(split_feats,model.bbox_head)
model.mask_feat_head.forward = MethodType(forward,model.mask_feat_head)
model.neck.forward = MethodType(fpn_forward, model.neck)
img = torch.randn(1,3,args.inputh,args.inputw)
model.forward = MethodType(main_forward,model)
outs = model(img)
print(len(outs))
checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
outputname = ["output1","output2","output3"]
onnx.export(model,img,args.outputname,verbose=True,opset_version=10,input_names=["input"],output_names=outputname)
if __name__ == '__main__':
main()
生成FP16模型并执行推理
第一版程序,使用pycuda
import pycuda.driver as cuda
import pycuda.autoinit
import cv2
import os
import numpy as np
import tensorrt as trt
import time
import argparse
import torch
import torch.nn.functional as F
import numpy as np
seg_num_grids = [40,36,24,16,12]
self_strides = [8,8,16,32,32]
score_thr = 0.1
mask_thr = 0.5
max_per_img = 100
class_names = [] # 输入你模型要预测类的名字
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
class Preprocessimage(object):
def __init__(self,inszie):
self.inszie = inszie
def process(self,image_path):
start = time.time()
image = cv2.imread(image_path) # bgr rgb
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
H,W,_ = image.shape
img_metas = dict()
image = cv2.resize(image,self.inszie) # resize
img_metas["img_shape"] = image.shape
image_raw = cv2.cvtColor(image,cv2.COLOR_RGB2BGR)
image = image.transpose([2,0,1]) # chw
image = np.expand_dims(image,axis=0) # nchw
image = np.array(image,dtype=np.float32,order="C")
print("preprocess time {:.3f} ms".format((time.time()-start)*1000))
return image,image_raw,img_metas
def get_engine(onnx_path,engine_path,TRT_LOGGER,mode="fp16"):
# 如果有engine直接用,否则构建新的engine
def build_engine():
EXPLICIT_BATCH = 1<<(int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder,\
builder.create_network(EXPLICIT_BATCH) as network,\
trt.OnnxParser(network,TRT_LOGGER) as parser:
builder.max_workspace_size = 1<<30
builder.max_batch_size = 1
if mode=="fp16":
builder.fp16_mode = True
if not os.path.exists(onnx_path):
print("onnx file {} not found".format(onnx_path))
exit(0)
print("loading onnx file {} .....".format(onnx_path))
with open(onnx_path,'rb') as model:
print("Begining parsing....")
parser.parse(model.read())
print("completed parsing")
print("Building an engine from file {}".format(onnx_path))
network.get_input(0).shape = [1,3,800,1344]
engine = builder.build_cuda_engine(network)
print("completed build engine")
with open(engine_path,"wb") as f:
f.write(engine.serialize())
return engine
if os.path.exists(engine_path):
print("loading engine file {} ...".format(engine_path))
with open(engine_path,"rb") as f,\
trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine()
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
host_mem = cuda.pagelocked_empty(size,dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(device_mem))
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem,device_mem))
else:
outputs.append(HostDeviceMem(host_mem,device_mem))
return inputs,outputs,bindings,stream
def do_inference(context,bindings,inputs,outputs,stream,batch_size=1):
[cuda.memcpy_htod_async(inp.device,inp.host,stream) for inp in inputs]
context.execute_async_v2(bindings=bindings,stream_handle=stream.handle)
[cuda.memcpy_dtoh_async(out.host,out.device,stream) for out in outputs]
stream.synchronize()
return [out.host for out in outputs]
def matrix_nms(seg_masks, cate_labels, cate_scores, kernel='gaussian', sigma=2.0, sum_masks=None):
"""Matrix NMS for multi-class masks.
Args:
seg_masks (Tensor): shape (n, h, w)
cate_labels (Tensor): shape (n), mask labels in descending order
cate_scores (Tensor): shape (n), mask scores in descending order
kernel (str): 'linear' or 'gauss'
sigma (float): std in gaussian method
sum_masks (Tensor): The sum of seg_masks
Returns:
Tensor: cate_scores_update, tensors of shape (n)
"""
n_samples = len(cate_labels)
if n_samples == 0:
return []
if sum_masks is None:
sum_masks = seg_masks.sum((1, 2)).float()
seg_masks = seg_masks.reshape(n_samples, -1).float()
# inter.
inter_matrix = torch.mm(seg_masks, seg_masks.transpose(1, 0))
# union.
sum_masks_x = sum_masks.expand(n_samples, n_samples)
# iou.
iou_matrix = (inter_matrix / (sum_masks_x + sum_masks_x.transpose(1, 0) - inter_matrix)).triu(diagonal=1)
# label_specific matrix.
cate_labels_x = cate_labels.expand(n_samples, n_samples)
label_matrix = (cate_labels_x == cate_labels_x.transpose(1, 0)).float().triu(diagonal=1)
# IoU compensation
compensate_iou, _ = (iou_matrix * label_matrix).max(0)
compensate_iou = compensate_iou.expand(n_samples, n_samples).transpose(1, 0)
# IoU decay
decay_iou = iou_matrix * label_matrix
# matrix nms
if kernel == 'gaussian':
decay_matrix = torch.exp(-1 * sigma * (decay_iou ** 2))
compensate_matrix = torch.exp(-1 * sigma * (compensate_iou ** 2))
decay_coefficient, _ = (decay_matrix / compensate_matrix).min(0)
elif kernel == 'linear':
decay_matrix = (1-decay_iou)/(1-compensate_iou)
decay_coefficient, _ = decay_matrix.min(0)
else:
raise NotImplementedError
# update the score.
cate_scores_update = cate_scores * decay_coefficient
return cate_scores_update
def get_seg_single(cate_preds,
seg_preds,
kernel_preds,
img_metas):
img_shape = img_metas['img_shape']
# overall info.
h, w, _ = img_shape
featmap_size = seg_preds.size()[-2:]
upsampled_size_out = (featmap_size[0] * 4, featmap_size[1] * 4) #seg # 1344,800
# process.
inds = (cate_preds > score_thr)
cate_scores = cate_preds[inds]
if len(cate_scores) == 0:
return None
# cate_labels & kernel_preds
inds = inds.nonzero()
cate_labels = inds[:, 1]
kernel_preds = kernel_preds[inds[:, 0]] # 选择cate大于阈值对应的kernel
# trans vector.
size_trans = cate_labels.new_tensor(seg_num_grids).pow(2).cumsum(0) # tensor([1600, 2896, 3472, 3728, 3872])
strides = kernel_preds.new_ones(size_trans[-1]) # [1,1,1,1,....,1] # 3872 所有的s*s累加
n_stage = len(seg_num_grids) # 5
strides[:size_trans[0]] *= self_strides[0] # [8,8,8,8......,8] 前1600乘8
for ind_ in range(1, n_stage): #2,3,4,5
strides[size_trans[ind_-1]:size_trans[ind_]] *= self_strides[ind_] # self.strides[8, 8, 16, 32, 32]
strides = strides[inds[:, 0]] # 选择前坐标
# mask encoding.
I, N = kernel_preds.shape #( 选出的kernel,256)
kernel_preds = kernel_preds.view(I, N, 1, 1) # (out_channels,in_channe/groups,H,W)
seg_preds = F.conv2d(seg_preds, kernel_preds, stride=1).squeeze(0).sigmoid() #(选出的kernel,h,w)
# mask.
seg_masks = seg_preds > mask_thr
sum_masks = seg_masks.sum((1, 2)).float()
# filter.
keep = sum_masks > strides # 大于相对应的stride
if keep.sum() == 0:
return None
seg_masks = seg_masks[keep, ...]
seg_preds = seg_preds[keep, ...]
sum_masks = sum_masks[keep]
cate_scores = cate_scores[keep]
cate_labels = cate_labels[keep]
# mask scoring.
seg_scores = (seg_preds * seg_masks.float()).sum((1, 2)) / sum_masks
cate_scores *= seg_scores
# sort and keep top nms_pre
sort_inds = torch.argsort(cate_scores, descending=True)
if len(sort_inds) > max_per_img:
sort_inds = sort_inds[:max_per_img]
seg_masks = seg_masks[sort_inds, :, :]
seg_preds = seg_preds[sort_inds, :, :]
sum_masks = sum_masks[sort_inds]
cate_scores = cate_scores[sort_inds]
cate_labels = cate_labels[sort_inds]
# Matrix NMS
cate_scores = matrix_nms(seg_masks, cate_labels, cate_scores,
kernel='gaussian',sigma=2., sum_masks=sum_masks)
if seg_preds.shape[0]==1:
seg_preds = cv2.resize(seg_preds.permute(1,2,0).numpy(),
(upsampled_size_out[1],upsampled_size_out[0]))[:,:,None].transpose(2,0,1)
else:
seg_preds = cv2.resize(seg_preds.permute(1,2,0).numpy(),
(upsampled_size_out[1],upsampled_size_out[0])).transpose(2,0,1)
seg_masks = seg_masks > mask_thr
return seg_masks, cate_labels, cate_scores
def vis_seg(image_raw,result,score_thresh,output):
img_show = image_raw
seg_show1 = img_show.copy()
seg_show = img_show.copy()
if result==None:
cv2.imwrite(output,seg_show1)
else:
seg_label = result[0]
seg_label = seg_label.astype(np.uint8)
cate_label = result[1]
cate_label = cate_label.numpy()
score = result[2].numpy()
vis_inds = score > score_thresh
seg_label = seg_label[vis_inds]
num_mask = seg_label.shape[0]
cate_label = cate_label[vis_inds]
cate_score = score[vis_inds]
mask_density = []
for idx in range(num_mask):
cur_mask = seg_label[idx, :, :]
mask_density.append(cur_mask.sum())
orders = np.argsort(mask_density)
seg_label = seg_label[orders]
cate_label = cate_label[orders]
cate_score = cate_score[orders]
for idx in range(num_mask):
idx = -(idx + 1)
cur_mask = seg_label[idx, :, :]
if cur_mask.sum() == 0:
continue
color_mask = (np.random.randint(0,255),np.random.randint(0,255),np.random.randint(0,255))
contours,_ = cv2.findContours(cur_mask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
cv2.drawContours(seg_show,contours,-1,color_mask,-1)
cur_cate = cate_label[idx]
label_text = class_names[cur_cate]
x1,y1,w,h = cv2.boundingRect(cur_mask)
x2 = x1+w
y2 = y1+h
vis_pos = (max(int(x1)-10,0),int(y1))
cv2.rectangle(seg_show,(x1,y1),(x2,y2),(0,0,0),thickness=2)
cv2.putText(seg_show,label_text,vis_pos,cv2.FONT_HERSHEY_COMPLEX,1,(0,0,0))
seg_show1 = cv2.addWeighted(seg_show,0.7,img_show,0.5,0)
cv2.imwrite(output,seg_show1)
def main():
args = argparse.ArgumentParser(description="trt pose predict")
args.add_argument("--onnx_path",type=str,default="dense121.onnx")
args.add_argument("--engine_path",type=str,default="dense121fp16.trt")
args.add_argument("--image_path",type=str)
args.add_argument("--mode",type=str,default="fp16")
args.add_argument("--output",type=str,default="result.png")
args.add_argument("--classes", type=int, default=80)
args.add_argument("--score_thr", type=float, default=0.3)
opt = args.parse_args()
insize = (1344,800)
output_shape = [(1, 256, 200, 336),(3872,opt.classes),(3872,256)]
TRT_LOGGER = trt.Logger()
preprocesser = Preprocessimage(insize)
image, image_raw,img_metas = preprocesser.process(opt.image_path)
with get_engine(opt.onnx_path,opt.engine_path,TRT_LOGGER,opt.mode) as engine, \
engine.create_execution_context() as context:
inputs,outputs,bindings,stream = allocate_buffers(engine)
inputs[0].host = image
start = time.time()
trt_outputs = do_inference(context,bindings,inputs,outputs,stream)
end = time.time()
print("inference time {:.3f} ms".format((end-start)*1000))
start = time.time()
trt_outputs = [output.reshape(shape) for output ,shape in zip(trt_outputs,output_shape)]
trt_outputs = [torch.tensor(output) for output in trt_outputs]
cate_pred = trt_outputs[1]
kernel_pred = trt_outputs[2]
seg_pred = trt_outputs[0]
with torch.no_grad():
result = get_seg_single(cate_pred,kernel_pred,seg_pred,img_metas)
vis_seg(image_raw,result,opt.score_thr,opt.output)
print("post time {:.3f} ms".format((end - start) * 1000))
if __name__=="__main__":
main()
第二版程序,不使用pycuda
#!/usr/bin/env python3
import cv2
import os
import numpy as np
import tensorrt as trt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import Normalize
import time
import argparse
import torch
import torch.nn as nn
seg_num_grids = [40, 36, 24, 16, 12]
self_strides = [8, 8, 16, 32, 32]
score_thr = 0.1
mask_thr = 0.5
update_thr = 0.05
nms_pre =500
max_per_img = 100
class_num = 1000 # ins
colors = [(np.random.random((1, 3)) * 255).tolist()[0] for i in range(class_num)]
class_names = ["person", "bicycle", "car", "motorcycle", "airplane", "bus",
"train", "truck", "boat", "traffic_light", "fire_hydrant",
"stop_sign", "parking_meter", "bench", "bird", "cat", "dog",
"horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe",
"backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports_ball", "kite", "baseball_bat",
"baseball_glove", "skateboard", "surfboard", "tennis_racket",
"bottle", "wine_glass", "cup", "fork", "knife", "spoon", "bowl",
"banana", "apple", "sandwich", "orange", "broccoli", "carrot",
"hot_dog", "pizza", "donut", "cake", "chair", "couch",
"potted_plant", "bed", "dining_table", "toilet", "tv", "laptop",
"mouse", "remote", "keyboard", "cell_phone", "microwave",
"oven", "toaster", "sink", "refrigerator", "book", "clock",
"vase", "scissors", "teddy_bear", "hair_drier", "toothbrush"]
def torch_dtype_from_trt(dtype):
if dtype == trt.bool:
return torch.bool
elif dtype == trt.int8:
return torch.int8
elif dtype == trt.int32:
return torch.int32
elif dtype == trt.float16:
return torch.float16
elif dtype == trt.float32:
return torch.float32
else:
raise TypeError('%s is not supported by torch' % dtype)
def torch_device_to_trt(device):
if device.type == torch.device('cuda').type:
return trt.TensorLocation.DEVICE
elif device.type == torch.device('cpu').type:
return trt.TensorLocation.HOST
else:
return TypeError('%s is not supported by tensorrt' % device)
def torch_device_from_trt(device):
if device == trt.TensorLocation.DEVICE:
return torch.device('cuda')
elif device == trt.TensorLocation.HOST:
return torch.device('cpu')
else:
return TypeError('%s is not supported by torch' % device)
class Preprocessimage(object):
def __init__(self,inszie):
self.inszie = (inszie[3],inszie[2])
self.Normalize = Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225] )
def process(self,image_path):
start = time.time()
image = cv2.imread(image_path)#[...,::-1] # bgr rgb
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
img_metas = dict()
H,W,_ = image.shape
image = cv2.resize(image,self.inszie) #10ms
new_H,new_W,_ = image.shape
img_metas["img_shape"] = image.shape
image_raw = cv2.cvtColor(image,cv2.COLOR_RGB2BGR)
image = torch.form_numpy(image).float().cuda()
image = image.permute(2,0,1) # chw
image = self.Normalize(image/255.)
image = image.unsqueeze(0)
return image,image_raw,img_metas
class TRT_model(nn.Module):
def __init__(self,
input_size,
onnx_path,
engine_path,
mode="fp16"):
super(TRT_model, self).__init__()
self._register_state_dict_hook(TRT_model._on_state_dict)
self.TRT_LOGGER = trt.Logger()
self.onnx_path = onnx_path
self.engine_path = engine_path
self.input_size = input_size
self.mode = mode
if os.path.exists(engine_path):
print("loading engine file {} ...".format(engine_path))
trt.init_libnvinfer_plugins(self.TRT_LOGGER,"")
with open(engine_path,"rb") as f,\
trt.Runtime(self.TRT_LOGGER) as runtime:
self.engine = runtime.deserialize_cuda_engine(f.read())
else:
self.engine = self.build_engine()
self.context = self.engine.create_execution_context()
def _on_state_dict(self, state_dict, prefix, local_metadata):
state_dict[prefix + 'engine'] = bytearray(self.engine.serialize())
def build_engine(self):
EXPLICIT_BATCH = 1<<(int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(self.TRT_LOGGER) as builder,\
builder.create_network(EXPLICIT_BATCH) as network,\
trt.OnnxParser(network,self.TRT_LOGGER) as parser:
builder.max_workspace_size =1<<20
builder.max_batch_size = 1
if self.mode =="fp16":
print("build fp16 mode")
builder.fp16_mode = True
if not os.path.exists(self.onnx_path):
print("onnx file {} not found".format(self.onnx_path))
exit(0)
print("loading onnx file {} .....".format(self.onnx_path))
with open(self.onnx_path,'rb') as model:
print("Begining parsing....")
parser.parse(model.read())
print("completed parsing")
print("Building an engine from file {}".format(self.onnx_path))
network.get_input(0).shape = self.input_size
engine = builder.build_cuda_engine(network)
print("completed build engine")
with open(self.engine_path,"wb") as f:
f.write(engine.serialize())
return engine
def forward(self,inputs):
#start = time.time()
bindngs = [None]*(1+3)
bindngs[0]= inputs.contiguous().data_ptr()
outputs = [None]*3
for i in range(1,4):
output_shape = tuple(self.context.get_binding_shape(i))
dtype = torch_dtype_from_trt(self.engine.get_binding_dtype(i))
device = torch_device_from_trt(self.engine.get_location(i))
output = torch.empty(size=output_shape,dtype=dtype,device=device)
outputs[i-1] = output
bindngs[i] = output.data_ptr()
self.context.execute_async_v2(bindngs,
torch.cuda.current_stream().cuda_stream)
cate_preds = outputs[1]
kernel_preds = outputs[2]
seg_pred = outputs[0]
result = get_seg_single(cate_preds,kernel_preds,seg_pred)
#print("conv2d time {:.3f} ms".format((time.time() - start) * 1000))
return result
def get_seg_single(cate_preds,
kernel_preds,
seg_preds
):
# process.
inds = (cate_preds > 0.1) # 选出类
cate_scores = cate_preds[inds]
if len(cate_scores) == 0:
return None
# cate_labels & kernel_preds
inds = inds.nonzero()
cate_labels = inds[:, 1]
kernel_preds = kernel_preds[inds[:, 0]]
# trans vector.
#print(seg_num_grids)
size_trans = cate_labels.new_tensor(seg_num_grids).pow(2).cumsum(0)
strides = kernel_preds.new_ones(size_trans[-1])# 3872个1
n_stage = len(seg_num_grids)
strides[:size_trans[0]] *= self_strides[0]
for ind_ in range(1, n_stage):
strides[size_trans[ind_-1]:size_trans[ind_]] *= self_strides[ind_]
strides = strides[inds[:, 0]] # [8.8.8.]
# mask encoding.
I, N = kernel_preds.shape
kernel_preds = kernel_preds.view(I, N, 1, 1)
seg_preds = F.conv2d(seg_preds, kernel_preds, stride=1).squeeze(0).sigmoid() # 得到 seg 3维 9ms
#print("conv2d time {:.3f} ms".format((time.time() - start) * 1000))
# mask.
#seg_masks = seg_preds > mask_thr
seg_masks = seg_preds > 0.5 # 大于阈值 # bool
sum_masks = seg_masks.sum((1, 2)).float()
# filter.
keep = sum_masks > strides # 大于 seg的大小要大于strides
if keep.sum() == 0:
return None
seg_masks = seg_masks[keep, ...] # bool
seg_preds = seg_preds[keep, ...]
sum_masks = sum_masks[keep]
cate_scores = cate_scores[keep]
cate_labels = cate_labels[keep]
# mask scoring.
seg_scores = (seg_preds * seg_masks.float()).sum((1, 2)) / sum_masks
cate_scores *= seg_scores # 得分相乘 得到 置信度
# sort and keep top nms_pre
sort_inds = torch.argsort(cate_scores, descending=True) # 按得分高低进行排列
if len(sort_inds) > max_per_img: # 取前100个
sort_inds = sort_inds[:max_per_img]
seg_masks = seg_masks[sort_inds, :, :]
seg_preds = seg_preds[sort_inds, :, :]
sum_masks = sum_masks[sort_inds]
cate_scores = cate_scores[sort_inds]
cate_labels = cate_labels[sort_inds]
# Matrix NMS
cate_scores = matrix_nms(seg_masks, cate_labels, cate_scores,
kernel='gaussian',sigma=2.0, sum_masks=sum_masks) #
return seg_preds, cate_labels, cate_scores
def matrix_nms(seg_masks, cate_labels, cate_scores, kernel='gaussian', sigma=2.0, sum_masks=None):
"""Matrix NMS for multi-class masks.
Args:
seg_masks (Tensor): shape (n, h, w)
cate_labels (Tensor): shape (n), mask labels in descending order
cate_scores (Tensor): shape (n), mask scores in descending order
kernel (str): 'linear' or 'gauss'
sigma (float): std in gaussian method
sum_masks (Tensor): The sum of seg_masks
Returns:
Tensor: cate_scores_update, tensors of shape (n)
"""
n_samples = len(cate_labels)
if n_samples == 0:
return []
if sum_masks is None:
sum_masks = seg_masks.sum((1, 2)).float()
seg_masks = seg_masks.reshape(n_samples, -1).float()
# inter.
inter_matrix = torch.mm(seg_masks, seg_masks.transpose(1, 0))
# union.
sum_masks_x = sum_masks.expand(n_samples, n_samples)
# iou.
iou_matrix = (inter_matrix / (sum_masks_x + sum_masks_x.transpose(1, 0) - inter_matrix)).triu(diagonal=1)
# label_specific matrix.
cate_labels_x = cate_labels.expand(n_samples, n_samples)
label_matrix = (cate_labels_x == cate_labels_x.transpose(1, 0)).float().triu(diagonal=1)
# IoU compensation
compensate_iou, _ = (iou_matrix * label_matrix).max(0)
compensate_iou = compensate_iou.expand(n_samples, n_samples).transpose(1, 0)
# IoU decay
decay_iou = iou_matrix * label_matrix
# matrix nms
if kernel == 'gaussian':
decay_matrix = torch.exp(-1 * sigma * (decay_iou ** 2))
compensate_matrix = torch.exp(-1 * sigma * (compensate_iou ** 2))
decay_coefficient, _ = (decay_matrix / compensate_matrix).min(0)
elif kernel == 'linear':
decay_matrix = (1-decay_iou)/(1-compensate_iou)
decay_coefficient, _ = decay_matrix.min(0)
else:
raise NotImplementedError
# update the score.
cate_scores_update = cate_scores * decay_coefficient
return cate_scores_update
def vis_seg(image_raw, result, score_thresh, output):
img_show = image_raw # no pad
seg_show = img_show.copy()
ori_h,ori_w,_ = image_raw.shape
if result!=None:
seg_label = result[0].cpu().numpy() # seg
output_scale = [ ori_w/seg_label.shape[2] , ori_h/seg_label.shape[1] ]
#seg_label = seg_label.astype(np.uint8) # 变成int8
cate_label = result[1] # cate_label
cate_label = cate_label.cpu().numpy()
score = result[2].cpu().numpy() # cate_scores
vis_inds = score > score_thresh # 大于0.3
seg_label = seg_label[vis_inds]
num_mask = seg_label.shape[0]
cate_label = cate_label[vis_inds]
cate_score = score[vis_inds]
for idx in range(num_mask):
mask = seg_label[idx, :,:]
# cur_mask = cv2.resize(cur_mask,(ori_w,ori_h))
cur_mask = (mask> mask_thr).astype(np.uint8)
if cur_mask.sum() == 0:
continue
mask_roi = cv2.boundingRect(cur_mask)
draw_roi = (int(output_scale[0]*mask_roi[0]),int(output_scale[1]*mask_roi[1]),
int(output_scale[0]*mask_roi[2]),int(output_scale[1]*mask_roi[3]))
now_mask = cv2.resize(mask[mask_roi[1]:mask_roi[1]+mask_roi[3],mask_roi[0]:mask_roi[0]+mask_roi[2]],(draw_roi[2],draw_roi[3]))
now_mask = (now_mask> mask_thr).astype(np.uint8)
color_mask = (np.random.randint(0,255),np.random.randint(0,255),np.random.randint(0,255))
contours,_ = cv2.findContours(now_mask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
draw_roi_mask = seg_show[ draw_roi[1]:draw_roi[1]+ draw_roi[3] , draw_roi[0]:draw_roi[0]+ draw_roi[2] ,:]
cv2.drawContours(draw_roi_mask,contours,-1,color_mask,2)
cur_cate = cate_label[idx]
cur_score = cate_score[idx]
label_text = class_names[cur_cate]
vis_pos = (max(int(draw_roi[0]) - 10, 0), int(draw_roi[1])) #1ms
#vis_pos = (max(int(center_x) - 10, 0), int(center_y)) #1ms
cv2.rectangle(seg_show,(draw_roi[0],draw_roi[1]),(draw_roi[0]+ draw_roi[2],draw_roi[1]+ draw_roi[3]),(0,0,0),thickness=2)
cv2.putText(seg_show, label_text, vis_pos,
cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0)) # green 0.1ms
cv2.imwrite(output,seg_show)
def main():
args = argparse.ArgumentParser(description="trt pose predict")
args.add_argument("--onnx_path",type=str)
args.add_argument("--engine_path",type=str)
args.add_argument("--image_path",type=str,default="demo/demo.jpg")
args.add_argument("--mode",type=str,default="fp16")
args.add_argument('--score_thr', type=float, default=0.3, help='score threshold for visualization')
args.add_argument("--output",type=str,default="result.jpg")
opt = args.parse_args()
insize = [1,3,800,1344]
model = TRT_model(insize,opt.onnx_path,opt.engine_path)
preprocesser = Preprocessimage(insize)
############start inference##############
image, image_raw,img_metas = preprocesser.process(opt.image_path)
with torch.no_grad():
result = model(image)
vis_seg(image_raw, result, score_thresh=opt.score_thr, output=opt.output)
if __name__=="__main__":
main()
测试效果

| Model | GPU | Mode | Inference |
|---|---|---|---|
| R101 | V100 | fp16 | 35ms |
| R101 | xavier | fp16 | 150ms |
可见,经过fp16加速过的模型仍然很慢,毕竟输入图片的大小很大(1344*800),网络参数也不小,而且画出的后处理函数vis_seg耗时巨大(c++版的后处理可以将时间降低很多)。实际上距离工程应用仍然比较远,需要在模型结构优化下比较大的功夫。