2月跨模态(图片-文本)论文粗览
2月跨模态(图片-文本)论文粗览
- 总体情况
-
- 《A Case Study of the Shortcut Effects in Visual Commonsense Reasoning》
- 《Simple is Not Easy: A Simple Strong Baseline for TextVQA and TextCaps》
- 《Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling》
- 《Efficient Object-Level Visual Context Modeling for Multimodal Machine Translation: Masking Irrelevant Objects Helps Grounding》
- 《Imagine, Reason and Write: Visual Storytelling with Graph Knowledge and Relational Reasoning》
- 《Learning Visual Context for Group Activity Recognition》
- 《Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance》
- 《Regularizing Attention Networks for Anomaly Detection in Visual Question Answering》
- 《Visual Concept Reasoning Networks》
- 《Visual Pivoting for (Unsupervised) Entity Alignment》
- 《Visual Relation Detection using Hybrid Analogical Learning》
- 《VisualMRC: Machine Reading Comprehension on Document Images》
总体情况
选自AAAI2021,很粗糙地浏览了一遍,一共发现了大概12篇。目前多模态有很多细节的任务,视觉故事讲述方面比较热门。
《A Case Study of the Shortcut Effects in Visual Commonsense Reasoning》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-9821.YeK.pdf
作者:Keren Ye, Adriana Kovashka
单位/机构:University of Pittsburgh, Pittsburgh PA 15260, USA

Abstract:Visual reasoning and question-answering have gathered attention in recent years. Many datasets and evaluation protocols have been proposed; some have been shown to contain bias that allows models to “cheat” without performing true, generalizable reasoning. A well-known bias is dependence on language priors (frequency of answers) resulting in the model not looking at the image. We discover a new type of bias in the Visual Commonsense Reasoning (VCR) dataset. In particular we show that most state-of-the-art models exploit co-occurring text between input (question) and output (answer options), and rely on only a few pieces of information in the candidate options, to make a decision. Unfortunately, relying on such superficial evidence causes models to be very fragile. To measure fragility, we propose two ways to modify the validation data, in which a few words in the answer choices are modified without significant changes in meaning. We find such insignificant changes cause models’ performance to degrade significantly. To resolve the issue, we propose a curriculum-based masking approach, as a mechanism to perform more robust training. Our method improves the baseline by requiring it to pay attention to the answers as a whole, and is more effective than prior masking strategies. Our code and data are available at https://github.com/yekeren/VCR-shortcut-effects-study.
作者在视觉常识推理(VCR)中发现一个bias:模型倾向于选择和问题相似度高的答案,即如果选项中出现了越多的问题中的单词,那么该选项越有可能是答案。这篇文章使用的基础模型是跨模态的BERT。作者提出两个方法来评估这种bias:1基于规则:把ground-truth答案中的标签词换成指示代词。2对抗性:把ground-truth答案中的某个单词mask。作者使用课程学习的方式逐渐减少训练过程中的mask数量,来解决这个bias。
《Simple is Not Easy: A Simple Strong Baseline for TextVQA and TextCaps》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-5036.ZhuQ.pdf
作者:Qi Zhu, Chenyu Gao, Peng Wang, Qi Wu
单位/机构:School of Computer Science, Northwestern Polytechnical University, Xi’an, China
School of Software, Northwestern Polytechnical University, Xi’an, China
National Engineering Laboratory for Integrated Aero-Space-Ground-Ocean Big Data Application Technology, China
University of Adelaide, Australia

Abstract: Texts appearing in daily scenes that can be recognized by OCR (Optical Character Recognition) tools contain significant information, such as street name, product brand and prices. Two tasks – text-based visual question answering and text-based image captioning, with a text extension from existing vision-language applications, are catching on rapidly. To address these problems, many sophisticated multi-modality encoding frameworks (such as heterogeneous graph structure) are being used. In this paper, we argue that a simple attention mechanism can do the same or even better job without any bells and whistles. Under this mechanism, we simply split OCR token features into separate visual- and linguistic-attention branches, and send them to a popular Transformer decoder to generate answers or captions. Surprisingly, we find this simple baseline model is rather strong – it consistently outperforms state-of-the-art (SOTA) models on two popular benchmarks, TextVQA and all three tasks of ST-VQA, although these SOTA models use far more complex encoding mechanisms. Transferring it to text-based image captioning, we also surpass the TextCaps Challenge 2020 winner. We wish this work to set the new baseline for these two OCR text related applications and to inspire new thinking of multi-modality encoder design. Code is available at https://github.com/ZephyrZhuQi/ssbaseline
本文提出了在基于文本的视觉问答和图像字幕方面给一个简单但是强大的模型。该模型在注意力机制的基础上,把对字符的处理分成图像和语言两个部分,分开输入到transformer模型中。该方法很简单但是效果很好。
《Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-5111.ChenH.pdf
作者:Hong Chen, Yifei Huang, Hiroya Takamura, Hideki Nakayama
单位/机构:The University of Tokyo, Tokyo Institute of Technology,National Institute of Advanced Industrial Science and Technology, Japan
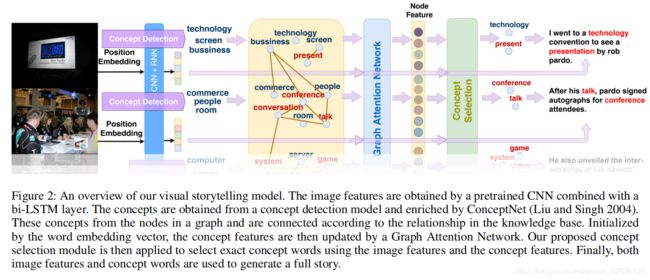
Abstract:Visual storytelling is a task of generating relevant and interesting stories for given image sequences. In this work we aim at increasing the diversity of the generated stories while preserving the informative content from the images. We propose to foster the diversity and informativeness of a generated story by using a concept selection module that suggests a set of concept candidates. Then, we utilize a large scale pre-trained model to convert concepts and images into full stories. To enrich the candidate concepts, a commonsense knowledge graph is created for each image sequence from which the concept candidates are proposed. To obtain appropriate concepts from the graph, we propose two novel modules that consider the correlation among candidate concepts and the image-concept correlation. Extensive automatic and human evaluation results demonstrate that our model can produce reasonable concepts. This enables our model to outperform the previous models by a large margin on the diversity and informativeness of the story, while retaining the relevance of the story to the image sequence.
本文解决的主要任务是视觉故事讲述,类似于image caption。为了丰富故事的多样性,作者加入了常识图。首先是使用RNN+CNN提取出图片上的特征,使用concept detection来得到图片上的concept。然后提取和concept有关的常识图的内容,再利用图注意力网络把图片信息和concept信息融合,得到节点的向量,作为更新后的concept信息。作者使用concept之间的注意力和concept与image之间的注意力构建图的边,最后根据图得到描述。
《Efficient Object-Level Visual Context Modeling for Multimodal Machine Translation: Masking Irrelevant Objects Helps Grounding》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-1370.WangD.pdf
作者:Dexin Wang, Deyi Xiong
单位/机构:College of Intelligence and Computing, Tianjin University
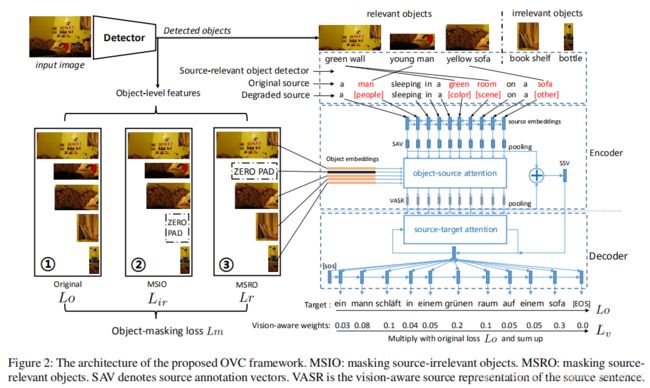
Abstract:Visual context provides grounding information for multimodal machine translation (MMT). However, previous MMT models and probing studies on visual features suggest that visual information is less explored in MMT as it is often redundant to textual information. In this paper, we propose an object-level visual context modeling framework (OVC) to efficiently capture and explore visual information for multimodal machine translation. With detected objects, the proposed OVC encourages MMT to ground translation on desirable visual objects by masking irrelevant objects in the visual modality. We equip the proposed with an additional object-masking loss to achieve this goal. The object-masking loss is estimated according to the similarity between masked objects and the source texts so as to encourage masking source-irrelevant objects. Additionally, in order to generate vision-consistent target words, we further propose a vision-weighted translation loss for OVC. Experiments on MMT datasets demonstrate that the proposed OVC model outperforms state-of-the-art MMT models and analyses show that masking irrelevant objects helps grounding in MMT.
本文是一个遮盖单词的跨模态机器翻译任务。本文的基础模型是GRU的编解码模型,中间加入了跨模态的过程。主要的创新点在于在编码的过程中加入了跨模态的注意力机制和在训练中加入了掩盖object的任务,损失函数更加丰富。
《Imagine, Reason and Write: Visual Storytelling with Graph Knowledge and Relational Reasoning》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-3382.XuC.pdf
作者:Chunpu Xu, Chengming Li, Ying Shen, Xiang Ao, Ruifeng Xu, Min Yang
单位/机构:Shenzhen Key Laboratory for High Performance Data Mining,
Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
School of Intelligent Systems Engineering, Sun Yat-Sen University
Institute of Computing Technology, Chinese Academy of Sciences
Harbin Institute of Technology (Shenzhen)
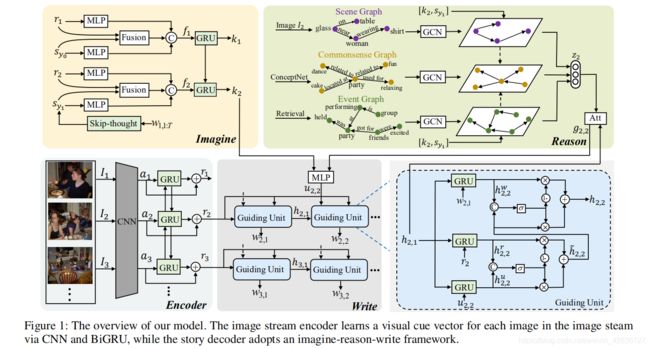
Abstract:Visual storytelling is a task of creating a short story based on photo streams. Different from visual captions, stories contain not only factual descriptions, but also imaginary concepts that do not appear in the images. In this paper, we propose a novel imagine-reason-write generation framework (IRW) for visual storytelling, inspired by the logic of humans when they write the story. First, an imagine module is leveraged to learn the imaginative storyline explicitly, improving the coherence and reasonability of the generated story. Second, we employ a reason module to fully exploit the external knowledge (commonsense knowledge base) and task-specific knowledge (scene graph and event graph) with relational reasoning method based on the storyline. In this way, we can effectively capture the most informative commonsense and visual relationships among objects in images, which enhances the diversity and informativeness of the generated story. Finally, we integrate the imaginary concepts and relational knowledge to generate human-like story based on the original semantics of images. Extensive experiments on a benchmark dataset (i.e., VIST) demonstrate that the proposed IRW framework significantly outperforms the state-of-the-art methods across multiple evaluation metrics.
本文的任务也是视觉故事讲述,在文章中,作者提出一个有推理和想象模块的模型。想象模块的输入是图片的特征+对图片的描述(文字),然后对这两个特征进行融合。推理模块是融合了场景图,常识图和事件图。最后输入到写作模块中,利用GRU得到最终的结果。
《Learning Visual Context for Group Activity Recognition》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-2633.YuanH.pdf
作者:Hangjie Yuan, Dong Ni
单位/机构:1College of Control Science and Engineering, Zhejiang University, Hangzhou, China
State Key Laboratory of Industrial Control Technology, Zhejiang University, Hangzhou, China
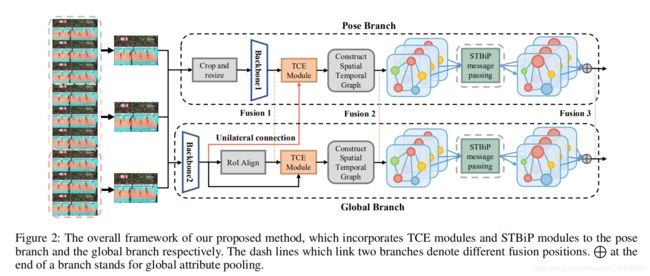
Abstract:Group activity recognition aims to recognize an overall activity in a multi-person scene. Previous methods strive to reason on individual features. However, they under-explore the person-specific contextual information, which is significant and informative in computer vision tasks. In this paper, we propose a new reasoning paradigm to incorporate global contextual information. Specifically, we propose two modules to bridge the gap between group activity and visual context. The first is Transformer based Context Encoding (TCE) module, which enhances individual representation by encoding global contextual information to individual features and refining the aggregated information. The second is Spatial-Temporal Bilinear Pooling (STBiP) module. It firstly further explores pairwise relationships for the context encoded individual representation, then generates semantic representations via gated message passing on a constructed spatial-temporal graph. On their basis, we further design a two-branch model that integrates the designed modules into a pipeline. Systematic experiments demonstrate each module’s effectiveness on either branch. Visualizations indicate that visual contextual cues can be aggregated globally by TCE. Moreover, our method achieves state-of-the-art results on two widely used benchmarks using only RGB images as input and 2D backbones.
本文是从视频中识别群体活动。作者的方法主要是分成了pose和global两个分支。创新点在于每个分支里面都用到的TCE模块和STBiP模块。TCE模块主要是以attention的方式在每个个体的特征中加入全局特征,STBiP模块主要是根据每个个体的位置和特征来更新个体的特征。这篇没有跨模态,但是探索了图片中的内容和关系。
《Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-2753.ZhangD.pdf
作者:Dong Zhang, Suzhong Wei, Shoushan Li, Hanqian Wu, Qiaoming Zhu, Guodong Zhou1
单位/机构:School of Computer Science and Technology, Soochow University, China
School of Computer Science and Engineering, Southeast University, China
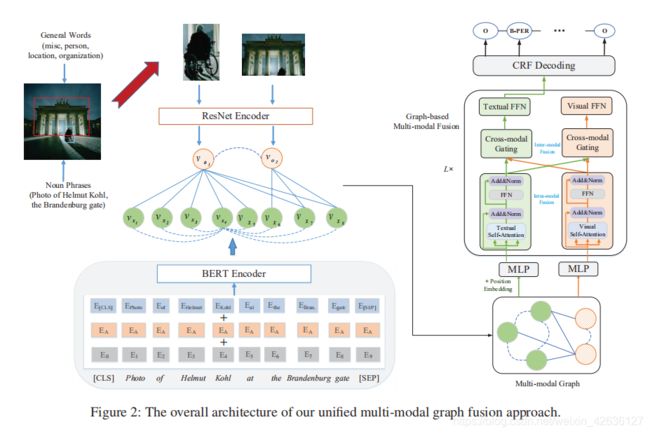
Abstract:Multi-modal named entity recognition (MNER) aims to discover named entities in free text and classify them into predefined types with images. However, dominant MNER models do not fully exploit fine-grained semantic correspondences between semantic units of different modalities, whichhave the potential to refine multi-modal representation learning. To deal with this issue, we propose a unified multi-modal graph fusion (UMGF) approach for MNER. Specifically, we first represent the input sentence and image using a unified multi-modal graph, which captures various semantic relationships between multi-modal semantic units (words and visual objects). Then, we stack multiple graph-based multi-modal fusion layers that iteratively perform semantic interactions to learn node representations. Finally, we achieve an attentionbased multi-modal representation for each word and perform entity labeling with a CRF decoder. Experimentation on the two benchmark datasets demonstrates the superiority of our MNER model.
这篇文章解决的是多模态实体辨别任务。首先使用BERT模型来提取单词特征,然后使用现有模型来根据句子提取出图中相应的内容,使用resnet网络编码图片信息。graph的点就是每个单词和提取出来的部分。inter-edge是与提取出来的部分有关的单词,intra-edge为全连接。然后使用attention将两个模态的图相混合,intra部分是attention机制,inter部分是不同模态的信息通过与权重相乘再相加的方式融合。在跨模态中是一个常见的方式。
《Regularizing Attention Networks for Anomaly Detection in Visual Question Answering》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-3951.LeeD.pdf
作者:Doyup Lee, Yeongjae Cheon, Wook-Shin Han
单位/机构:POSTECH, Kakao Brain

Abstract:For stability and reliability of real-world applications, the robustness of DNNs in unimodal tasks has been evaluated.
However, few studies consider abnormal situations that a visual question answering (VQA) model might encounter at test time after deployment in the real-world. In this study, we evaluate the robustness of state-of-the-art VQA models to five different anomalies, including worst-case scenarios, the most frequent scenarios, and the current limitation of VQA models. Different from the results in unimodal tasks, the maximum confidence of answers in VQA models cannot detect anomalous inputs, and post-training of the outputs, such as outlier exposure, is ineffective for VQA models. Thus, we propose an attention-based method, which uses confidence of reasoning between input images and questions and shows much more promising results than the previous methods in unimodal tasks. In addition, we show that a maximum entropy regularization of attention networks can significantly improve the attention-based anomaly detection of the VQA models. Thanks to the simplicity, attention-based anomaly detection and the regularization are model-agnostic methods, which can be used for various cross-modal attentions in the state-of-the-art VQA models. The results imply that crossmodal attention in VQA is important to improve not only VQA accuracy, but also the robustness to various anomalies.
本文作者提出了对VQA应用到现实的鲁棒性测试提出了5个任务:1图片不常见,问题常见,2图片常见,问题不常见,3问题和图片都不常见,4问题和图片都常见,但是问题和图片无关,5问题和图片常见,但是答案不常见。该文章还介绍了一种正则化的方法,可以对于异常检测比较敏感。
《Visual Concept Reasoning Networks》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-8575.KimT.pdf
作者:Taesup Kim , Sungwoong Kim , Yoshua Bengio
单位/机构:Amazon Web Services, Mila, Universite de Montreal,Kakao Brain
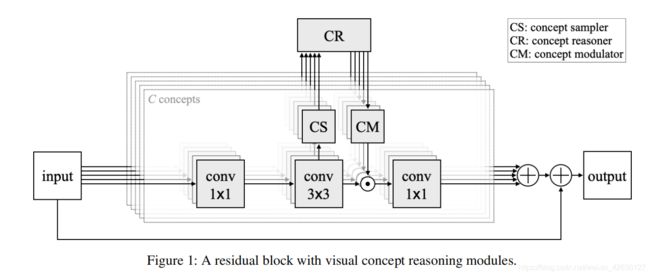
Abstract:A split-transform-merge strategy has been broadly used as an architectural constraint in convolutional neural networks for visual recognition tasks. It approximates sparsely connected networks by explicitly defining multiple branches to simultaneously learn representations with different visual concepts or properties. Dependencies or interactions between these representations are typically defined by dense and local operations, however, without any adaptiveness or high-level reasoning. In this work, we propose to exploit this strategy and combine it with our Visual Concept Reasoning Networks (VCRNet) to enable reasoning between high-level visual concepts. We associate each branch with a visual concept and derive a compact concept state by selecting a few local descriptors through an attention module. These concept states are then updated by graph-based interaction and used to adaptively modulate the local descriptors. We describe our proposed model by split-transform-attend-interact-modulatemerge stages, which are implemented by opting for a highly modularized architecture. Extensive experiments on visual recognition tasks such as image classification, semantic segmentation, object detection, scene recognition, and action recognition show that our proposed model, VCRNet, consistently improves the performance by increasing the number of parameters by less than 1%.
这篇文章主要任务是对图片的内容进行一个概念上的理解,是一个比较上游的任务。这篇文章提出了Concept Sampler模块,用于对特征进行一个初步的处理,更有针对地挖掘信息;Concept Reasoner模块,用于不同concept之间的一个信息交流和推理;Concept Modulator模块,用于将推理过后的concept进行一个整合。文章非常细致。
《Visual Pivoting for (Unsupervised) Entity Alignment》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-9722.LiuF.pdf
作者:Fangyu Liu, Muhao Chen, Dan Roth, Nigel Collier
单位/机构: Language Technology Lab, TAL, University of Cambridge, UK
Department of Computer and Information Science, University of Pennsylvania, USA
Viterbi School of Engineering, University of Southern California, USA

Abstract:This work studies the use of visual semantic representations to align entities in heterogeneous knowledge graphs (KGs). Images are natural components of many existing KGs. By combining visual knowledge with other auxiliary information, we show that the proposed new approach, EVA , creates a holistic entity representation that provides strong signals for cross-graph entity alignment. Besides, previous entity alignment methods require human labelled seed alignment, restricting availability. EVA provides a completely unsupervised solution by leveraging the visual similarity of entities to create an initial seed dictionary (visual pivots). Experiments on benchmark data sets DBP15k and DWY15k show that EVA offers state-of-the-art performance on both monolingual and cross-lingual entity alignment tasks. Furthermore, we discover that images are particularly useful to align long-tail KG entities, which inherently lack the structural contexts that are necessary for capturing the correspondences.
本文研究的是在不同的多模态的知识图谱中使用视觉语义进行对齐。作者首先使用Multi-model KG embedding将两个来自不同知识图谱的节点映射到同一个空间中,然后使用alignment learning来学习这两个节点之间的相似性。
《Visual Relation Detection using Hybrid Analogical Learning》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-6323.ChenK.pdf
作者:Kezhen Chen and Kenneth D. Forbus
单位/机构:Qualitative Reasoning Group, Northwestern University
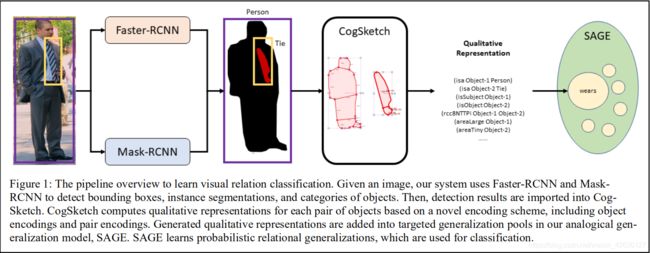
Abstract:Visual Relation Detection is currently one of the most popular problems for visual understanding. Many deep-learning models are designed for relation detection on images and have achieved impressive results. However, deep-learning models have several serious problems, including poor training-efficiency and lack of understandability. Psychologists have ample evidence that analogy is central in human learning and reasoning, including visual reasoning. This paper introduces a new hybrid system for visual relation detection combining deep-learning models and analogical generalization. Object bounding boxes and masks are detected using deep-learning models and analogical generalization over qualitative representations is used for visual relation detection between object pairs. Experiments on the Visual Relation Detection dataset indicates that our hybrid system gets comparable results on the task and is more training-efficient and explainable than pure deep-learning models.
本文主要解决的是视觉关系检测任务。作者提出了一种结合深度学习模型和类比泛化的视觉关系检测混合系统。首先是在图片中提取出目标对象的特征以及其遮罩,然后使用CogSketch来提取遮罩的边缘,来编码这两个物体之间的关系,最后送入SAGE模型中,利用类比学习来推理出正确的结果。
《VisualMRC: Machine Reading Comprehension on Document Images》
paper链接: https://www.aaai.org/AAAI21Papers/AAAI-3951.LeeD.pdf
作者:Ryota Tanaka, Kyosuke Nishida, Sen Yoshida
单位/机构:NTT Media Intelligence Laboratories, NTT Corporation
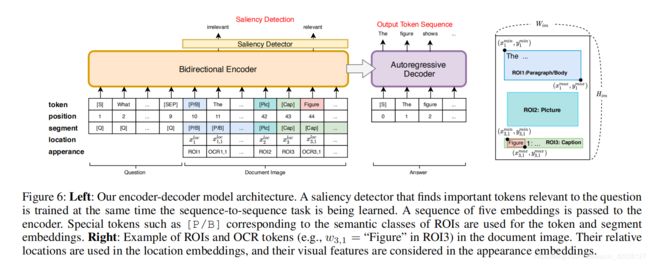
Abstract:Recent studies on machine reading comprehension have focused on text-level understanding but have not yet reached the level of human understanding of the visual layout and content of real-world documents. In this study, we introduce a new visual machine reading comprehension dataset, named VisualMRC, wherein given a question and a document image, a machine reads and comprehends texts in the image to answer the question in natural language. Compared with existing visual question answering (VQA) datasets that contain texts in images, VisualMRC focuses more on developing natural language understanding and generation abilities. It contains 30,000+ pairs of a question and an abstractive answer for 10,000+ document images sourced from multiple domains of webpages. We also introduce a new model that extends existing sequence-to-sequence models, pre-trained with large-scale text corpora, to take into account the visual layout and content of documents. Experiments with VisualMRC show that this model outperformed the base sequence-to-sequence models and a state-of-the-art VQA model. However, its performance is still below that of humans on most automatic evaluation metrics. The dataset will facilitate research aimed at connecting vision and language understanding.
本文提出了一个新的视觉机器阅读理解数据集VisualMRC,更注重自然语言理解和生成能力的培养。作者还提出了一个新的编解码模型,会更加关注文档的视觉布局和内容。