NLP-2015:Subword NMT模型【使用子词来解决OOV问题】
《原始论文:Neural Machine Translation of Rare Words with Subword Units》
一、概述
1、摘要
神经机器翻译(NMT)模型通常以固定的词汇量运行,但是翻译是一个开放词汇的问题。
先前的工作通过退回到字典来解决词汇外单词的翻译。
在本文中,我们介绍了一种更简单,更有效的方法,通过将稀疏和未知词编码为子词单元序列,使NMT模型能够进行开放词汇翻译。这是基于这样的直觉,即:可以通过比单词小的单位来翻译各种单词类别,例如名称(通过字符复制或音译),复合词(通过组成翻译)以及同源词和借词(通过语音和词法转换)。
我们讨论了不同的分词技术的适用性,包括简单字符n-gram模型和基于字节对编码压缩算法的分词,并通过经验证明子词模型在WMT 15翻译任务的基础上比备用字典基线有所改进,其中, 德语→英语以及英语→俄语分别最多提升了1.1和1.3 BLEU。
2、介绍
神经机器翻译最近显示出令人印象深刻的结果。 但是,罕见词的翻译是一个亟待解决的问题。神经模型的词汇量通常限制在3万至5万个词,但是翻译是一个开放词汇的问题,尤其是对于具有高效词形成过程(如凝集和复合)的语言,翻译模型需要的机制必须低于词级 。例如,考虑使用诸如德国 Abwasser | behandlungs | angange “污水处理厂”之类的化合物,对于这些化合物,分段可变长度表示比将单词编码为固定长度向量更具吸引力。
**对于单词级NMT模型,已通过退回字典查找解决了词汇外单词的翻译。**我们注意到,这种技术做出的假设通常在实践中不成立。例如,由于语言之间形态合成程度的差异,就像在我们的复合示例中一样,源词和目标词之间并不总是存在一对一的对应关系。此外,单词级模型也无法翻译或生成看不见的单词。 就像(Jean等人,2015; Luong等人,2015b)所做的那样,将未知单词复制到目标文本中是一种合理的名称策略,但是通常需要进行形态变化和音译,尤其是在字母不同的情况下。
我们研究在子词单元级别上运行的NMT模型。我们的主要目标是在NMT网络本身中对开放词汇翻译进行建模,而无需为稀有单词提供回退模型。除了简化翻译过程之外,我们还发现子词模型与大词汇量模型和回退词典相比,对稀有词的翻译具有更好的准确性,并且能够高效地生成训练中未见到的新词。我们的分析表明,神经网络能够从子词表示中学习复合和音译。
这篇论文主要有两个方面贡献:
- 我们表明,通过子词单元对(稀有)词进行编码,可以实现开放词汇的神经机器翻译。我们发现我们的架构比使用大型词汇表和退回词典更简单,更有效。
- 我们将字节对编码(BPE)(一种压缩算法)用于分词任务。BPE允许通过可变长度字符序列的固定大小的词汇表来表示开放式词汇表,这使其成为神经网络模型非常合适的分词策略。
3、相关工作
对于统计机器翻译(SMT),未知单词的翻译一直是深入研究的主题。
大部分未知单词都是名称,如果两种语言都共享一个字母,则可以将其复制到目标文本中。如果字母不同,则需要音译。基于字符的翻译也已经用基于短语的模型进行了研究,这对于紧密相关的语言尤其成功。
诸如化合物之类的形态复杂的词的分割已广泛用于SMT,并且已经研究了多种词素分割算法。通常用于基于短语的SMT的分割算法在其拆分决策中趋于保守,而我们的目标是进行激进的分割,该分割允许使用紧凑的网络词汇进行开放词汇的翻译,而不必求助于备用词典。
子词单元的最佳选择可能是针对某个具体任务的。对于语音识别,已使用因素级语言模型。Mikolov等研究子词语言模型,并提出使用音节。对于多语言分割任务,已经提出了多语言算法。我们发现这些虽然有趣,但在测试时不适用。
已经提出了多种技术来基于字符或语素产生定长的连续单词向量。与我们的方法类似,将此类技术应用于NMT的努力并未比基于单词的方法有显着改善。与我们的工作有一个技术上的区别是,注意力机制仍在Ling等人的模型中的单词级别上运行,并且每个单词的表示都是固定长度的。我们希望注意力机制可以从可变长度表示中受益:网络可以学习在每个时刻将注意力放在不同的子词单元上。回想一下我们的介绍性示例Abwasserbehandlungsanlange,该示例的子词分段避免了固定长度表示形式的信息瓶颈。
神经机器翻译与基于短语的方法的不同之处在于,有强烈的动机来使神经模型的词汇量最小化,以增加时间和空间效率,并允许在没有回退模型的情况下进行翻译。同时,我们还需要文本本身的紧凑表示形式,因为文本长度的增加会降低效率并增加神经模型需要传递信息的距离。
在词汇量和文本大小之间进行折衷的一种简单方法是使用未分段词的短列表,仅对稀有词使用子词单元。作为替代方案,我们提出了一种基于字节对编码(BPE)的分段算法,该算法可让我们学习提供良好文本压缩率的词汇表。
二、NMT(神经机器翻译)
我们遵循Bahdanau等人的神经机器翻译架构,我们将在此简单地进行总结。但是,我们注意到我们的方法并不特定于该体系结构。
神经机器翻译系统被实现为具有循环神经网络的编码器-解码器网络。
编码器是带有门控循环单元的双向神经网络,它读取输入序列 x = ( x 1 , . . . , x m ) x=(x_1,...,x_m) x=(x1,...,xm) 并计算隐藏状态的前向序列 ( h → 1 , . . . , h → m ) (\overrightarrow h_1,...,\overrightarrow h_m) (h1,...,hm) 和后向序列 ( h ← 1 , . . . , h ← m ) (\overleftarrow h_1,...,\overleftarrow h_m) (h1,...,hm)。将隐藏状态 h → j \overrightarrow h_j hj 和 h ← j \overleftarrow h_j hj 连接起来以获得最终矢量表示 h j h_j hj。
解码器是一个循环神经网络,可预测目标序列 y = ( y 1 , . . . , y n ) y=(y_1,...,y_n) y=(y1,...,yn)。基于循环隐藏状态 s i s_i si,先前预测的单词 y i − 1 y_{i-1} yi−1 和上下文向量 c i c_i ci 预测每个单词 y i y_i yi。 c i c_i ci 被计算为 h j h_j hj 的加权和。每个 h j h_j hj 的权重通过对齐模型 α i j α_{ij} αij 计算,该模型对 y i y_i yi 对齐到 x j x_j xj 的概率进行建模。对齐模型是单层前馈神经网络,可通过反向传播与网络的其余部分一起学习。
可以在(Bahdanau et al.,2015)中找到详细描述。在具有随机梯度下降的平行语料库上进行训练。为了翻译,采用了具有小集束尺寸的集束搜索。
三、子词翻译
本文背后的主要动机是,某些单词的翻译是未知的,因为即使是有能力的译者对他或她来说是新颖的,这些单词也可以基于已知的子词单位(例如词素或音素)的翻译进行翻译。翻译可能未知的单词类别包括:
- 命名实体。在共享字母的语言之间,名称通常可以从源文本复制到目标文本。也可能需要转录或音译,尤其是在字母或音节不同的情况下。例如:Barack Obama (English; German)、Барак Обама (Russian)、バラク・オバマ (ba-ra-ku o-ba-ma) (Japanese)。
- 同源词和外来词。同源语言的同源词和外来词在语言之间可能会以常规方式有所不同,因此字符级翻译规则就足够了。例如:claustrophobia (English)、Klaustrophobie (German)、Клаустрофобия (Klaustrofobiâ) (Russian)。
- 形态复杂的单词。包含多个词素的单词,例如通过复合,词缀或词尾变化形成的单词,可以通过分别翻译这些词素来进行翻译。例如:solar system (English)、Sonnensystem (Sonne + System) (German)、Naprendszer (Nap + Rendszer) (Hungarian)。
在我们的德国训练数据中分析了100个稀有单词(不包括在50,000种最常见的单词中),大多数单词都有可能从英语翻译成较小的单位。我们发现56个化合物,21个名称,6个具有共同起源的外来词(emancipate→emanzipieren),5个未知附加词(sweetish ‘sweet’+’-ish’→süßlich ‘süß’+’-lich’),1个数字和1个计算机语言标识符。
我们的假设是,将稀有词分割成适当的子词单元就足以使神经翻译网络学习未知的翻译,并概括该知识来翻译和生成看不见的词。我们在第4节和第5节中对此假设提供了经验支持。首先,我们讨论不同的子词表示形式。
四、字节对编码(BPE)

字节对编码(BPE)是一种简单的数据压缩技术,可以用一个未使用的字节迭代地替换序列中最频繁的一对字节。我们将这种算法用于分词。我们不合并频繁的字节对,而是合并字符或字符序列。
首先,我们使用字符词汇表来初始化符号词汇表,并将每个单词表示为一个字符序列,再加上一个特殊的单词结尾符号“·”,这使我们能够在翻译后恢复原始的字符化。我们迭代地计算所有符号对,并用新的符号“AB”替换每个出现频率最高的符号对(“ A”,“ B”)。 每个合并操作都会产生一个代表字符n-gram的新符号。常见的字符n-gram(或整个单词)最终合并为一个符号,因此BPE不需要候选词。最终符号词汇的大小等于初始词汇的大小加上合并操作的数量,后者是算法的唯一超参数。
为了提高效率,我们不考虑跨越单词边界的对。因此,该算法可以在从文本中提取的词典上运行,每个单词均按其频率加权。算法1中显示了一个最小的Python实现。实际上,我们通过索引所有对并逐步更新数据结构来提高效率。
图1显示了学习到的BPE操作的简单示例。在测试时,我们首先将单词分成字符序列,然后应用学习到的操作将字符合并为更大的已知符号。这适用于任何单词,并允许带有固定符号词汇的开放式词汇网络。在我们的示例中,OOV的“ lower”将被细分为“ lower·”。
我们评估了两种应用BPE的方法:学习两种独立的编码,一种用于源词汇,一种用于目标词汇,或者学习两种词汇的并集编码(我们称为联合BPE)。前者具有以下优点:在文本和词汇量方面更加紧凑,并具有更强的保证力,即每个子词单元都已在相应语言的训练文本中被看到,而后者则改善了源和目标分段之间的一致性。如果我们独立地应用BPE,则相同的名称在两种语言中可能会进行不同的细分,这使得神经模型更难学习子词单元之间的映射。为了提高英语和俄语分割之间的一致性,尽管字母有所不同,我们使用ISO-9将俄语词汇音译为拉丁字符以学习联合BPE编码,然后将BPE合并操作音译回西里尔字母,以将其应用于俄语训练文本。
五、评估
我们旨在回答以下经验性问题:
- 我们可以通过子词单元来表示神经机器翻译中的稀有和看不见的词吗?
- 在词汇量,文本大小和翻译质量方面,哪个细分为子词单元的效果最佳?
我们对来自WMT 2015的共享翻译任务的数据进行实验。对于英语→德语,我们的训练集包括420万个句子对,并且有大约1亿个字符。对于英语→俄语,训练集包括260万个句子对,并且有大约5000万个字符。我们使用Moses提供的脚本对数据进行标记化和Truecase处理。 我们使用newstest2013作为开发集,并在newstest2014和newstest2015上测试结果。
我们报告了BLEU和CHRF3的结果,CHRF3是一个字符n-gram F3得分,被发现与人类的判断有很好的相关性,尤其是英语以外的翻译。由于我们的主要主张与稀有和看不见的单词的翻译有关,因此我们针对这些单词分别报告了统计数据。我们通过一元F1来测量这些值,我们将其计算为裁剪一元精度和召回率的调和平均值。
我们使用Groundhog进行所有实验。我们通常会根据之前的工作来进行参数设置。所有网络的隐藏层大小为1000,嵌入层大小为620,我们仅在内存中保留一个τ = 30000 τ=30000τ=30000个单词的候选列表。
在训练期间,我们使用Adadelta,minibatch大小为80,并在各个时期之间重新调整训练集。我们训练网络约7天,然后获取最后4个保存的模型(每12小时保存一次模型),并继续使用固定的嵌入层训练每个模型12小时 。我们为每个模型执行两次独立的训练,一次将梯度的截断值设为5.0,一次将截断值设为1.0,后者会在大多数情况下产生更好的单个模型。我们报告了在我们的开发平台上表现最佳的系统的结果(newstest2013),以及所有8个模型的集合。
我们进行集束搜索的宽度为12,并通过句子长度对概率进行归一化。 我们使用基于快速对齐的双语词典。 对于我们的基线,这是稀有单词的备用词典。我们还使用字典来加快所有实验的翻译速度,仅对筛选后的候选翻译列表执行softmax,我们使用 K = 30000 ;K ′ = 10。
1、子词统计

除了翻译质量(我们将通过经验验证)以外,我们的主要目标是通过紧凑的固定大小的子词词汇表来表示开放式词汇表,并进行有效的训练和解码。
表1中显示了并行数据德文的不同分段的统计信息。简单的基线是将单词分段为n-grams字符。n-grams字符允许在序列长度(#tokens)和词汇量(#types)之间进行不同的折衷,具体取决于n的选择。序列长度的增加是可观的;减少序列长度的一种方法是不对k个最常见的单词类型进行分段。只有字母组合表示法才是真正的公开词汇。但是,在初步实验中,字母组合表示的表现很差,我们用二元字母组表示来报告翻译结果,从经验上讲它更好,但是在带有训练集词汇的测试集中无法产生某些字符。
我们报告了在以前的SMT研究中被证明有用的几种分词技术的统计数据,包括基于频率的复合拆分,基于规则的连字和Morfessor。我们发现它们仅适度地减小了词汇量,并且不能解决未知单词的问题,因此我们发现它们不适合我们的不带回退词典的开放式词汇翻译的目标。
BPE满足了我们实现开放词汇的目标,并且可以将学习到的合并操作应用于测试集以获得没有未知符号的分段。它与字符级模型的主要区别在于BPE的表示更加紧凑,并可以实现更短的句子序列。表1显示了具有59500个合并操作的BPE和具有89500个操作的联合BPE。
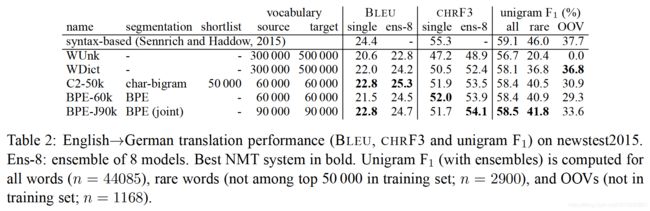
实际上,我们没有在NMT网络词汇表中包含不常见的子词单元,因为子词符号集,例如, 来自外国字母的字符。因此,表2中的网络词汇量通常比表1中的类型数小。
参考资料:
Neural Machine Translation of Rare Words with Subword Units翻译
OOV问题-论文笔记《Neural Machine Translation of Rare Words with Subwords Units》- ACL2016
通过BPE解决OOV问题----Neural machine Translation of Rare Words with Subword Units
论文分享 – > NLP – > Neural machine Translation of Rare Words with Subword Units
【论文笔记】Neural Machine Translation of Rare Words with Subword Units
《Neural Machine Translation of Rare Words with Subword Units》阅读笔记
NMT十篇必读论文(二)Neural Machine Translation of Rare Words with Subword Units
[ THUNLP-MT(9/10) ] Neural Machine Translation of Rare Words with Subword Units | Byte Pair Encoding