【深度学习系列(六)】:RNN系列(5):RNN模型的奇淫巧技之灵活的注意力机制
解决NLP任务的三大法宝:注意力机制、卷积神经网络以及循环神经网络。可见注意力机制对于NLP来说非常重要,所以这里着重说一说注意力机制,以及灵活的使用注意力机制到实际工程中。
众所周知,注意力机制通常是运用于seq2seq模型中,我们常用的注意力机制是基于信息的注意力机制,也就是说我们只选择一些关键的的输入信息进行处理,但有时我们也需要关注其他信息,比如说位置信息。在进行公式时别、语音时别等一些场合中,字符间位置信息也非常重要,所以这一篇中我们将介绍如何灵活的改装seq2seq的注意力机制,运用于我们实际的任务需求中。。。
目录
一、BahdanauAttention注意力机制的实现
二、多头注意力机制和内部注意力机制的实现
2.1、注意力机制的基本思想
2.2、多头注意力机制和内部注意力机制
2.3、多头注意力机制的实战——分析评论者是否满意
三、混合注意力机制的实现
3.1、混合注意力机制的具体实现
一、BahdanauAttention注意力机制的实现
这里不多介绍,具体可以参考我之前的文章,地址:【深度学习系列(六)】:RNN系列(4):带注意力机制的seq2seq模型及其实战(2):为图片添加内容描述。
二、多头注意力机制和内部注意力机制的实现
2.1、注意力机制的基本思想
从第一节中我们已经能够非常熟悉的掌握注意力机制了,这里简单谈一下。其实注意力机制的思想也很简单:具体来说就是使用query进行查询任务,然后根据key值来查询value中的我们关注的部分。这里我们简单将query、key、value三个对象分别简写为q、k、v。具体实现如下:
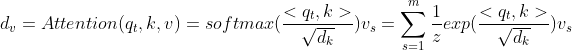
具体计算过程如下:
- 将q与k进行内积计算,同时需要除以
 来去除维度的影响(起到调节数值的作用,使内积不至于过大);
来去除维度的影响(起到调节数值的作用,使内积不至于过大); - 使用第一步的结果计算softmax分数,也就是注意力分数;
- 使用上一步的分数与v相乘,得到q与v的相似度;
- 最后一步就是对上述结果进行加权求和,得到对应的输出d。
该模型可以用于翻译模型,如输入的m个单词,词向量维度为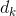 ,翻译后有n个词,词向量维度为,将上述attention过程可以简化其运算过程为:
,翻译后有n个词,词向量维度为,将上述attention过程可以简化其运算过程为:![]() ,最终得到
,最终得到![]() 。当然,该模型也可以用于其他任务,如阅读理解任务,把文章作为q,阅读理解的问题作为k,答案作为v。
。当然,该模型也可以用于其他任务,如阅读理解任务,把文章作为q,阅读理解的问题作为k,答案作为v。
2.2、多头注意力机制和内部注意力机制
多头注意力机制是Google在2017年《Attention is All You Need》发出的论文,这个是Google提出的新概念,是Attention机制的完善,其使用多头的技术来改进原始注意力机制。在深度学习做NLP的方法中,我们通常会将句子转化为embedding然后进行处理,处理的方法主要有:
- RNN:比如lstm、GRU或其他改进的RNN单元来完成任务。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
- CNN:比如我们之前提到过的TextCNN。CNN方便并行,而且容易捕捉到一些全局的结构信息,笔者本身是比较偏爱CNN的,在目前的工作或竞赛模型中,我都已经尽量用CNN来代替已有的RNN模型了,并形成了自己的一套使用经验。
- 注意力机制:对,没错,这货也能作完成NLP任务。RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;Attention的思路最为粗暴,它一步到位获取了全局信息!
(注:上述蓝色部分都是别人文章中的,我觉得讲的非常好,这里就借用下)
多头注意力机制从形式上看,它其实就再简单不过了,就是把Q,K,V通过参数矩阵映射一下,然后再做Attention,把这个过程重复做h次,结果拼接起来就行了,可谓“大道至简”了。具体实现如下:
![]()
![]()
具体计算过程如下:
- 把Q、K、V通过参数矩阵进行全连接映射转换;
- 将第一步中的三个结果作点积运算(Attention运算);
- 将第一、二步中的运算重复h次,在第一步中每次都需要使用新的权重矩阵;
- 使用concat函数将h次计算后的结果进行拼接。
计算过程如下图:
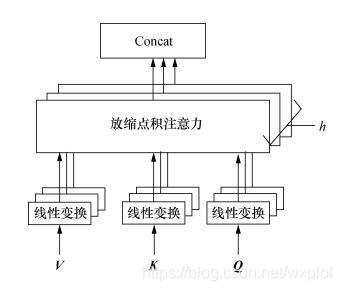
每次Attention运算都会使数据中的某方面特征发生注意力转化(得到局部特征),当发生多次Attention运算后会得到多个方向的局部注意力特征,将所有的局部注意力特征拼接起来之后在通过神经网络转化为整体的特征,从而达到拟合或分类的结果。
内部注意力机制(Self Attention)主要是用于发现序列数据内部的特征,其结构与多头注意力机制类似,但又有一些不同。具体做法是将Q、K、V都转化为X,即Attention(X,X,X)。Google论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。类似的事情是,目前SQUAD阅读理解的榜首模型R-Net也加入了自注意力机制,这也使得它的模型有所提升。内部注意力机制的一般表达式如下:
![]()
参考链接:《Attention is All You Need》浅读(简介+代码)
2.3、多头注意力机制的实战——分析评论者是否满意
2.3.1、数据读取
本例使用的数据集为康奈尔大学发布的电影评价数据集,具体链接如下:
链接: https://pan.baidu.com/s/1QBYjRjcO8MP3XFCwUPkz1g 密码: 5d40
该数据集包含两个文件rt-polarity.neg和rt-polarity.pos,其分别包含5331个正面的评论和5331个负面的评论,具体文件如下图所示。
这里直接使用tf.keras.preprocessing.text.Tokenizer()模块进行数据的读取和预处理,详细细节这里不多介绍,代码如下:
import tensorflow as tf
def load_data(positive_data_file,negative_data_file):
'''加载数据'''
# 读取数据
file_list=[positive_data_file,negative_data_file]
train_data=[]
train_labels=[]
for index,file in enumerate(file_list):
with open(file,'r',encoding='utf-8') as fp:
for line in fp.readlines():
train_data.append(line.strip())
train_labels.append(index)
#文本标签预处理:(1)文本过滤;(2)建立字典;(3)向量化文本以及文本对齐
# 文本过滤,去除无效字符
tokenizer=tf.keras.preprocessing.text.Tokenizer(oov_token="",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ')
tokenizer.fit_on_texts(train_data)
# 建立字典,构造正反向字典
tokenizer.word_index={key:value for key,value in tokenizer.word_index.items()}
# 向字典中加入字符
tokenizer.word_index[tokenizer.oov_token] = len(tokenizer.word_index) + 1
# 向字典中加入字符
tokenizer.word_index[''] = 0
index_word = {value: key for key, value in tokenizer.word_index.items()}
# 向量化文本和对齐操作,将文本按照字典的数字进行项向量化处理,
# 并按照指定长度进行对齐操作(多余的截调,不足的进行补零)
train_seq=tokenizer.texts_to_sequences(train_data)
len_seq=[len(l) for l in train_seq]
cap_vector=tf.keras.preprocessing.sequence.pad_sequences(train_seq,padding='post')
max_length = len(cap_vector[0]) # 标签最大长度
return cap_vector, train_labels,max_length, len_seq,tokenizer.word_index, index_word
def dataset(positive_data_file,negative_data_file,batch_size=64):
cap_vector, train_labels,max_length, len_seq, word_index, index_word = load_data(positive_data_file, negative_data_file)
dataset=tf.data.Dataset.from_tensor_slices(((cap_vector,len_seq),train_labels))
dataset=dataset.shuffle(len(cap_vector))
dataset=dataset.batch(batch_size,drop_remainder=True)
return dataset,max_length, word_index, index_word 2.3.2、模型搭建
- 带有位置信息的词嵌入层的实现
虽然MultiAttention本质是key-value的查找机制,但是这样的模型并不能捕捉序列的顺序!换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。对于时间序列来说,尤其是对于NLP中的任务来说,顺序是很重要的信息,它代表着局部甚至是全局的结构,学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。
于是Google再祭出了一招——Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
在以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:
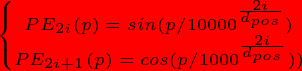
这里的意思是将id为p的位置映射为一个dpos维的位置向量,这个向量的第ii个元素的数值就是PEi(p)。Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有sin(α+β)=sin(α)cos(β)+cos(α)sin(β)以及cos(α+β)=cos(α)cosβ−sin(α)sin(β),这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
Position Embedding的主要实现步骤如下:
1、使用sin和cos算法对嵌入中的每一个元素进行计算;
2、将第一步的结果使用concat函数连接起来作为最终的位置信息;
3、将得到的位置信息与embedding进行拼接或直接加入到embedding中。
这里我们自定义Position Embedding层,在tf.keras中自定义网络主要有以下几步:
1、继承tf.keras.layers.Layer;
2、在类中实现__init__方法,用于对该层的初始化;
3、实现build方法用于定义该层的权重;
4、实现call方法,用于调用事件。对输入数据进行自定义处理,同时还需要支持masking(根据实际长度进行计算);
5、在类中实现compute_output_shape方法,指定该层的输出shape。
具体实现如下:
class Position_Embedding(tf.keras.layers.Layer):
'''带位置信息的词嵌入'''
def __init__(self,size=None,mode='sum',**kwargs):
super(Position_Embedding,self).__init__(**kwargs)
self.size=size#必须为偶数
self.mode=mode
def call(self, inputs, **kwargs):
if self.size==None or self.mode=='sum':
self.size=int(inputs.shape[-1])
position_j=1./K.pow(10000.,2*K.arange(self.size/2,dtype='float32')/self.size)
position_j=K.expand_dims(position_j,0)
# 按照x的1维度累计求和,与arange一样,生成序列。只不过按照x的实际长度来
position_i=tf.cumsum(K.ones_like(inputs[:,:,0]),1)-1
position_i=K.expand_dims(position_i,2)
position_ij=K.dot(position_i,position_j)
position_ij=K.concatenate([K.cos(position_ij),K.sin(position_ij)],2)
if self.mode=='sum':
return position_ij+inputs
elif self.mode=='concat':
return K.concatenate([position_ij,inputs],2)
def compute_output_shape(self, input_shape):
if self.mode == 'sum':
return input_shape
elif self.mode == 'concat':
return (input_shape[0], input_shape[1], input_shape[2]+self.size)- 多头注意力层的实现
Multi-Head的意思虽然很简单——重复做几次然后拼接,但事实上不能按照这个思路来写程序,这样会非常慢。因此我们必须把Multi-Head的操作合并到一个张量来运算,因为单个张量的乘法内部则会自动并行。该方法直接将多头注意力机制最后的全连接网络中的权重提取出来,并入到原有的输入Q、K、V中并按指定的次数展开,使他们直接以矩阵的方式进行计算。具体实现步骤如下:
1、对注意力机制中的三个角色Q、K、V作线性变换;
2、调用batch_dot对变换后的Q和K作基于矩阵的相乘计算;
3、对第二步的结果与V作作基于矩阵的相乘计算。
具体实现如下:
class Attention(tf.keras.layers.Layer):
'''基于内部注意力机制的多头注意力机制'''
def __init__(self,nb_head,size_per_head,**kwargs):
super(Attention,self).__init__(**kwargs)
self.nb_head=nb_head #设置注意力的计算次数
self.size_per_head=size_per_head #设置每次线性变化为size_per_head的维度
self.output_dim=nb_head*size_per_head #设置输出的总维度
def build(self,input_shape):
'''定义q、k、v的权重'''
super(Attention,self).build(input_shape)
self.WQ=self.add_weight(name='WQ',
shape=(int(input_shape[0][-1]),self.output_dim),
initializer='glorot_uniform',trainable=True)
self.WK = self.add_weight(name='WK',
shape=(int(input_shape[1][-1]), self.output_dim),
initializer='glorot_uniform', trainable=True)
self.WV = self.add_weight(name='WV',
shape=(int(input_shape[2][-1]), self.output_dim),
initializer='glorot_uniform', trainable=True)
def Mask(self,inputs,seq_len,mode='mul'):
'''定义Mask方法方法,按照seq_len实际长度对inputs进行计算'''
if seq_len==None:
return inputs
else:
mask=K.one_hot(seq_len[:,0],K.shape(inputs)[1])
mask=1-K.cumsum(mask,1)
for _ in range(len(inputs.shape)-2):
mask=K.expand_dims(mask,2)
if mode=='mul':
return inputs*mask
if mode=='add':
return inputs-(1-mask)*1e12
def call(self, inputs, **kwargs):
#解析传入的Q_seq,K_seq,V_seq
if len(inputs)==3:
Q_seq,K_seq,V_seq=inputs
Q_len,V_len=None,None
elif len(inputs)==5:
Q_seq,K_seq,V_seq,Q_len,V_len=inputs
#对Q_seq,K_seq,V_seq作nb_head次线性变换,并转化为size_per_head
Q_seq=K.dot(Q_seq,self.WQ)
Q_seq=K.reshape(Q_seq,(-1,K.shape(Q_seq)[1],self.nb_head,self.size_per_head))
Q_seq=K.permute_dimensions(Q_seq,(0,2,1,3))
K_seq = K.dot(K_seq, self.WK)
K_seq = K.reshape(K_seq, (-1, K.shape(K_seq)[1], self.nb_head, self.size_per_head))
K_seq = K.permute_dimensions(K_seq, (0, 2, 1, 3))
V_seq = K.dot(V_seq, self.WV)
V_seq = K.reshape(V_seq, (-1, K.shape(V_seq)[1], self.nb_head, self.size_per_head))
V_seq = K.permute_dimensions(V_seq, (0, 2, 1, 3))
# 计算内积,然后mask,然后softmax
# A=tf.compat.v1.keras.backend.batch_dot(Q_seq, K_seq, axes=[3,3])/ self.size_per_head**0.5
A = K.batch_dot(Q_seq, K_seq, axes=[3,3]) / self.size_per_head**0.5
A=K.permute_dimensions(A,(0,3,2,1))
A=self.Mask(A,V_len,'add')
A=K.permute_dimensions(A,(0,3,2,1))
A=K.softmax(A)
# 输出并mask
O_seq=K.batch_dot(A,V_seq,axes=[3,2])
O_seq=K.permute_dimensions(O_seq,(0,2,1,3))
O_seq=K.reshape(O_seq,(-1,K.shape(O_seq)[1],self.output_dim))
O_seq=self.Mask(O_seq,Q_len,'mul')
return O_seq
def compute_output_shape(self, input_shape):
return (input_shape[0][0], input_shape[0][1], self.output_dim)-
模型搭建
这里没什么好说的,直接看代码:
def RNN_Attention(embedding_size,vocab_size,max_len):
input=tf.keras.layers.Input([max_len])
# 生成带位置信息的词向量
embeddings=tf.keras.layers.Embedding(vocab_size,embedding_size)(input)
embeddings=Position_Embedding()(embeddings) #默认使用同等维度的位置向量
#注意力机制
x=Attention(8,16)([embeddings,embeddings,embeddings])
#全局池化
x=tf.keras.layers.GlobalAveragePooling1D()(x)
#dropout
x=tf.keras.layers.Dropout(rate=0.5)(x)
# x=TargetedDropout(drop_rate=0.5, target_rate=0.5)(x)
x=tf.keras.layers.Dense(1,activation='sigmoid')(x)
model=tf.keras.Model(inputs=input,outputs=x)
return model
2.3.3、模型的训练
positive_data_file="./rt-polaritydata/rt-polarity.pos"
negative_data_file="./rt-polaritydata/rt-polarity.neg"
dataset,max_length, word_index, index_word=dataset(positive_data_file,negative_data_file)
embedding_size=128
vocab_size=len(word_index)
max_len=max_length
model=RNN_Attention(embedding_size,vocab_size,max_len)
model.summary()
#添加反向传播节点
model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy'])
#开始训练
print('Train...')
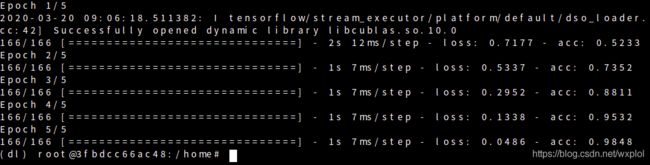
model.fit(dataset,epochs=5)最终训练结果如下:
三、混合注意力机制的实现
混合注意力机制在之前的文章中已经详细的进行解析,具体可以参考我之前的文章:【深度学习系列(六)】:RNN系列(4):带注意力机制的seq2seq模型及其实战(1)。这里主要讲一下该注意力机制与一般的注意力机制的区别。一般来说混合注意力机制的结构如下:
![]()
也就是说混合注意力机制与上一时刻的输出s和位置信息a,以及当前时刻的内容h有关。而不带位置信息的一般注意力机制的结构如下:
![]()
与混合注意力机制的区别就是多了个位置信息a。
3.1、混合注意力机制的具体实现
具体实现代码如下:
import tensorflow as tf
from tensorflow.contrib.seq2seq.python.ops.attention_wrapper import BahdanauAttention
#from tensorflow.python.layers import core as layers_core
#from tensorflow.python.ops import array_ops, math_ops, nn_ops, variable_scope
from tensorflow.python.ops import array_ops, variable_scope
def _location_sensitive_score(processed_query, processed_location, keys):
#获取注意力的深度(全连接神经元的个数)
dtype = processed_query.dtype
num_units = keys.shape[-1].value or array_ops.shape(keys)[-1]
#定义了最后一个全连接v
v_a = tf.get_variable('attention_variable', shape=[num_units], dtype=dtype,
initializer=tf.contrib.layers.xavier_initializer())
#定义了偏执b
b_a = tf.get_variable('attention_bias', shape=[num_units], dtype=dtype,
initializer=tf.zeros_initializer())
#计算注意力分数
return tf.reduce_sum(v_a * tf.tanh(keys + processed_query + processed_location + b_a), [2])
def _smoothing_normalization(e):#平滑归一化函数,返回[batch_size, max_time],代替softmax
return tf.nn.sigmoid(e) / tf.reduce_sum(tf.nn.sigmoid(e), axis=-1, keepdims=True)
class LocationSensitiveAttention(BahdanauAttention):#位置敏感注意力
def __init__(self, #初始化
num_units, #实现过程中全连接的神经元个数
memory, #编码器encoder的结果
smoothing=False, #是否使用平滑归一化函数代替softmax
cumulate_weights=True, #是否对注意力结果进行累加
name='LocationSensitiveAttention'):
#smoothing为true则使用_smoothing_normalization,否则使用softmax
normalization_function = _smoothing_normalization if (smoothing == True) else None
super(LocationSensitiveAttention, self).__init__(
num_units=num_units,
memory=memory,
memory_sequence_length=None,
probability_fn=normalization_function,#当为None时,基类会调用softmax
name=name)
self.location_convolution = tf.layers.Conv1D(filters=32,
kernel_size=(31, ), padding='same', use_bias=True,
bias_initializer=tf.zeros_initializer(), name='location_features_convolution')
self.location_layer = tf.layers.Dense(units=num_units, use_bias=False,
dtype=tf.float32, name='location_features_layer')
self._cumulate = cumulate_weights
def __call__(self, query, #query为解码器decoder的中间态结果[batch_size, query_depth]
state):#state为上一次的注意力[batch_size, alignments_size]
with variable_scope.variable_scope(None, "Location_Sensitive_Attention", [query]):
#全连接处理query特征[batch_size, query_depth] -> [batch_size, attention_dim]
processed_query = self.query_layer(query) if self.query_layer else query
#维度扩展 -> [batch_size, 1, attention_dim]
processed_query = tf.expand_dims(processed_query, 1)
#维度扩展 [batch_size, max_time] -> [batch_size, max_time, 1]
expanded_alignments = tf.expand_dims(state, axis=2)
#通过卷积获取位置特征[batch_size, max_time, filters]
f = self.location_convolution(expanded_alignments)
#经过全连接变化[batch_size, max_time, attention_dim]
processed_location_features = self.location_layer(f)
#计算注意力分数 [batch_size, max_time]
energy = _location_sensitive_score(processed_query, processed_location_features, self.keys)
#计算最终注意力结果[batch_size, max_time]
alignments = self._probability_fn(energy, state)
#是否累加
if self._cumulate:
next_state = alignments + state
else:
next_state = alignments#[batch_size, alignments_size],alignments_size为memory的最大序列次数max_time
return alignments, next_state