《统计学习方法》 第十六章 主成分分析PCA
主成分分析(PCA)
假设 x x x为 m m m 维随机变量,其均值为 μ \mu μ,协方差矩阵为 Σ \Sigma Σ
考虑由 m m m维随机变量 x x x到 m m m维随机变量 y y y的线性变换
y i = α i T x = ∑ k = 1 m α k i x k , i = 1 , 2 , ⋯ , m y _ { i } = \alpha _ { i } ^ { T } x = \sum _ { k = 1 } ^ { m } \alpha _ { k i } x _ { k } , \quad i = 1,2 , \cdots , m yi=αiTx=k=1∑mαkixk,i=1,2,⋯,m
其中 α i T = ( α 1 i , α 2 i , ⋯ , α m i ) \alpha _ { i } ^ { T } = ( \alpha _ { 1 i } , \alpha _ { 2 i } , \cdots , \alpha _ { m i } ) αiT=(α1i,α2i,⋯,αmi)
如果该线性变换满足以下条件,则称之为总体主成分:
α i T α i = 1 , i = 1 , 2 , ⋯ , m \alpha _ { i } ^ { T } \alpha _ { i } = 1 , i = 1,2 , \cdots , m αiTαi=1,i=1,2,⋯,m;
cov ( y i , y j ) = 0 ( i ≠ j ) \operatorname { cov } ( y _ { i } , y _ { j } ) = 0 ( i \neq j ) cov(yi,yj)=0(i=j);
变量 y 1 y_1 y1是 x x x的所有线性变换中方差最大的
y 2 y_2 y2是与 y 1 y_1 y1不相关的 x x x的所有线性变换中方差最大的
一般地, y i y_i yi是与 y 1 , y 2 , ⋯ , y i − 1 , ( i = 1 , 2 , ⋯ , m ) y _ { 1 } , y _ { 2 } , \cdots , y _ { i - 1 } , ( i = 1,2 , \cdots , m ) y1,y2,⋯,yi−1,(i=1,2,⋯,m)都不相关的 x x x的所有线性变换中方差最大的
这时分别称 y 1 , y 2 , ⋯ , y m y _ { 1 } , y _ { 2 } , \cdots , y _ { m } y1,y2,⋯,ym为 x x x的第一主成分、第二主成分、…、第 m m m主成分
假设 x x x是 m m m维随机变量
其协方差矩阵是 Σ \Sigma Σ
Σ \Sigma Σ的特征值分别是 λ 1 ≥ λ 2 ≥ ⋯ ≥ λ m ≥ 0 \lambda _ { 1 } \geq\lambda _ { 2 } \geq \cdots \geq \lambda _ { m } \geq 0 λ1≥λ2≥⋯≥λm≥0
特征值对应的单位特征向量分别是 α 1 , α 2 , ⋯ , α m \alpha _ { 1 } , \alpha _ { 2 } , \cdots , \alpha _ { m } α1,α2,⋯,αm,则 x x x的第2主成分可以写作
y i = α i T x = ∑ k = 1 m α k i x k , i = 1 , 2 , ⋯ , m y _ { i } = \alpha _ { i } ^ { T } x = \sum _ { k = 1 } ^ { m } \alpha _ { k i } x _ { k } , \quad i = 1,2 , \cdots , m yi=αiTx=k=1∑mαkixk,i=1,2,⋯,m
并且, x x x的第 i i i主成分的方差是协方差矩阵 Σ \Sigma Σ的第 i i i个特征值,即 var ( y i ) = α i T Σ α i = λ i \operatorname { var } ( y _ { i } ) = \alpha _ { i } ^ { T } \Sigma \alpha _ { i } = \lambda _ { i } var(yi)=αiTΣαi=λi
主成分有以下性质:
主成分 y y y的协方差矩阵是对角矩阵 cov ( y ) = Λ = diag ( λ 1 , λ 2 , ⋯ , λ m ) \operatorname { cov } ( y ) = \Lambda = \operatorname { diag } ( \lambda _ { 1 } , \lambda _ { 2 } , \cdots , \lambda _ { m } ) cov(y)=Λ=diag(λ1,λ2,⋯,λm)
主成分 y y y的方差之和等于随机变量 x x x的方差之和
∑ i = 1 m λ i = ∑ i = 1 m σ i i \sum _ { i = 1 } ^ { m } \lambda _ { i } = \sum _ { i = 1 } ^ { m } \sigma _ { i i } i=1∑mλi=i=1∑mσii
其中 σ i i \sigma _ { i i } σii是 x 2 x_2 x2的方差,即协方差矩阵 Σ \Sigma Σ的对角线元素
主成分 y k y_k yk与变量 x 2 x_2 x2的相关系数 ρ ( y k , x i ) \rho ( y _ { k } , x _ { i } ) ρ(yk,xi)称为因子负荷量(factor loading)
它表示第 k k k个主成分 y k y_k yk与变量 x x x的相关关系,即 y k y_k yk对 x x x的贡献程度
ρ ( y k , x i ) = λ k α i k σ i i , k , i = 1 , 2 , ⋯ , m \rho ( y _ { k } , x _ { i } ) = \frac { \sqrt { \lambda _ { k } } \alpha _ { i k } } { \sqrt { \sigma _ { i i } } } , \quad k , i = 1,2 , \cdots , m ρ(yk,xi)=σiiλkαik,k,i=1,2,⋯,m
样本主成分分析就是基于样本协方差矩阵的主成分分析
给定样本矩阵
X = [ x 1 x 2 ⋯ x n ] = [ x 11 x 12 ⋯ x 1 n x 21 x 22 ⋯ x 2 n ⋮ ⋮ ⋮ x m 1 x m 2 ⋯ x m n ] X = \left[ \begin{array} { l l l l } { x _ { 1 } } & { x _ { 2 } } & { \cdots } & { x _ { n } } \end{array} \right] = \left[ \begin{array} { c c c c } { x _ { 11 } } & { x _ { 12 } } & { \cdots } & { x _ { 1 n } } \\\\ { x _ { 21 } } & { x _ { 22 } } & { \cdots } & { x _ { 2 n } } \\\\ { \vdots } & { \vdots } & { } & { \vdots } \\\\ { x _ { m 1 } } & { x _ { m 2 } } & { \cdots } & { x _ { m n } } \end{array} \right] X=[x1x2⋯xn]=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋯x1nx2n⋮xmn⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
其中 x j = ( x 1 j , x 2 j , ⋯ , x m j ) T x _ { j } = ( x _ { 1 j } , x _ { 2 j } , \cdots , x _ { m j } ) ^ { T } xj=(x1j,x2j,⋯,xmj)T是 x x x的第 j j j个独立观测样本, j = 1 , 2 , … , n j=1,2,…,n j=1,2,…,n。
X X X的样本协方差矩阵
S = [ s i j ] m × m , s i j = 1 n − 1 ∑ k = 1 n ( x i k − x ‾ i ) ( x j k − x ‾ j ) i = 1 , 2 , ⋯ , m , j = 1 , 2 , ⋯ , m \left. \begin{array} { c } { S = [ s _ { i j } ] _ { m \times m } , \quad s _ { i j } = \frac { 1 } { n - 1 } \sum _ { k = 1 } ^ { n } ( x _ { i k } - \overline { x } _ { i } ) ( x _ { j k } - \overline { x } _ { j } ) } \\\\ { i = 1,2 , \cdots , m , \quad j = 1,2 , \cdots , m } \end{array} \right. S=[sij]m×m,sij=n−11∑k=1n(xik−xi)(xjk−xj)i=1,2,⋯,m,j=1,2,⋯,m
给定样本数据矩阵 X X X,考虑向量 x x x到 y y y的线性变换 y = A T x y = A ^ { T } x y=ATx
这里
A = [ a 1 a 2 ⋯ a m ] = [ a 11 a 12 ⋯ a 1 m a 21 a 22 ⋯ a 2 m ⋮ ⋮ ⋮ a m 1 a m 2 ⋯ a m m ] A = \left[ \begin{array} { l l l l } { a _ { 1 } } & { a _ { 2 } } & { \cdots } & { a _ { m } } \end{array} \right] = \left[ \begin{array} { c c c c } { a _ { 11 } } & { a _ { 12 } } & { \cdots } & { a _ { 1 m } } \\\\ { a _ { 21 } } & { a _ { 22 } } & { \cdots } & { a _ { 2 m } } \\\\ { \vdots } & { \vdots } & { } & { \vdots } \\\\ { a _ { m 1 } } & { a _ { m 2 } } & { \cdots } & { a _ { m m } } \end{array} \right] A=[a1a2⋯am]=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡a11a21⋮am1a12a22⋮am2⋯⋯⋯a1ma2m⋮amm⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
如果该线性变换满足以下条件,则称之为样本主成分。样本第一主成分 y 1 = a 1 T x y _ { 1 } = a _ { 1 } ^ { T } x y1=a1Tx是在 a 1 T a 1 = 1 a _ { 1 } ^ { T } a _ { 1 } = 1 a1Ta1=1条件下
使得 a 1 T x j ( j = 1 , 2 , ⋯ , n ) a _ { 1 } ^ { T } x _ { j } ( j = 1,2 , \cdots , n ) a1Txj(j=1,2,⋯,n)的样本方差 a 1 T S a 1 a _ { 1 } ^ { T } S a _ { 1 } a1TSa1最大的 x x x的线性变换
样本第二主成分 y 2 = a 2 T x y _ { 2 } = a _ { 2 } ^ { T } x y2=a2Tx
是在 a 2 T a 2 = 1 a _ { 2 } ^ { T } a _ { 2 } = 1 a2Ta2=1和 a 2 T x j a _ { 2 } ^ { T } x _ { j } a2Txj与 a 1 T x j ( j = 1 , 2 , ⋯ , n ) a _ { 1 } ^ { T } x _ { j } ( j = 1,2 , \cdots , n ) a1Txj(j=1,2,⋯,n)的样本协方差
a 1 T S a 2 = 0 a _ { 1 } ^ { T } S a _ { 2 } = 0 a1TSa2=0条件下
使得 a 2 T x j ( j = 1 , 2 , ⋯ , n ) a _ { 2 } ^ { T } x _ { j } ( j = 1,2 , \cdots , n ) a2Txj(j=1,2,⋯,n)的样本方差 a 2 T S a 2 a _ { 2 } ^ { T } S a _ { 2 } a2TSa2最大的 x x x的线性变换
一般地,样本第 i i i主成分 y i = a i T x y _ { i } = a _ { i } ^ { T } x yi=aiTx是在 a i T a i = 1 a _ { i } ^ { T } a _ { i } = 1 aiTai=1和 a i T x j a _ { i } ^ { T } x _ { j } aiTxj与 a k T x j ( k < i , j = 1 , 2 , ⋯ , n ) a _ { k } ^ { T } x _ { j } ( k < i , j = 1,2 , \cdots , n ) akTxj(k<i,j=1,2,⋯,n)的样本协方差
a k T S a i = 0 a _ { k } ^ { T } S a _ { i } = 0 akTSai=0条件下
使得 a i T x j ( j = 1 , 2 , ⋯ , n ) a _ { i } ^ { T } x _ { j } ( j = 1,2 , \cdots , n ) aiTxj(j=1,2,⋯,n)的样本方差 a k T S a i a _ { k } ^ { T } S a _ { i } akTSai最大的 x x x的线性变换
主成分分析方法主要有两种,可以通过相关矩阵的特征值分解或样本矩阵的奇异值分解进行
相关矩阵的特征值分解算法
针对 m × n m \times n m×n样本矩阵 X X X,求样本相关矩阵
R = 1 n − 1 X X T R = \frac { 1 } { n - 1 } X X ^ { T } R=n−11XXT
再求样本相关矩阵的 k k k个特征值和对应的单位特征向量,构造正交矩阵
V = ( v 1 , v 2 , ⋯ , v k ) V = ( v _ { 1 } , v _ { 2 } , \cdots , v _ { k } ) V=(v1,v2,⋯,vk)
V V V的每一列对应一个主成分,得到 k × n k \times n k×n样本主成分矩阵
Y = V T X Y = V ^ { T } X Y=VTX
矩阵 X X X的奇异值分解算法
针对 m × n m \times n m×n样本矩阵 X X X
X ′ = 1 n − 1 X T X ^ { \prime } = \frac { 1 } { \sqrt { n - 1 } } X ^ { T } X′=n−11XT
对矩阵 X ′ X ^ { \prime } X′进行截断奇异值分解,保留 k k k个奇异值、奇异向量,得到
X ′ = U S V T X ^ { \prime } = U S V ^ { T } X′=USVT
V V V的每一列对应一个主成分,得到 k × n k \times n k×n样本主成分矩阵 Y Y Y
Y = V T X Y = V ^ { T } X Y=VTX
PCA(principal components analysis)即主成分分析技术旨在利用降维的思想,把多指标转化为少数几个综合指标。
PCA的算法相当简单。 在确保数据被归一化之后,输出仅仅是原始数据的协方差矩阵的奇异值分解。
现在我们有主成分(矩阵U),我们可以用这些来将原始数据投影到一个较低维的空间中
对于这个任务,我们将实现一个计算投影并且仅选择顶部K个分量的函数,有效地减少了维数
我们也可以通过反向转换步骤来恢复原始数据。
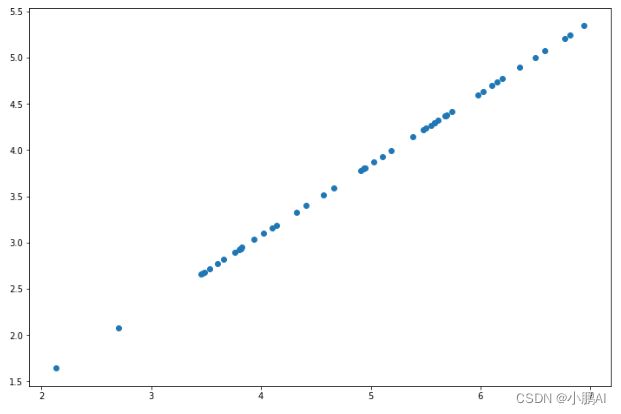
第一主成分的投影轴基本上是数据集中的对角线
当我们将数据减少到一个维度时,我们失去了该对角线周围的变化,所以在我们的再现中,一切都沿着该对角线
代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
X = data['X']
def pca(X):
# normalize the features
X = (X - X.mean()) / X.std()
# compute the covariance matrix
X = np.matrix(X)
cov = (X.T * X) / X.shape[0]
# perform SVD
U, S, V = np.linalg.svd(cov)
return U, S, V
def project_data(X, U, k):
U_reduced = U[:,:k]
return np.dot(X, U_reduced)
def recover_data(Z, U, k):
U_reduced = U[:,:k]
return np.dot(Z, U_reduced.T)
U, S, V = pca(X)
Z = project_data(X, U, 1)
X_recovered = recover_data(Z, U, 1)
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(list(X_recovered[:, 0]), list(X_recovered[:, 1]))
plt.show()