基于proteus的一个流水线CPU
基于proteus的一个流水线CPU
-
- 指令集与CPU架构
- 指令流水线及取指(F)阶段
- 译码(D)阶段及“暂停”(stalling)机制
-
- 暂停(stalling)机制
- 译码(D)段数据通路
- 执行(E)阶段及“气泡”(bubble)机制
-
- 运算器通路
- IO端口通路
- 数据存储器和立即数通路
- 指令跳转通路
- 气泡(bubble)机制
- 写回(W)阶段及“旁路”(pass)机制
-
- 写回(W)段数据通路
- 旁路(pass)机制
- 中断处理过程及“延迟”(delay)机制
- 流水线相关
-
- 数据相关
- 参考资料
指令集与CPU架构
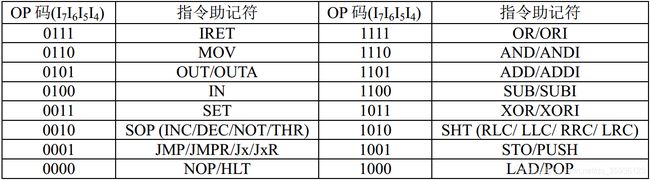
本文设计了一个四级流水线架构的CPU,在流水线满载的情况下,一个时钟周期可以完成一条机器指令。该CPU的指令集完全兼容博客基于proteus的一个微程序CPU和基于proteus的一个硬布线CPU中的CPU指令集,分为以下五大类共38条机器指令,指令OP码如下表1所示:
1)系统指令:NOP、HLT、IRET;
2)寄存器及I/O操作指令:MOV、SET、IN、OUT/OUTA;
3)存储器及堆栈操作指令:LAD/POP、STO/PUSH;
4)跳转系列指令:JMP、JMPR、Jx(JC/JZ/JS)、JxR(JCR/JZR/JSR);
5)算术逻辑运算指令:SHT (RLC/ LLC/ RRC/ LRC)、SOP (INC/DEC/NOT/THR)、ADD/ADDI、SUB/SUBI、AND/ANDI、OR/ORI、XOR/XORI;
表1. 流水线CPU指令集
通过分析可知,上述表1中的指令执行过程部分或全部包含了以下四个相互独立的阶段:
1)取指(Fetch):指令从程序存储器打入指令寄存器IR,且PC+1,指向下一条指令地址。
2)译码(Decode):主要功能是取数(取出指令所需操作数),并且把取出的操作数打入运算器的缓存器DA/DB。根据所取的操作数来源,不同指令在该阶段的取数操作还可以分为从通用寄存器堆Rx取数和从程序存储器(指令第二字节)取立即数或地址。
3)执行(Execute):主要功能是处理译码阶段取到的数据,包括以下操作:执行算术/逻辑运算,通过IO接口与外围设备交换数据;或是刷新程序计数器PC,实现程序跳转;或者把地址打入数据存储器ROM/RAM的地址寄存器AR,在下一阶段再读写数据存储器。
4)写回(Writeback):把上述执行阶段结果写回通用寄存器堆Rx或数据存储器RAM。
前述博客中的微程序CPU和硬布线CPU基于单总线架构,在一个CPU周期中只能执行一条指令中一个阶段的操作,一条指令的执行过程需要多个CPU周期,效率较低。而流水线版CPU架构的不同之处则是采用多总线架构,把上述四个阶段组合成四级流水线。指令依次顺序遍历四个阶段(没有操作的阶段直接通过),四条相邻的指令在四个阶段同时执行,如下图1所示。当流水线满载后(即图中第4个CPU周期以后),每一个CPU周期就输出一条指令的执行结果,效率得到极大提升。
图1. 流水线CPU的指令周期

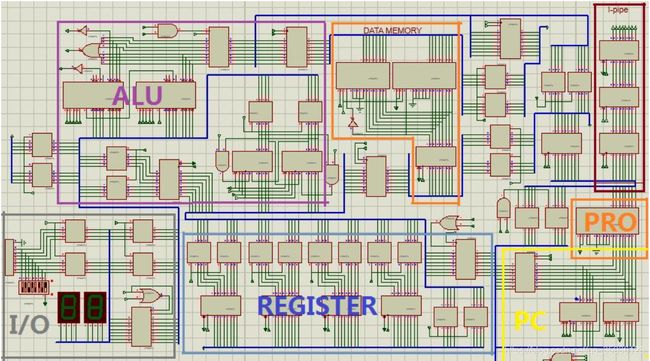
流水线CPU的电路如下图2所示,每个阶段的硬布线逻辑电路都相当于一个小型的硬布线CPU,相互独立,依次衔接。图中红色方框标注的D区、E区、W区就是译码、执行和写回阶段各自的硬布线逻辑(取指阶段较简单,没有独立硬布线逻辑),红线左侧是数据通路,包括数据存储器DATA MEMORY,程序存储器PRO,指令流水线通路I-pipe,外设电路I/O,通用寄存器REGISTER,运算器ALU,程序计数器PC和运算结果标志位寄存器PSW。红线下方是中断电路(INT)及其他辅助电路。
图2. 流水线CPU电路图

流水线版CPU的数据通路如下图3所示,其中指令和数据的路径互相独立:指令在取指(F)阶段从程序存储器PRO取出后,进入指令流水线I-pipe;而该指令对应的数据则在数据通路其余部分组成的数据流水线运行。为了适应指令流水线CPU的指令周期的需要(参见上述图1),数据流水线没有统一的总线,而是分为译码(D)、执行(E)和写回(W)段电路,各段电路内部有独立的寄存器和总线。当一条指令进入指令流水线中的某个阶段,其相关数据将保存在数据流水线中该段寄存器内,并且通过段内总线传输到下一阶段电路。指令的上述执行过程可以在寄存器传输级(Register Transfer Level, RTL)层次进行抽象描述。
图3. 流水线CPU的数据通路
流水线CPU的数据通路RTL描述如下图4所示:图左侧是指令流水线I-pipe由三个级联的指令寄存器D_IR、E_IR和W_IR构成,分别对应图右侧数据流水线的译码(D)、执行(E)和写回(W)段。数据流水线各段由不同的寄存器(实线框)组成,相邻段的寄存器通过指定的段内总线(虚线框)互连。当指令沿着指令流水线依次推进(D_IR→E_IR→W_IR),指令相关的数据也在数据流水线各阶段同步推进:段内寄存器存储当前指令(即该段指令寄存器内的指令)的相关数据,由该段的当前指令译码形成的微操作信号完成对数据的处理,并且指定相应的段内总线把数据送往下一段寄存器。
图4. 数据通路的RTL描述

如上述图4所示:在每一个时钟周期的CLK上升沿,指令推进到指令流水线某段的指令寄存器x_IR,译码控制本段寄存器输出该指令的相关数据,经过组合逻辑(圆头连线)传输到对应的总线;在CLK下降沿,数据从总线打入下一个阶段的寄存器(箭头连线),与此同时,段内寄存器保存前一个阶段送来的数据,即下一条指令相关数据(注:寄存器BUS_REG和MEM_REG例外,是在W段周期的CLK上升沿保存下一条指令相关数据)。
根据上述图4可以列出所有CPU指令在数据通路各段的RTL操作,如下表2所示。其中大部分指令是单字节指令“i”,亦有带立即数IMM和指令地址ADDR的双字节指令“i+IMM”和“i+ADDR”。此外,部分指令在某些阶段没有任何操作,即 “空”。
表2. CPU指令的RTL操作列表
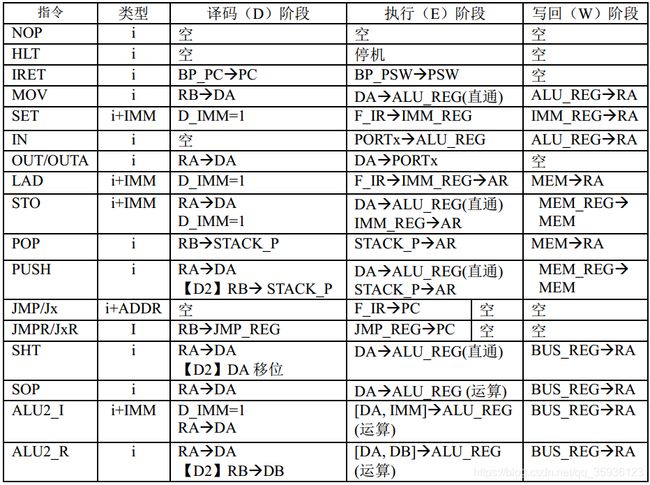
值得注意的是,在译码(D)段,“【D2】”表示该指令在D段插入了一个额外的CPU周期“D2段”,流水线的其它段在该特殊周期处于暂停状态,具体参见下述“译码(D)阶段及暂停(stalling)机制” 章节;在执行(E)段,如果有条件跳转系列指令Jx和JxR的跳转条件不成立(对应的运算器标志位CF/ZF/SF没有置位),则“空”(没有任何操作);如果跳转条件成立,则刷新程序计数器PC,实现程序跳转。
上述表2中用MEM标志统一表示数据存储器ROM和RAM;此外,因为双操作数运算指令(ADD/SUB/AND/OR/XOR)操作基本相同,所以采用ALU2_I代表操作数之一是立即数的双操作数运算指令,ALU2_R则代表操作数全部来源寄存器的双操作数运算指令。
上述表2中所列的所有RTL操作都是由上述流水线CPU电路图2中标注“D区”、“E区”、“W区”的红色方框内的硬布线逻辑生成的微操作信号来执行,以下详细说明流水线各个阶段的具体执行过程。
指令流水线及取指(F)阶段
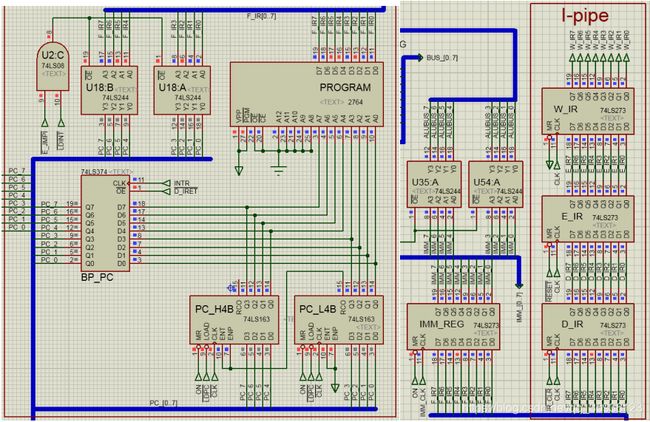
下图5所示是CPU的取指(F)阶段电路,其主要功能是取指:在每一个CPU周期的CLK下降沿时刻,程序计数器PC(即程序存储器地址寄存器)递增,程序存储器PROGRAM顺序输出当前指令,打入总线F_IR。在中断发生时,断点寄存器BP_PC保存PC当前值(即断点);在中断结束后,BP_PC负责将断点返回PC,保证主程序继续运行。此外,IRET及跳转系列指令还可以通过PC总线对程序计数器PC赋值。
在下图5中,除了程序存储器PROGRAM所挂的总线F_IR,流水线的译码(D)、执行(E)、写回(W)阶段都有相应的指令寄存器D_IR、E_IR、W_IR,上述四个“IR”共同构成指令流水线I-pipe(红色方框)。在CPU运行过程中,可以通过观察上述指令流水线的各阶段“IR”判断某条指令当前处于哪一个阶段(取指、译码、执行或是返回)。
图5. 取指(F)阶段电路和指令流水线通路
注意:与微程序CPU/硬布线CPU不同,流水线CPU的程序和数据存储器是两个独立的存储器。因此,在流水线版CPU指令集中,跳转系列指令的“ADDR”是程序存储器PROGRAM的地址,而存储器及堆栈操作指令(LAD/STO/POP/PUSH)的“ADDR”则是数据存储器ROM/RAM的地址,两者是完全不同的。除了IRET和跳转系列指令可以刷新程序计数器PC以外,任何指令都不能访问或修改程序存储器PROGRAM的内容。
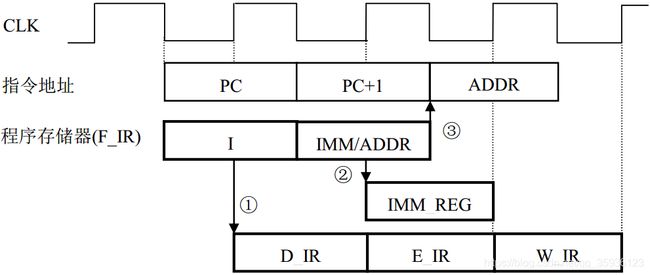
流水线CPU的指令流水线时序图如下图6所示:在CPU周期的CLK下降沿,PC刷新,存储器PROGRAM输出新PC地址对应的存储单元内容(指令)到F_IR总线。然后,在指令流水线I-pipe上指令依次推进(F_IR→D_IR→E_IR→W_IR),对应的D区、E区、W区硬布线逻辑生成各阶段所需的微操作信号。根据指令的差异,指令流水线时序可以分为下图6中的路径①~③,如下所述:
① 若F_IR总线上是单字节指令或双字节指令第一字节I,则在下一个CLK周期的上升沿打入D_IR寄存器,并且在后续CLK周期的上升沿依次打入E_IR和W_IR寄存器。
②若F_IR总线上是双字节指令的第二字节立即数,则当指令第一字节I从D_IR推进到E_IR时(CLK上升沿),第二字节立即数 IMM从总线F_IR同时输出到指令寄存器D_IR和立即数寄存器IMM_REG,信号#IR_CLR立刻清零D_IR。
③若F_IR总线上是双字节指令的第二字节地址,则当指令第一字节I推进到E_IR段的同时(CLK上升沿),第二字节地址ADDR同样输出到指令寄存器D_IR,信号#IR_CLR立刻清零D_IR。待到E_IR端的CLK下降沿,再把总线F_IR上的ADDR打入PC。
图6. 指令流水线时序图
译码(D)阶段及“暂停”(stalling)机制
暂停(stalling)机制
如上述CPU指令的RTL操作列表2所示,在D段,ALU2_R系列指令同时执行Rx→DA和Rx→DB;PUSH指令同时执行Rx→DA和Rx→STACK_P;SHT指令在DA暂存器中先执行Rx→DA,再DA移位。这三种指令与其他指令不同,在D段需要两个路径(CPU周期)。
然而,在指令流水线中,依次推进的指令在每个阶段只能经历一个CPU周期。若某条指令在D段需要占用两个CPU周期,将会堵塞后续指令进入流水线D段,引起混乱。因此,流水线版CPU需要采用一种暂停(stalling)机制:在这三种指令(统称为D2指令)推进到D段后,D段执行一个额外的CPU周期(其它各段在该周期全部暂停)。
暂停(stalling)机制的时序如下图7所示:一个CPU周期相当于一个CLK周期,默认D2_EN=0,系统时钟CLK=基准时钟TCLK,两者保持一致。当D2指令推进到译码(D)段,在执行完操作的CLK/TCLK下降沿,信号D2_EN=1译码生成,直到下一个TCLK下降沿后才恢复D2_EN=0。在D2_EN=1期间,系统时钟CLK被信号D2_EN的反向端强制CLK=0,而基准时钟TCLK不受影响。因此,在CLK=0的特殊CPU周期(称为D2段)内,指令流水线其它各段上的指令失去CLK时钟驱动,暂停一个CLK周期;而D段上的D2指令由TCLK时钟驱动,多执行了一次路径。
图7. 暂停(stalling)机制的时序图

译码(D)段数据通路
译码(D)段主要实现的功能是取数:指令在D_IR寄存器译码,从通用寄存器堆R0~R3取出本指令所需的操作数,存放到指定的目标寄存器。D段的数据通路如下图8所示。
从通用寄存器堆(R0/1/2/3)出发的路径如下所示:
1) RB→DA【D段】:MOV指令
2) RA→DA【D段】:OUT/OUTA、SOP、SHT、STO、PUSH、ALU2_R/ALU2_I系列指令
3) RB→DB【D2段】:ALU2_R系列指令
4) RB→JMP_REG【D段】:JMPR/JxR指令
5) RB→STACK_P【D段】:POP指令
6) RB→STACK_P【D2段】:PUSH指令
7) DA移位【D2段】:SHT指令
除了上述从通用寄存器堆Rx出发的路径,译码(D)段还有以下两个特殊路径:
8) D_IMM=1:SET、LAD、STO、ALU2_I系列指令
9) BP_PC→PC:IRET指令
注意:路径“D_IMM=1”在D段没有实际操作,只是置位标志信号D_IMM,等待相关的指令到执行(E)段开始的CLK上升沿再对IMM_REG寄存器操作;而路径“BP_PC→PC”则在后续的“中断处理过程”环节集中讨论。
图8. 译码(D)段的数据通路
执行(E)阶段及“气泡”(bubble)机制
如上述CPU指令的RTL操作列表2所示,指令推进到执行(E)段,可以分为五个数据通路:
1) 运算器通路:DA→ALU_REG(直通)或DA→ALU_REG (单操作数运算);
或 [DA, IMM]/[DA, DB]→ALU_REG(双操作数运算)
2) IO端口通路:DA→PORTx【输出】或PORTx→ALU_REG(直通)【输入】
3) 数据存储器通路:IMM_REG→AR或STACK_P→AR
4) 立即数通路:IMM_REG→ALU_REG(直通)
5) 指令跳转通路:F_IR→PC或JMP_REG→PC
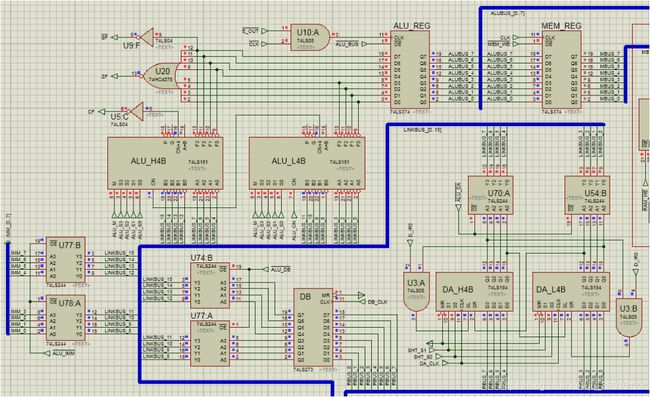
运算器通路
运算器通路如下图9所示,其主要功能是从总线LINKBUS提供一个或两个8位操作数(来源于ALU暂存器DA/DB或外围设备),通过运算器74LS181(执行运算或直通)输出到目标寄存器ALU_REG (或直接输出到外围设备),最后寄存器ALU_REG和IMM_REG二选一输出数据到总线ALU_BUS。
在执行(E)段开始的CLK上升沿,根据指令判断总线LINKBUS_[0…7]的数据来源:
● 非IN指令:#ALU_DA=0,则DA→ LINKBUS_ [0…7];【默认状态】
● IN指令:#ALU_PORT=0,则PORTx→ LINKBUS_ [0…7];
然后,根据指令判断总线LINKBUS_[0…7]上的数据打入的目标:
● 非OUT指令:#E_OUT=1,则LINKBUS_[0…7]→ALU_REG;【默认状态】
● OUT指令:#E_OUT=0,则LINKBUS_[0…7]→IOBUS_[0…7];
同样的,根据指令判断总线LINKBUS_[8…15]的数据来源:
● 非ALU2_R系列指令:#ALU_IMM=0,则IMM_REG→LINKBUS_[8…15] 【默认状态】
● ALU2_R系列指令:#ALU_DB=0,则DB→LINKBUS_ [8…15]
在E段的CLK下降沿时刻,运算器74LS181输出结果到ALU_REG寄存器,其中SOP、ALU2_R系列及ALU2_I系列指令是执行运算,必须把运算结果标志位CF(溢出)、ZF(零)、SF(符号位)保存到标志位寄存器PSW。其他指令则是通过,不改变PSW寄存器。
最后,在E段的CLK下降沿时刻,根据指令判断从寄存器ALU_REG还是从寄存器IMM_REG输出数据到总线ALU_BUS:
● 非SET指令:#ALU_BUS=0,则ALU_REG →ALUBUS_[0…7];【默认状态】
● SET指令:#MM_BUS=0,则IMM_REG→ALUBUS_[0…7];
图9. 运算器 ALU 通路
IO端口通路
如下图10所示, IO端口通路主要功能是CPU选择外围设备及交互数据。值得注意的是,OUT/OUTA指令的I1位作为地址锁存信号ALE。若信号ALE=1,则CPU输出地址到外设(OUTA指令);若信号ALE=0,则CPU输出数据到外设(OUT指令)。
图10. IO 端口通路
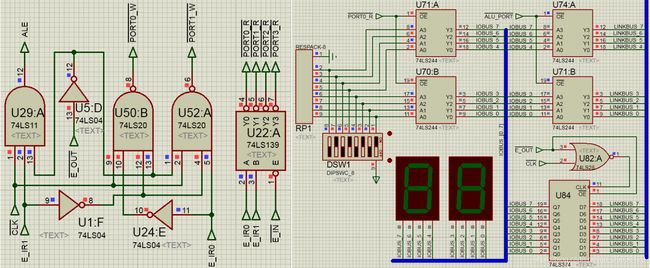
数据存储器和立即数通路
数据存储器通路和立即数通路如下图11所示:其主要功能分别是对数据存储器ROM/RAM的地址寄存器AR赋值。以及判断寄存器IMM_REG所保存立即数的打入目标。
在E段周期开始的CLK上升沿,根据指令判断地址寄存器AR的数据来源:
● LAD/STO指令(存储器操作):#AR_IMM=0,则IMM_REG→AR;【默认状态】
● POP/PUSH指令(堆栈操作):#AR_STACK=0,则STACK_P→AR;
同样,根据指令判断寄存器IMM_REG保存的立即数IMM的打入目标:
● ALU2_I系列指令:#ALU_IMM=0,则IMM_REG→LINKBUS_[8…15](参考运算器通路);
● LAD/STO指令:#AR_IMM=0,则IMM_REG→AR;
● SET指令:#IMM_BUS=0,则IMM_REG→ALUBUS_[0…7](参考运算器通路);
在E段周期的CLK下降沿时刻,信号AR_CLK的上升沿把待访问的数据存储器单元地址打入AR寄存器,即可以在W段访问相应单元。数据存储器地址空间分配如下:只读存储器ROM地址00-7FH;可读写存储器RAM地址80-FFH(唯有该地址允许写入数据)。
图11. 数据存储器通路和立即数通路

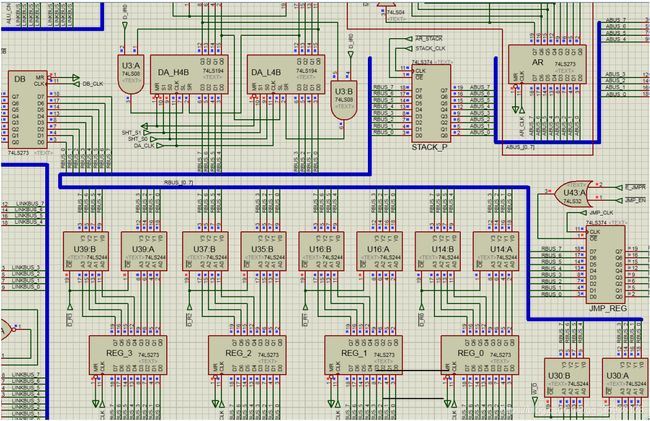
指令跳转通路
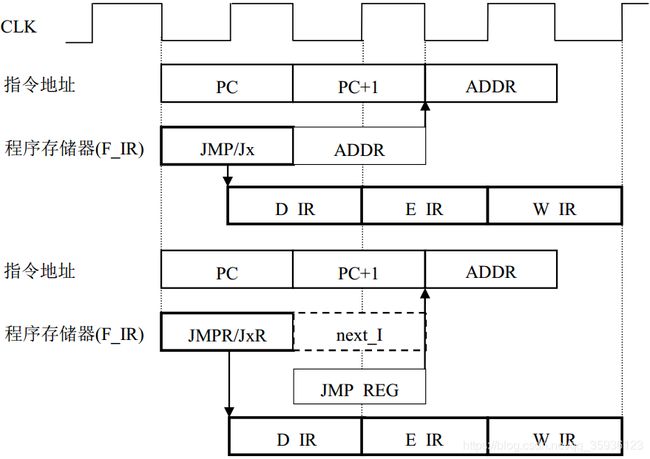
跳转系列指令的时序图如下图12所示:
图12. 跳转系列指令的时序图
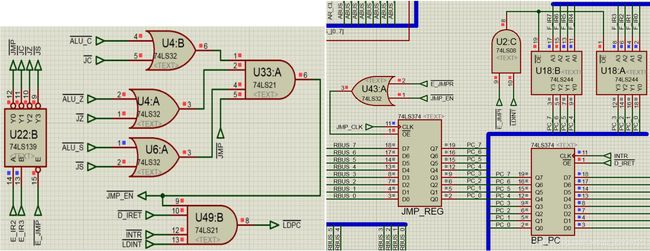
跳转通路如下图13(右)所示。根据跳转的目标地址来源,可以分为以下两个路径:
1)JMP/Jx指令:程序存储器(F_IR)输出指令第二字节ADDR。在E_IR周期的CLK上升沿时刻,#E_JMPI=0使F_IR连接PC总线。若跳转,则#LDPC=0在CLK下降沿从PC总线加载PC。
2)JMPR/JxR指令:目标地址在D段CLK下降沿(即JMP_CLK上升沿)打入JMP_REG。在E_IR周期开始的CLK上升沿,若#E_JMPR=0且#JMP_EN=0(即程序跳转),则清除跳转指令的后续指令next_I,同时JMP_REG输出目标地址ADDR到PC总线,然后,#LDPC=0在CLK下降沿从PC总线加载PC。若不跳转(#JMP_EN=1),JMP_REG不输出。
上述指令跳转路径的硬布线逻辑则如下图13(左)所示:指令信号JMP与E_IR寄存器的{I3,I2}位结合,得到无条件跳转指令信号JMP以及三种有条件跳转指令信号JC、JZ和JS。除了无条件跳转JMP指令会直接令信号#JMP_EN=0以外,其他三种有条件跳转指令信号JC、JZ和JS必须在对应的运算器的溢出标志CF、零标志ZF、符号位标志SF有效的情况下,才能触发#JMP_EN=0,进而使得程序计数器PC的加载端#LDPC=0有效。
图13. 指令跳转通路及其硬布线逻辑
气泡(bubble)机制
在E段放入以下三种情形必须使能信号#IR_CLR=0,令D_IR寄存器清零,即把D段的后续下一条指令变成NOP指令,称为气泡(bubble)机制。其时序图如下图14所示:
1)双字节指令(IMM_CLK=1):双字节指令第一字节Id后续跟着是第二字节立即数IMM,IMM不能进入D_IR译码,否则会产生错误。
2)JMP/Jx系列指令(#E_JMPI=0):无论是否跳转,指令第二字节ADDR都不能进入D_IR译码,否则程序错误。若跳转,则ADDR后续指令变成目标地址IJMP(IJMP =[ADDR])。
3)JMPR/JxR系列指令(#JMP_EN=0):若跳转,JMPR/JxR指令后续的I2指令必须清除(程序转向),I2后续指令变成目标地址IJMPR(IJMPR =[Rx])。若没有跳转,则无须清除。
除了以上三种情形,还有两种特殊情形会触发“气泡”机制:
4)系统上电(ON=0):在复位按钮重启之前,禁止任何数据进入D_IR。
5)中断处理过程(#INTR=0):在稍后“中断处理过程”环节集中讨论。
图14. 气泡(bubble)机制的时序图

写回(W)阶段及“旁路”(pass)机制
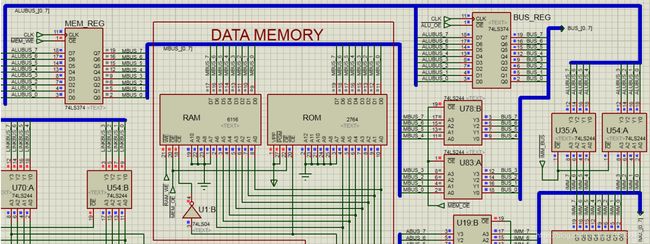
写回(W)段数据通路
W段数据通路主要功能是把执行结果写回数据存储器或通用寄存器,如下图15所示。当指令推进到W_IR寄存器,在CPU周期开始的CLK上升沿,ALUBUS总线上的数据同时打入BUS_REG寄存器和MEM_REG寄存器。根据不同的指令,W段再选择执行相应的数据流:
● 若是LAD/POP指令(#MEM_OE=0):则ROM→BUS,即数据存储器输出。
● 若是STO/PUSH指令(#MEM_WE=0):则MEM_REG→RAM,即数据存储器写入。
● 若是非存储器操作指令(#ALU_OE=0),则BUS_REG→BUS。
图15. 写回(W)段的数据通路
旁路(pass)机制
如上述CPU指令的RTL操作列表2所示,流水线的D段和W段的CLK下降沿都有可能涉及对通用寄存器Rx的操作。如下图16所示,指令“IN R0, PORT0”在W段的CLK下降沿要把PORT0端口的数据打入R0;同时,后续第二条指令“MOV R1, R0”在同一个下降沿又要把数据从R0打入暂存器DA。因为同时发生两个边沿触发事件(如下图16中的红色方框所示),器件延迟有可能导致R0先打入DA才被PORT0刷新,引起程序逻辑错误。
图16. 旁路(pass)机制的时序图

因此,流水线CPU采用旁路(bypass)机制来解决上述问题:如下图17所示,直通信号#W_D=0令244缓冲器U30:A和U30:B导通,从而使W段的BUS总线旁路直接连到D段的RBUS总线。在该段周期中间的CLK下降沿,总线BUS上的数据既写回通用寄存器Rx,又作为该寄存器Rx的替代数据源,输出操作数到RBUS总线,避免了D段和W段在CLK下降沿同时打入操作而引发的时序逻辑冲突。
图17. 旁路(bypass)机制的数据通路

中断处理过程及“延迟”(delay)机制
流水线CPU的中断机制与微程序/硬布线CPU保存一致,如下图18所示:采用单级中断机制,不允许中断嵌套,采用中断向量表保存中断向量Vector(中断子程序入口地址)。中断发生时,CPU通过中断向量表二次寻址跳转到中断子程序执行。
图18. 中断向量表
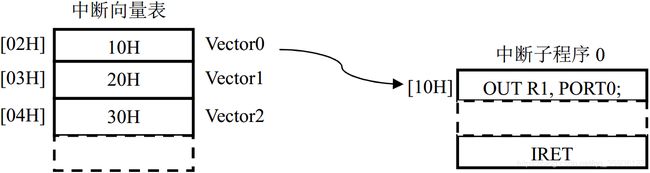
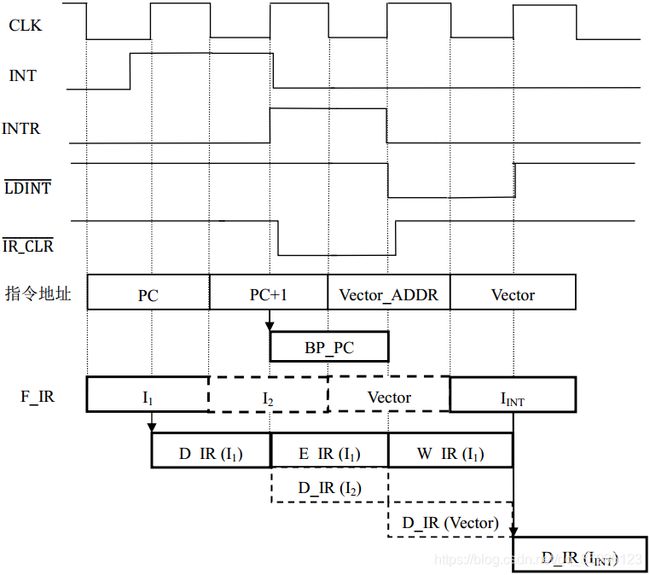
在中断响应过程中,CPU需要跳转到中断子程序入口,同时保存PC和PSW断点。本文的设计是当流水线CPU发生中断时,已经进入流水线的指令必须全部执行完成,CPU才能跳转和保存断点。如果刚进入流水线的指令是单字节跳转指令或双字节指令的第一字节,则还会出现中断延迟情况(详见后续“延迟机制”内容)。下图19所示是没有延迟的中断响应过程时序图:中断发生时刻(INT=1),在F段(F_IR总线)的指令I1必须执行完毕,才能跳转到中断处理程序入口。而I1相邻的下一条指令I2的地址(PC+1)则保存断点寄存器,待中断返回的时候主程序从I2继续执行。
图19. (非延迟)的中断响应过程时序图
在上述(非中断延迟)时序图19所示的中断响应过程中,若刚进入流水线的F段指令I1是双字节指令第一字节,则紧随其后的指令I2是双字节指令第二字节IMM/ADDR,被当作断点打入BP_PC。但是,当中断返回的时候,BP_PC弹回的数据IMM/ADDR,却被当作指令推进到D_IR→E_IR→W_IR执行,这将引起严重错误。
此外,若刚进入流水线的F段指令I1是单字节跳转指令JxR,则紧随其后的指令I2被当作“断点”打入BP_PC。但是, JMPR/JxR指令推进到E段才能做出判断究竟跳转还是不跳转。只有在不跳转的情况下,才会顺序执行后续下一条指令。如果跳转,应该跳转到寄存器JMP_REG所保存的地址。所以,直接把JMPR/JxR指令的后续下一条指令作为断点,只符合JMPR/JxR指令不跳转的情况,当JMPR/JxR指令发生跳转的时候,就会出现严重错误。
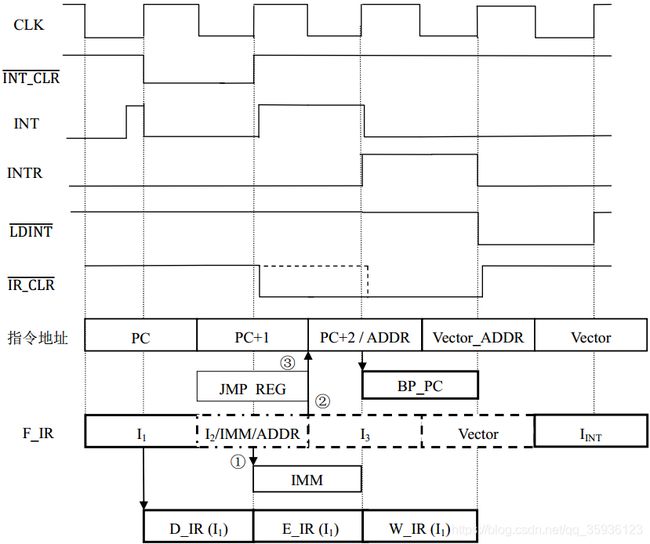
因此,流水线CPU采用了中断延迟机制来解决上述问题:根据指令I1的不同,中断响应时序可以分为下图20所示的路径①~③:
①指令I1是双字节非跳转指令,则INTR上升沿打入BP_PC的“断点”是地址PC+2;
②指令I1是双字节JMP/Jx指令:若跳转,则INTR上升沿打入BP_PC的断点是跳转目标地址ADDR;若不跳转,则打入BP_PC的断点还是地址PC+2;
③指令I1是单字节JMPR/JxR指令:
若跳转,则INTR上升沿打入BP_PC的断点是跳转目标地址ADDR。信号#IR_CLR是持续两个CLK周期低电平(如下图20中的实线所绘),根据前述气泡(bubble)机制把后续两条指令I2(PC+1对应的指令)和I3(PC+2对应的指令)都清除。
若不跳转,INTR上升沿打入BP_PC的断点是地址PC+2。信号#IR_CLR是持续一个CLK周期的低电平(如下图20中的虚线所绘)。根据前述气泡(bubble)机制把指令I3(PC+2对应的指令)清除,指令I1和I2都顺序经过流水线。
图20. 延迟(delay)机制的中断响应过程时序图
流水线相关
虽然指令集完全兼容前述博客的微程序/硬布线CPU,但是流水线CPU的最大不同之处是:流水线CPU的指令序列是重叠执行的,即一条指令进入流水线执行的时候,前面若干条指令还在流水线的不同阶段上,没有执行完毕。而非流水线CPU(微程序/硬布线CPU)是在上一条指令执行完毕后,才执行下一条指令,不存在重叠问题。因此,在流水线CPU中,需要考虑指令序列重叠执行过程中前后指令相互的影响,即流水线相关问题。
数据相关
在进入流水线重叠执行的过程中,后面的指令依赖于前面的指令执行结果(数据),但是前面的指令还没执行完所引起的相关。根据涉及的数据种类可以分为立即数IMM和通用寄存器Rx保存的数据。
如上述CPU指令的RTL操作列表2所示,带有立即数IMM的指令都是双字节指令,所以不可能有相邻段同时涉及立即数寄存器IMM_REG的操作,即立即数IMM不涉及数据相关。而通用寄存器Rx的数据则主要涉及D、E和W段的操作,大致可分为两种情况:
1) D段和W段对同一个通用寄存器Rx进行操作,该问题已经被W段的旁路(bypass)机制解决。
2) 相邻段(D段和E段、E段和W段)对同一个通用寄存器Rx进行操作,并且是前一条指令写入操作,后一条指令读出操作。即先写后读,如下图21所示: MOV指令从寄存器R0读出的数据应该是前一条指令IN从IO端口PORT0写入的数据。但是MOV指令在D段读出R0数据的同时,IN指令还在E段,数据尚未写入R0。MOV指令实际从R0读出的数据是IN指令之前的数据,产生严重错误。
因此,在先写后读相同寄存器Rx的相邻指令之间必须插入一个NOP指令,如下图21所示。可以证明最多只需要插入一个NOP指令即可使得相邻指令之间不再数据相关。但是,插入NOP指令会导致流水线有空闲的周期,效率有所下降。更合理的解决方案是通过编译器或人工调整程序的先后次序,消除以上所述流水线相关的情况。
图21. 流水线相邻指令的数据相关示例

参考资料
本文的内容节选自作者编撰的教材专著《基于Proteus的计算机系统实验教程——逻辑、组成原理、体系结构、微机接口》(机械工业出版社),更详细的内容可以直接在书中查阅。
读者如有兴趣,可以在 当当网图书, 京东图书,亚马逊上搜索作者姓名赖晓铮即可找到这本著作。
本书详细描述了在proteus虚拟仿真环境中,从逻辑电路开始,一步一步构造运算器、存储器、控制器,最终用三种CPU体系架构(微程序、硬布线、流水线)实现了一个8位的CPU。并且,这个CPU不仅可以做逻辑、算术运算,拥有循环、分支、堆栈等程序结构,还可以完整实现对8086所有外设的控制,即替代8086完整实现了传统《微机原理》里讲到的所有外设实验。
本书的全部proteus工程文件,PPT,实验视频以及配套的两种形式课程设计(纯汇编、硬件改动)的资料都放在 百度网盘,提取密码:34ad
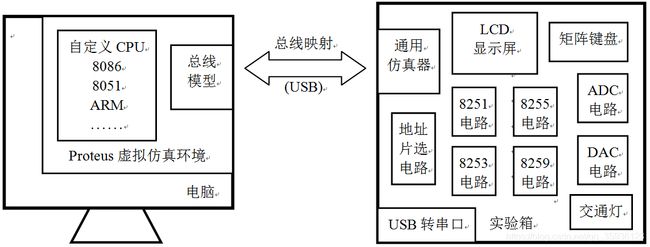
广州风标为本书配套了实验箱(如下图所示),可以让学生在电脑的proteus虚拟仿真环境中设计CPU或选择已有的8086、8051、ARM等CPU模型,然后通过虚拟总线映射到实验箱的物理总线,控制实验箱面板上的真实外设。有兴趣的读者可以自行联系 广州风标教育技术股份有限公司。