cuda编程------矩阵乘法
cuda + VS 2010 安装:http://www.cnblogs.com/xing901022/archive/2013/08/09/3248469.html
本文主要介绍如何使用CUDA并行计算矩阵乘法:
//头文件
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include __global__ void MatMulKernel(float* A, float* B, float* C,dim3 dimsA, dim3 dimsB)//[1]
{
// Each thread computes one element of C
// by accumulating results into Cvalue
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int e = 0; e < dimsA.y; ++e)
Cvalue += A[row * dimsA.y + e]* B[e * dimsB.y + col];
C[row * dimsB.y + col] = Cvalue;
}
void MatrixMultiplication_CUDA(const float* A,const float* B,float* C)
{
dim3 dimsA(4,3);// the size of matrix A which you have to modify
dim3 dimsB(3,3);// the size of matirx B which you have to modify
//copy memory from host to devices
unsigned int size_A = dimsA.x * dimsA.y;
unsigned int mem_size_A = sizeof(float) * size_A;
float *d_A ;
cudaMalloc(&d_A,mem_size_A);
cudaMemcpy(d_A,A,mem_size_A,cudaMemcpyHostToDevice);
float *d_B;
unsigned int size_B = dimsB.x * dimsB.y;
unsigned int mem_size_B = sizeof(float) * size_B;
cudaMalloc(&d_B,mem_size_B);
cudaMemcpy(d_B,B,mem_size_B,cudaMemcpyHostToDevice);
unsigned int mem_size_C = sizeof(float)* dimsA.x*dimsB.y;
float *d_C;
cudaMalloc(&d_C,mem_size_C);
//dimBlock represents the threads'size within block which you have to modify[2]
dim3 dimBlock(3,2);
dim3 dimGrid(dimsB.y/dimBlock.x,dimsA.x/dimBlock.y);//[3]
MatMulKernel<<>>(d_A, d_B, d_C, dimsA, dimsB);
// Read C from device memory
cudaMemcpy(C, d_C, mem_size_C,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
int main()
{
float A[] = {6,2,3,
8,3,5,
7,2,4,
8.3,2,5};
float B[] ={1,2,3,
4,5,6,
7,8,9};
float*C = new float[12];
MatrixMultiplication_CUDA(A,B,C);
for(int i =0;i<12;i++)
printf("%f ",C[i]);
getchar();
return 0;
} A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new
<<<...>>> execution configuration syntax
使用__global__声明的函数即是CUDA 的kernel函数,也就是需要并行计算的部分,线程数目则是调用时由<<<>>>指定。
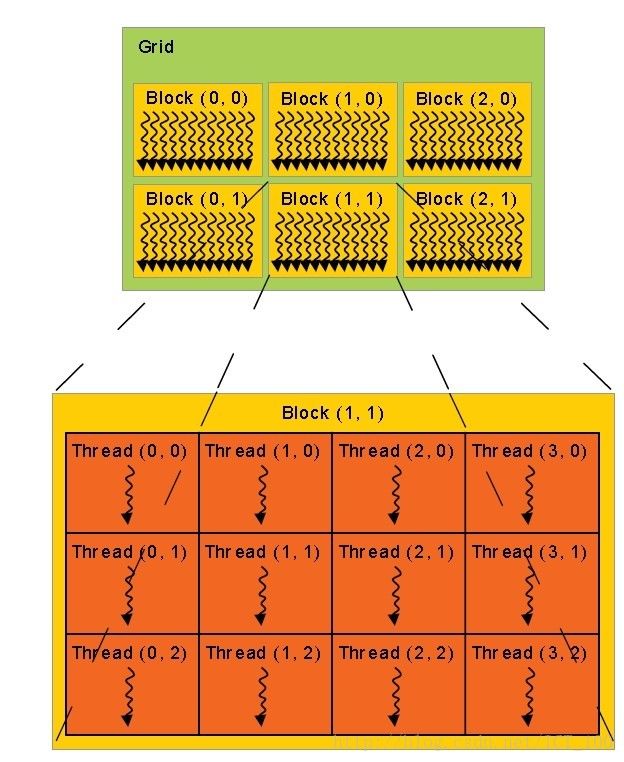
[2] dimBlock 指定的是一个block中的线程数目,dimGrid指定的是一个grid中block的数目。一个grid由多个block组成,一个block内有多个线程,block之间不能交互,但一个block里面的线程可以通过shared memory进行交互。 例如main函数中A.x = 4 我设置的dimBlock.y为2 ,2<4 [3]可能疑惑X,Y是否弄反了,看gpu里面排列表就知道了。纵列和我们的数组排列就是不一样。
这个可以自己指定,但必须满足条件 dimBlock.x< B.y dimBlock.y