我参加第七届NVIDIA Sky Hackathon——训练ASR模型
如何从0开始训练自己的ASR模型
第一步 获取NGC密钥
第二步 配置Ubuntu22.04的运行环境
第三步 开始训练ASR模型
文章目录
- 如何从0开始训练自己的ASR模型
- 前言
- 一、获取NGC密钥
- 二、配置Ubuntu22.04的运行环境
-
- 1.安装 NVIDIA 驱动 460 以上版本
- 2.安装 docker 与 nvidia-docker2
- 3.安装 MiniConda3 与 Jupyter 开发环境
- 4.安装 NeMo 1.4.0
- 5.安装 TAO 模型训练优化工具:用 Python 与 Virtualenv
- 三、开始训练ASR模型
-
- 1.制作数据集
- 2.对其进行训练
- 总结
前言
Sky Hackathon由NVIDIA发起并主办,项目旨在帮助在校学生、深度学习开发者在NVIDIA Jetson边缘高性能计算产品上部署和优化人工智能应用。在经验丰富的GPU导师指导下,通过黑客松竞赛的方式学习业界所需的深度学习相关应用开发及其并行计算技能,激发学生们的学习兴趣与创新力。
NVIDIA工程师将亲自为参赛队伍带来他们对最新的深度学习与边缘计算方面的理解、行业的趋势与最新的技术应用及最新开发工具实战技能知识,在训练营中对参赛队伍进行指导。
Sky Hackathon为参加者提供了一个难得的学习并实操的机会,学习嵌入式深度学习开发所需的动手技能, 通过使用NVIDIA最新的编程模型、库和工具以加速和优化他们的AI应用程序。
相关网站:第七届NVIDIA SKy Hackathon
一、获取NGC密钥
进入NGC网站:NVIDIA NGC
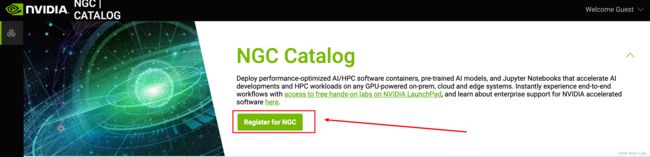
点击注册
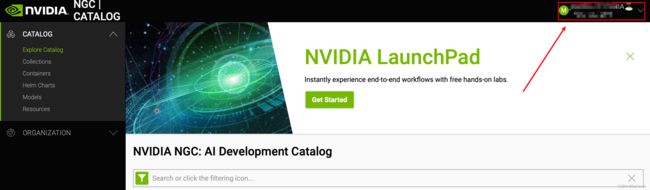
登陆之后点击右上角set up
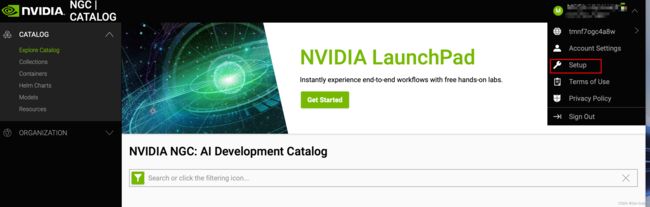
点击Get API Key
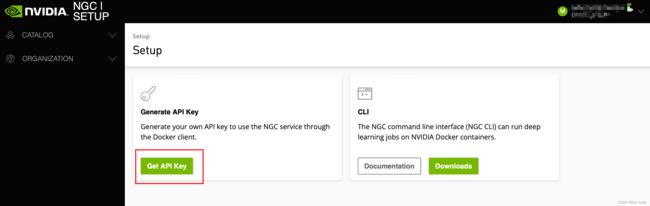
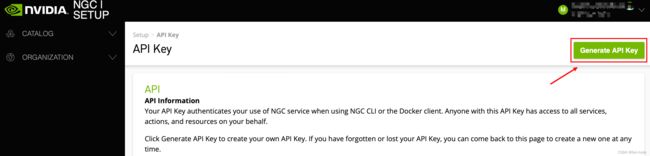
点击Generate API Key
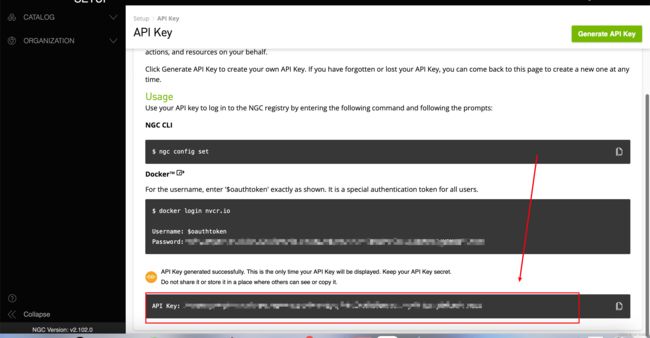
这里就是你的API Key了
二、配置Ubuntu22.04的运行环境
1.安装 NVIDIA 驱动 460 以上版本
代码如下:
sudo apt-get install software-properties-common
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get install nvidia-driver-460
sudo reboot # 重启之后才会生效,重启后执行 nvidia-smi 检查驱动
2.安装 docker 与 nvidia-docker2
代码如下(安装 docker):
sudo apt-get install -y ca-certificates curl gnupg lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/dockerarchive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs)stable" | ¥ $ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# 测试安装
sudo docker run hello-world
代码如下(安装 nvidia-docker2):
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
# 测试安装
sudo docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi
如果出现以下信息,表示 docker 与 nvidia-docker2 都安装完成

代码如下(登录 NGC:只要登录一次就行):
sudo docker login -u '$oauthtoken' --password-stdin nvcr.io <<< '申请的密钥'
3.安装 MiniConda3 与 Jupyter 开发环境
代码如下(安装 MiniConda):
# 用国内清华源
export DL_SITE=https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda # 用原厂的源
export DL_SITE=https://repo.anaconda.com/miniconda
# 下载安装包
wget -c $DL_SITE/Miniconda3-py38_4.10.3-Linux-x86_64.sh
# 执行安装,全部按照预设路径与”yes”选项
bash Miniconda3-py38_4.10.3-Linux-x86_64.sh
# 启动
Conda source ~/.bashrc
代码如下(安装 Jupyter Lab):
pip install jupyter jupyterlab # 设置登录密码
export PW=’你自己要设置的密码‘
python3 -c "from notebook.auth.security import set_password; set_password('$PW','$HOME/.jupyter/jupyter_notebook_config.json')"
4.安装 NeMo 1.4.0
通过 pip 安装 GPU 版本 Pytorch 参考链接 https://pytorch.org/get-started/previous-versions/
例如 Pytorch1.12.1 版本则安装指令如下:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-indexurl https://download.pytorch.org/whl/cu113
代码如下(安装 NeMo):
sudo apt-get update && sudo apt-get install -y libsndfile1 ffmpeg
pip install Cython
pip install --user pytest-runner
pip install rosa numpy==1.19.4
pip install torchmetrics==0.6.0
pip install nemo_toolkit[all]==1.4.0
pip install ASR-metrics
代码如下(检测NeMo):
python
import nemo
import nemo.collections.asr as nemo_asr
若没有报错表示安装成功(warning 不用理会)
5.安装 TAO 模型训练优化工具:用 Python 与 Virtualenv
代码如下(安装 virtualenv 虚拟环境:这是确保 TAO 有独立的 Python 执行环境,为配合 Nemo 工 具使用 Python 3.8 的 MiniConda 安装,因此这里的 virtualenv 也绑定在 MiniConda 的 Python3 上):
pip install virtualenv virtualenvwrapper
# 创建目录用来存放虚拟环境
mkdir $HOME/.virtualenvs
# 在~/.bashrc 中添加行:
export WORKON_HOME=$HOME/.virtualenvs export VIRTUALENVWRAPPER_PYTHON=$HOME/miniconda3/bin/python3
source $HOME/miniconda3/bin/virtualenvwrapper.sh
# 保存并退出
source ~/.bashrc
# 创建名为”tao”的 Virtualenv
mkvirtualenv tao -p $HOME/miniconda3/bin/python3
代码如下(安装 TAO 模型训练工具):
# 确认在 ”tao” 的 Virtualenv 环境下,如果不在的话就执行以下指令
workon tao
# 安装 nvidia-pyindex 与 nvidia-tao
pip3 install nvidia-pyindex
pip3 install nvidia-tao
# 检查安装
tao info
代码如下(启动 TAO 模型训练工具 Jupyter 交互界面):
# 启动名为 “tao” 的 virtualenv
workon tao
# 进入工作目录并启动 Jupyter Lab
cd ~/hackathon && jupyter lab --ip 0.0.0.0 --port 8888 --allow-root
输入您先前设置的密码就能进去,进入 Jupyter Lab 之后是以~/hackathon 为根目录
代码如下(启动Jupyter):
jupyter lab --ip 0.0.0.0 --port 8888 --allow-root
代码如下(进入Jupyter):
在ubuntu的终端输入ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp8s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether b4:a9:fc:6c:6b:5e brd ff:ff:ff:ff:ff:ff
3: wlp0s20f3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 40:ec:99:20:b5:61 brd ff:ff:ff:ff:ff:ff
inet 10.20.113.129/22 brd 10.20.115.255 scope global wlp0s20f3
valid_lft forever preferred_lft forever
inet 192.168.1.206/24 brd 192.168.1.255 scope global dynamic noprefixroute wlp0s20f3
valid_lft 79725sec preferred_lft 79725sec
inet6 2409:8a02:6068:880:4691:5ea5:dbf9:3151/64 scope global temporary dynamic
valid_lft 259087sec preferred_lft 79410sec
inet6 2409:8a02:6068:880:ff41:1037:c6e5:bd3b/64 scope global dynamic mngtmpaddr noprefixroute
valid_lft 259087sec preferred_lft 259087sec
inet6 fe80::f0ce:78ab:12c0:d59e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:10:5d:d6:56 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:10ff:fe5d:d656/64 scope link
valid_lft forever preferred_lft forever
22: vethd32e2b1@if21: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether f6:73:02:10:2c:98 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::f473:2ff:fe10:2c98/64 scope link
valid_lft forever preferred_lft forever
30: veth442d3b9@if29: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 1e:66:e8:63:24:11 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::1c66:e8ff:fe63:2411/64 scope link
valid_lft forever preferred_lft forever
34: veth7c78114@if33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 9a:a2:4d:ac:13:0a brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::98a2:4dff:feac:130a/64 scope link
valid_lft forever preferred_lft forever
我这里的ip是192.168.1.206
在浏览器里面输入
192.168.1.206:8888
就能进入Jupyter Lab了
三、开始训练ASR模型
1.制作数据集
数据集格式——json文件格式
{
"audio_filepath":"your_path",
"duration":time,
"text":"your_text"
}
利用librosa获取其语音
注意:音频为单声道,wav格式,采样率建议44100HZ
在这里插入代码片# 导入librosa音频工具包获取音频时长,用于制作语音数据集
import librosa
time = librosa.get_duration(filename="你音频的路径")
print(time)
最后数据集文件结构
├── Datasets
│├── audio.wav 所有的语音文件(wav单声道格式)
│├── xxx.json 制作好的json文件
2.对其进行训练
导入基本包
import nemo
nemo.__version__
import torch
torch.__version__
torch.cuda.is_available()
import nemo.collections.asr as nemo_asr
加载数据清单
#将制作好的json格式的数据清单加载进来
train_manifest = "your_path/xxx.json"
test_manifest = "your_path/xxx.json"
加载quartznet文件
# 使用YAML读取quartznet模型配置文件
try:
from ruamel.yaml import YAML
except ModuleNotFoundError:
from ruamel_yaml import YAML
config_path ="/root/config/quartznet_15x5_zh.yaml"
yaml = YAML(typ='safe')
with open(config_path) as f:
params = yaml.load(f)
print(params)
将数据清单传给配置文件
params['model']['train_ds']['manifest_filepath']=train_manifest
params['model']['validation_ds']['manifest_filepath']=test_manifest
使用迁移学习的方法训练模型
quartznet.setup_training_data(train_data_config=params['model']['train_ds'])
quartznet.setup_validation_data(val_data_config=params['model']['validation_ds'])
import pytorch_lightning as pl
trainer = pl.Trainer(gpus=1,max_epochs=200)
trainer.fit(quartznet)#调用‘fit’方法开始训练
保存训练好的模型
quartznet.save_to("7th_asr_model.nemo")# 将训练好的模型保存为.nemo格式
将训练好的模型进行重载
try_model_1 = nemo_asr.models.EncDecCTCModel.restore_from("7th_asr_model.nemo")#对模型进行重新加载
预测语音
asr_result = try_model_1.transcribe(paths2audio_files=["your_wav_path"])
print(asr_result)
计算其正确率
from ASR_metrics import utils as metrics
s1 = "请检测出纸箱果皮和瓶子"#指定正确答案
s2 = " ".join(asr_result)#识别结果
print("字错率:{}".format(metrics.calculate_cer(s1,s2)))#计算字错率cer
print("准确率:{}".format(1-metrics.calculate_cer(s1,s2)))#计算准确率accuracy
总结
以上就是第七届NVIDIA Sky Hackathon的配置环境和训练ASR模型的部分,在制作时要注意json文件的格式,还有音频的格式,这些细小的部分都可能成为bug的发生地